 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Dragon Hatchling: The Missing Link between the Transformer and Models of the Brain
Sep 30, 2025The relationship between computing systems and the brain has served as motivation for pioneering theoreticians since John von Neumann and Alan Turing. Uniform, scale-free biological networks, such as the brain, have powerful properties, including generalizing over time, which is the main barrier for Machine Learning on the path to Universal Reasoning Models. We introduce `Dragon Hatchling' (BDH), a new Large Language Model architecture based on a scale-free biologically inspired network of \$n\$ locally-interacting neuron particles. BDH couples strong theoretical foundations and inherent interpretability without sacrificing Transformer-like performance. BDH is a practical, performant state-of-the-art attention-based state space sequence learning architecture. In addition to being a graph model, BDH admits a GPU-friendly formulation. It exhibits Transformer-like scaling laws: empirically BDH rivals GPT2 performance on language and translation tasks, at the same number of parameters (10M to 1B), for the same training data. BDH can be represented as a brain model. The working memory of BDH during inference entirely relies on synaptic plasticity with Hebbian learning using spiking neurons. We confirm empirically that specific, individual synapses strengthen connection whenever BDH hears or reasons about a specific concept while processing language inputs. The neuron interaction network of BDH is a graph of high modularity with heavy-tailed degree distribution. The BDH model is biologically plausible, explaining one possible mechanism which human neurons could use to achieve speech. BDH is designed for interpretability. Activation vectors of BDH are sparse and positive. We demonstrate monosemanticity in BDH on language tasks. Interpretability of state, which goes beyond interpretability of neurons and model parameters, is an inherent feature of the BDH architecture.
Pathway: a fast and flexible unified stream data processing framework for analytical and Machine Learning applications
Jul 12, 2023



We present Pathway, a new unified data processing framework that can run workloads on both bounded and unbounded data streams. The framework was created with the original motivation of resolving challenges faced when analyzing and processing data from the physical economy, including streams of data generated by IoT and enterprise systems. These required rapid reaction while calling for the application of advanced computation paradigms (machinelearning-powered analytics, contextual analysis, and other elements of complex event processing). Pathway is equipped with a Table API tailored for Python and Python/SQL workflows, and is powered by a distributed incremental dataflow in Rust. We describe the system and present benchmarking results which demonstrate its capabilities in both batch and streaming contexts, where it is able to surpass state-of-the-art industry frameworks in both scenarios. We also discuss streaming use cases handled by Pathway which cannot be easily resolved with state-of-the-art industry frameworks, such as streaming iterative graph algorithms (PageRank, etc.).
Efficient Transformers with Dynamic Token Pooling
Nov 17, 2022Transformers achieve unrivalled performance in modelling language, but remain inefficient in terms of memory and time complexity. A possible remedy is to reduce the sequence length in the intermediate layers by pooling fixed-length segments of tokens. Nevertheless, natural units of meaning, such as words or phrases, display varying sizes. To address this mismatch, we equip language models with a dynamic-pooling mechanism, which predicts segment boundaries in an autoregressive fashion. We compare several methods to infer boundaries, including end-to-end learning through stochastic re-parameterisation, supervised learning (based on segmentations from subword tokenizers or spikes in conditional entropy), as well as linguistically motivated boundaries. We perform character-level evaluation on texts from multiple datasets and morphologically diverse languages. The results demonstrate that dynamic pooling, which jointly segments and models language, is often both faster and more accurate than vanilla Transformers and fixed-length pooling within the same computational budget.
Variable-rate hierarchical CPC leads to acoustic unit discovery in speech
Jun 07, 2022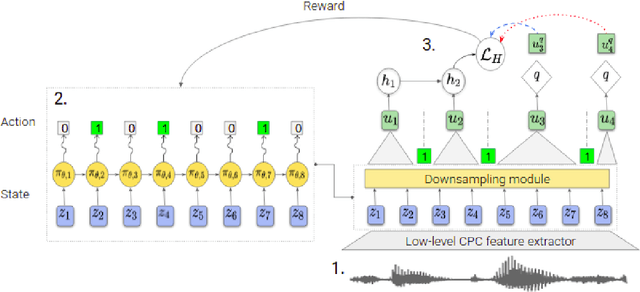
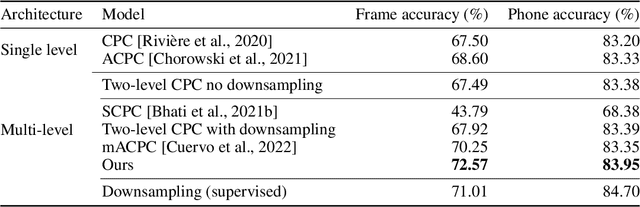

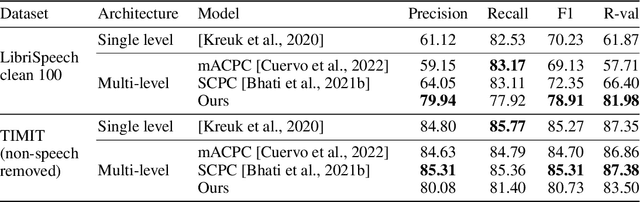
The success of deep learning comes from its ability to capture the hierarchical structure of data by learning high-level representations defined in terms of low-level ones. In this paper we explore self-supervised learning of hierarchical representations of speech by applying multiple levels of Contrastive Predictive Coding (CPC). We observe that simply stacking two CPC models does not yield significant improvements over single-level architectures. Inspired by the fact that speech is often described as a sequence of discrete units unevenly distributed in time, we propose a model in which the output of a low-level CPC module is non-uniformly downsampled to directly minimize the loss of a high-level CPC module. The latter is designed to also enforce a prior of separability and discreteness in its representations by enforcing dissimilarity of successive high-level representations through focused negative sampling, and by quantization of the prediction targets. Accounting for the structure of the speech signal improves upon single-level CPC features and enhances the disentanglement of the learned representations, as measured by downstream speech recognition tasks, while resulting in a meaningful segmentation of the signal that closely resembles phone boundaries.
Contrastive prediction strategies for unsupervised segmentation and categorization of phonemes and words
Oct 29, 2021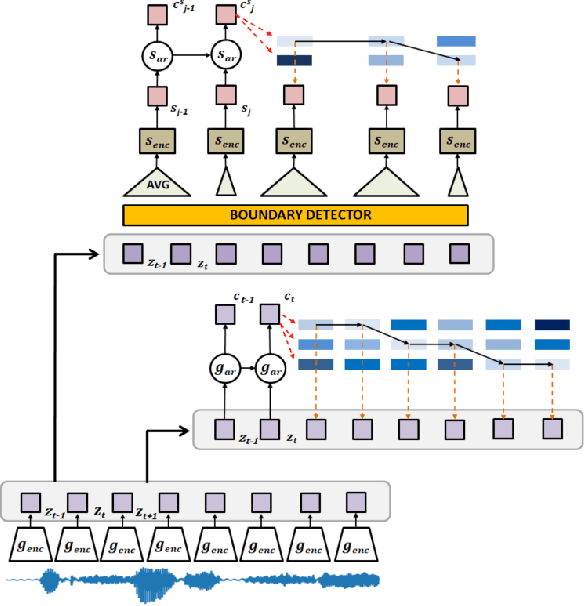
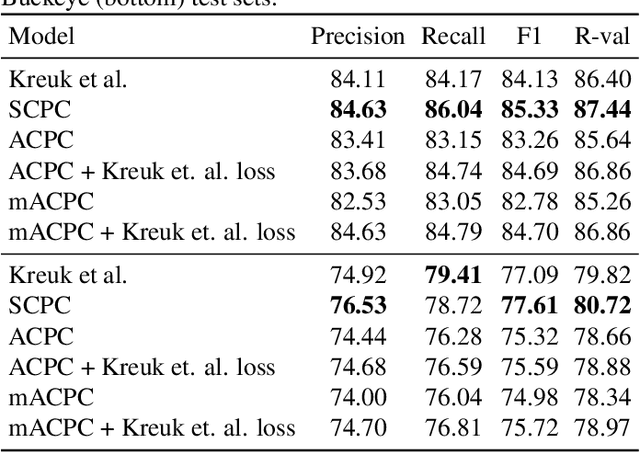
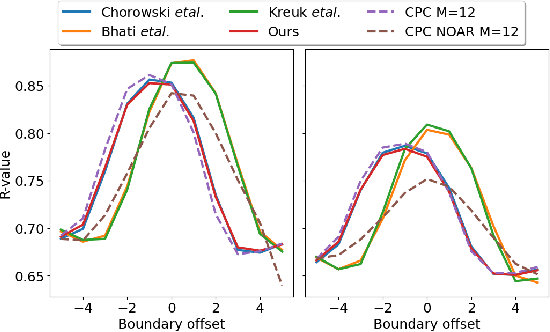
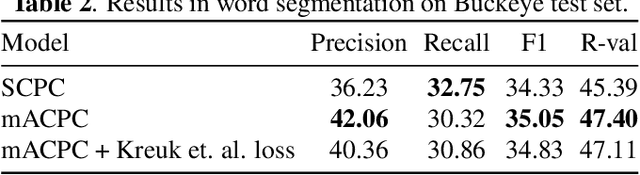
We investigate the performance on phoneme categorization and phoneme and word segmentation of several self-supervised learning (SSL) methods based on Contrastive Predictive Coding (CPC). Our experiments show that with the existing algorithms there is a trade off between categorization and segmentation performance. We investigate the source of this conflict and conclude that the use of context building networks, albeit necessary for superior performance on categorization tasks, harms segmentation performance by causing a temporal shift on the learned representations. Aiming to bridge this gap, we take inspiration from the leading approach on segmentation, which simultaneously models the speech signal at the frame and phoneme level, and incorporate multi-level modelling into Aligned CPC (ACPC), a variation of CPC which exhibits the best performance on categorization tasks. Our multi-level ACPC (mACPC) improves in all categorization metrics and achieves state-of-the-art performance in word segmentation.
Information Retrieval for ZeroSpeech 2021: The Submission by University of Wroclaw
Jun 22, 2021

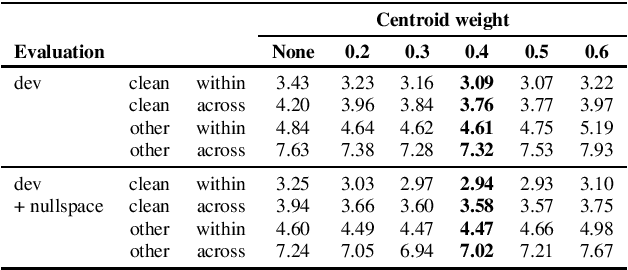
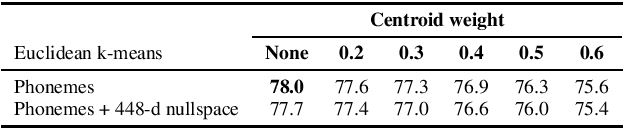
We present a number of low-resource approaches to the tasks of the Zero Resource Speech Challenge 2021. We build on the unsupervised representations of speech proposed by the organizers as a baseline, derived from CPC and clustered with the k-means algorithm. We demonstrate that simple methods of refining those representations can narrow the gap, or even improve upon the solutions which use a high computational budget. The results lead to the conclusion that the CPC-derived representations are still too noisy for training language models, but stable enough for simpler forms of pattern matching and retrieval.
Aligned Contrastive Predictive Coding
Apr 29, 2021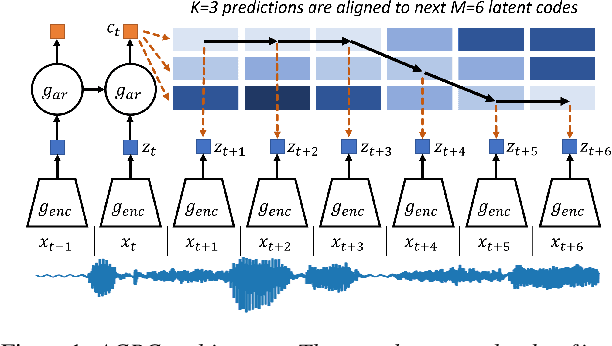

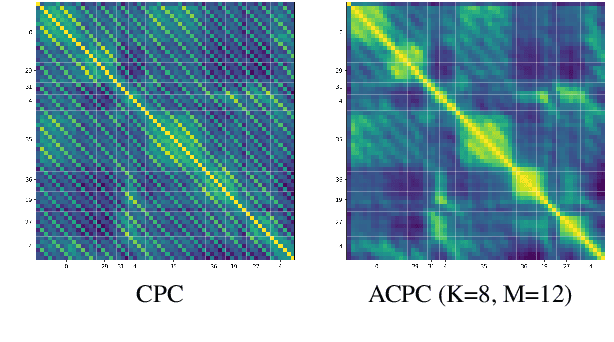
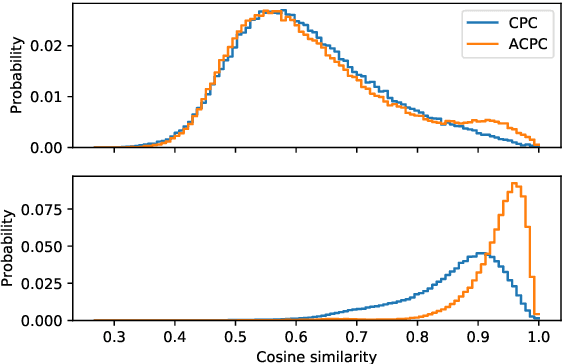
We investigate the possibility of forcing a self-supervised model trained using a contrastive predictive loss to extract slowly varying latent representations. Rather than producing individual predictions for each of the future representations, the model emits a sequence of predictions shorter than that of the upcoming representations to which they will be aligned. In this way, the prediction network solves a simpler task of predicting the next symbols, but not their exact timing, while the encoding network is trained to produce piece-wise constant latent codes. We evaluate the model on a speech coding task and demonstrate that the proposed Aligned Contrastive Predictive Coding (ACPC) leads to higher linear phone prediction accuracy and lower ABX error rates, while being slightly faster to train due to the reduced number of prediction heads.
Representing Point Clouds with Generative Conditional Invertible Flow Networks
Oct 07, 2020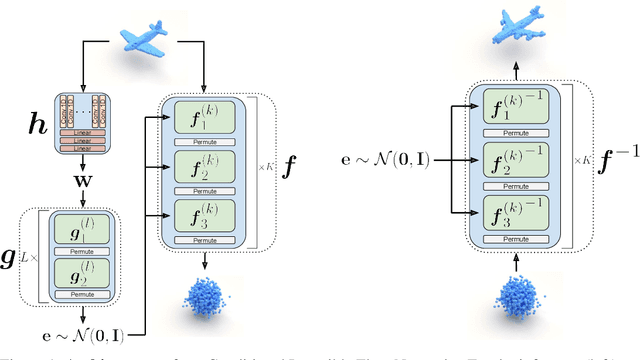
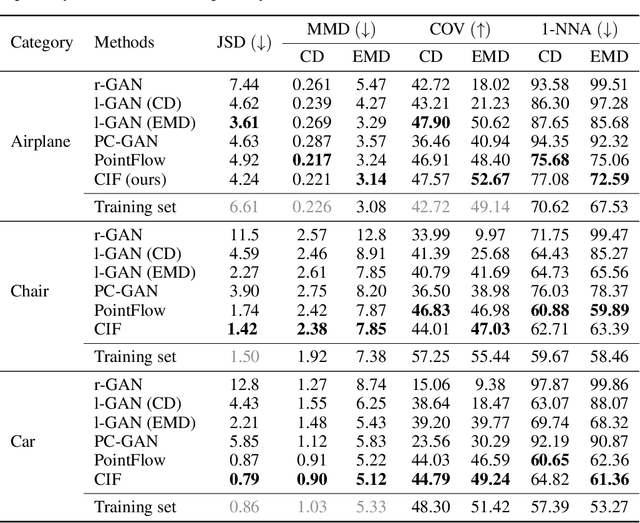


In this paper, we propose a simple yet effective method to represent point clouds as sets of samples drawn from a cloud-specific probability distribution. This interpretation matches intrinsic characteristics of point clouds: the number of points and their ordering within a cloud is not important as all points are drawn from the proximity of the object boundary. We postulate to represent each cloud as a parameterized probability distribution defined by a generative neural network. Once trained, such a model provides a natural framework for point cloud manipulation operations, such as aligning a new cloud into a default spatial orientation. To exploit similarities between same-class objects and to improve model performance, we turn to weight sharing: networks that model densities of points belonging to objects in the same family share all parameters with the exception of a small, object-specific embedding vector. We show that these embedding vectors capture semantic relationships between objects. Our method leverages generative invertible flow networks to learn embeddings as well as to generate point clouds. Thanks to this formulation and contrary to similar approaches, we are able to train our model in an end-to-end fashion. As a result, our model offers competitive or superior quantitative results on benchmark datasets, while enabling unprecedented capabilities to perform cloud manipulation tasks, such as point cloud registration and regeneration, by a generative network.
A Convolutional Deep Markov Model for Unsupervised Speech Representation Learning
Jun 03, 2020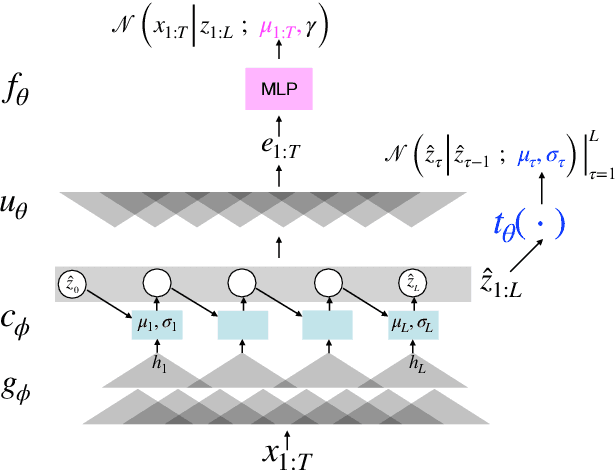
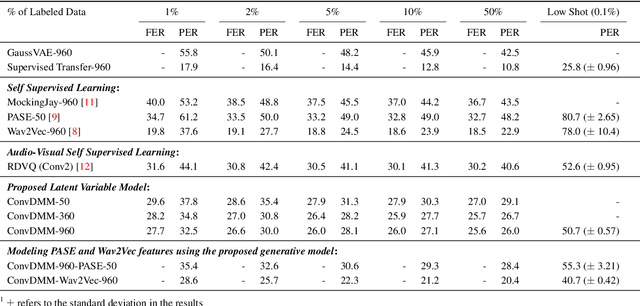
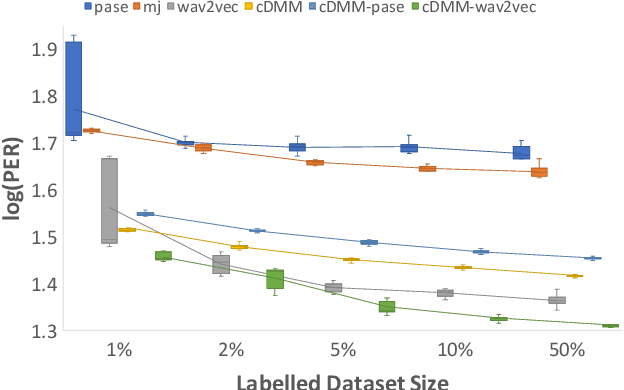
Probabilistic Latent Variable Models (LVMs) provide an alternative to self-supervised learning approaches for linguistic representation learning from speech. LVMs admit an intuitive probabilistic interpretation where the latent structure shapes the information extracted from the signal. Even though LVMs have recently seen a renewed interest due to the introduction of Variational Autoencoders (VAEs), their use for speech representation learning remains largely unexplored. In this work, we propose Convolutional Deep Markov Model (ConvDMM), a Gaussian state-space model with non-linear emission and transition functions modelled by deep neural networks. This unsupervised model is trained using black box variational inference. A deep convolutional neural network is used as an inference network for structured variational approximation. When trained on a large scale speech dataset (LibriSpeech), ConvDMM produces features that significantly outperform multiple self-supervised feature extracting methods on linear phone classification and recognition on the Wall Street Journal dataset. Furthermore, we found that ConvDMM complements self-supervised methods like Wav2Vec and PASE, improving on the results achieved with any of the methods alone. Lastly, we find that ConvDMM features enable learning better phone recognizers than any other features in an extreme low-resource regime with few labeled training examples.
Robust Training of Vector Quantized Bottleneck Models
May 18, 2020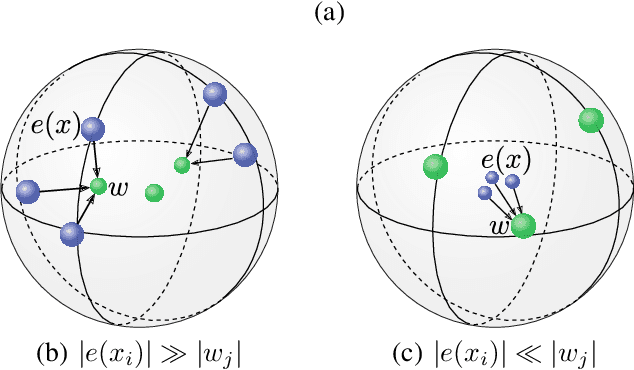
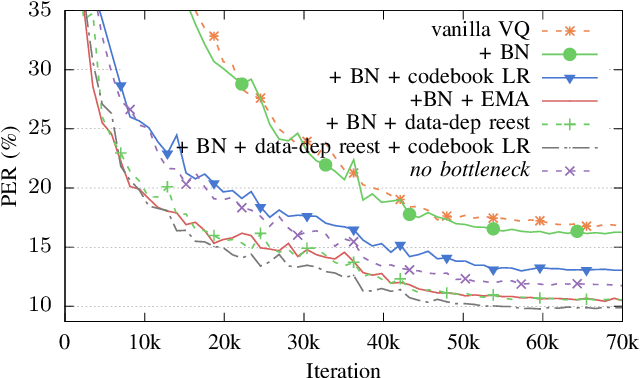
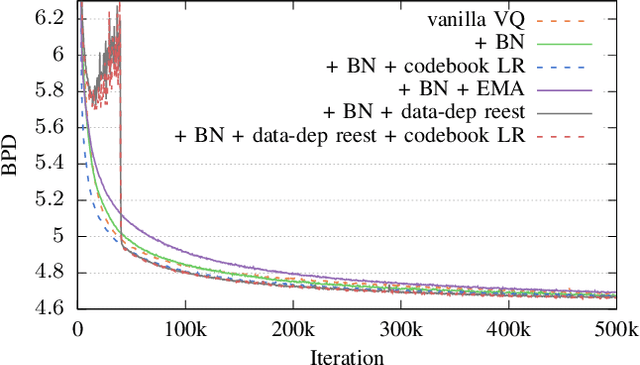

In this paper we demonstrate methods for reliable and efficient training of discrete representation using Vector-Quantized Variational Auto-Encoder models (VQ-VAEs). Discrete latent variable models have been shown to learn nontrivial representations of speech, applicable to unsupervised voice conversion and reaching state-of-the-art performance on unit discovery tasks. For unsupervised representation learning, they became viable alternatives to continuous latent variable models such as the Variational Auto-Encoder (VAE). However, training deep discrete variable models is challenging, due to the inherent non-differentiability of the discretization operation. In this paper we focus on VQ-VAE, a state-of-the-art discrete bottleneck model shown to perform on par with its continuous counterparts. It quantizes encoder outputs with on-line $k$-means clustering. We show that the codebook learning can suffer from poor initialization and non-stationarity of clustered encoder outputs. We demonstrate that these can be successfully overcome by increasing the learning rate for the codebook and periodic date-dependent codeword re-initialization. As a result, we achieve more robust training across different tasks, and significantly increase the usage of latent codewords even for large codebooks. This has practical benefit, for instance, in unsupervised representation learning, where large codebooks may lead to disentanglement of latent representations.