 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Rewriting for Multi-Stage ASR
Dec 08, 2023



For many streaming automatic speech recognition tasks, it is important to provide timely intermediate streaming results, while refining a high quality final result. This can be done using a multi-stage architecture, where a small left-context only model creates streaming results and a larger left- and right-context model produces a final result at the end. While this significantly improves the quality of the final results without compromising the streaming emission latency of the system, streaming results do not benefit from the quality improvements. Here, we propose using a text manipulation algorithm that merges the streaming outputs of both models. We improve the quality of streaming results by around 10%, without altering the final results. Our approach introduces no additional latency and reduces flickering. It is also lightweight, does not require retraining the model, and it can be applied to a wide variety of multi-stage architectures.
Sharing Low Rank Conformer Weights for Tiny Always-On Ambient Speech Recognition Models
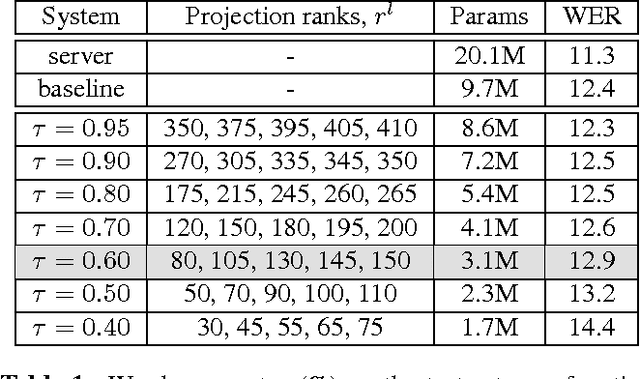
Mar 15, 2023Continued improvements in machine learning techniques offer exciting new opportunities through the use of larger models and larger training datasets. However, there is a growing need to offer these new capabilities on-board low-powered devices such as smartphones, wearables and other embedded environments where only low memory is available. Towards this, we consider methods to reduce the model size of Conformer-based speech recognition models which typically require models with greater than 100M parameters down to just $5$M parameters while minimizing impact on model quality. Such a model allows us to achieve always-on ambient speech recognition on edge devices with low-memory neural processors. We propose model weight reuse at different levels within our model architecture: (i) repeating full conformer block layers, (ii) sharing specific conformer modules across layers, (iii) sharing sub-components per conformer module, and (iv) sharing decomposed sub-component weights after low-rank decomposition. By sharing weights at different levels of our model, we can retain the full model in-memory while increasing the number of virtual transformations applied to the input. Through a series of ablation studies and evaluations, we find that with weight sharing and a low-rank architecture, we can achieve a WER of 2.84 and 2.94 for Librispeech dev-clean and test-clean respectively with a $5$M parameter model.
Neural-FST Class Language Model for End-to-End Speech Recognition
Jan 31, 2022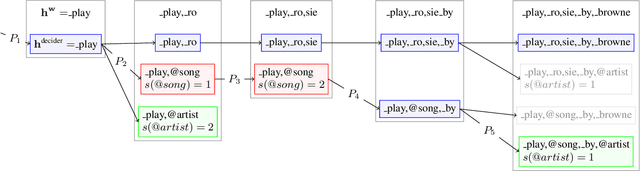
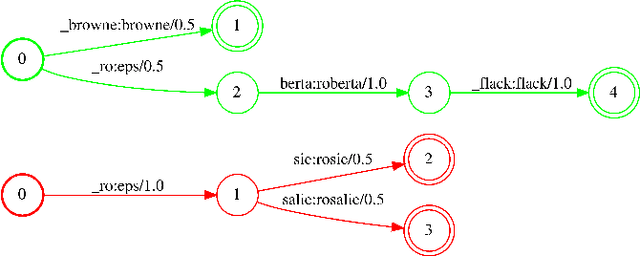
We propose Neural-FST Class Language Model (NFCLM) for end-to-end speech recognition, a novel method that combines neural network language models (NNLMs) and finite state transducers (FSTs) in a mathematically consistent framework. Our method utilizes a background NNLM which models generic background text together with a collection of domain-specific entities modeled as individual FSTs. Each output token is generated by a mixture of these components; the mixture weights are estimated with a separately trained neural decider. We show that NFCLM significantly outperforms NNLM by 15.8% relative in terms of Word Error Rate. NFCLM achieves similar performance as traditional NNLM and FST shallow fusion while being less prone to overbiasing and 12 times more compact, making it more suitable for on-device usage.
Improved Neural Language Model Fusion for Streaming Recurrent Neural Network Transducer
Oct 26, 2020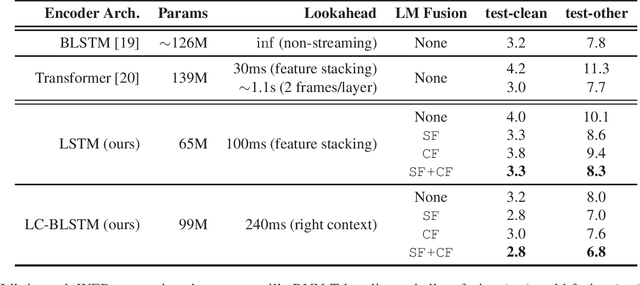
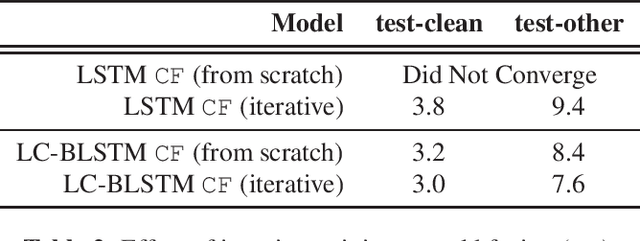
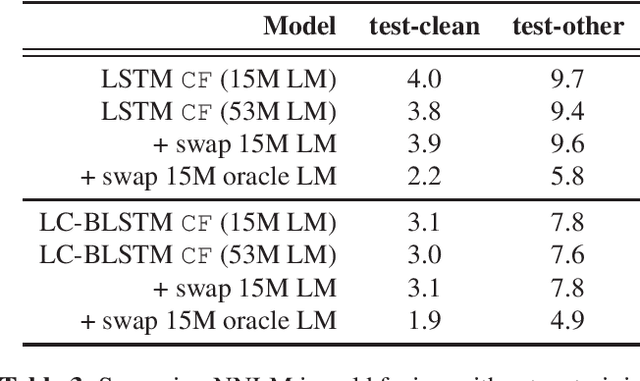
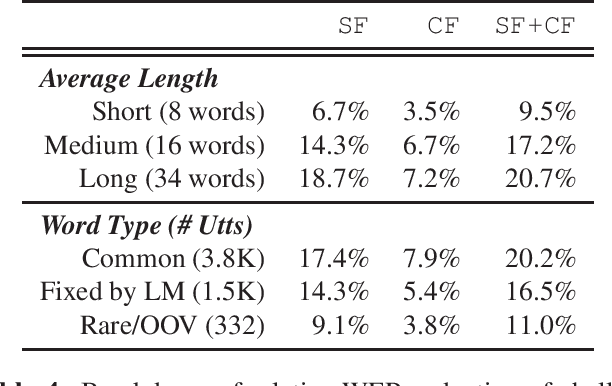
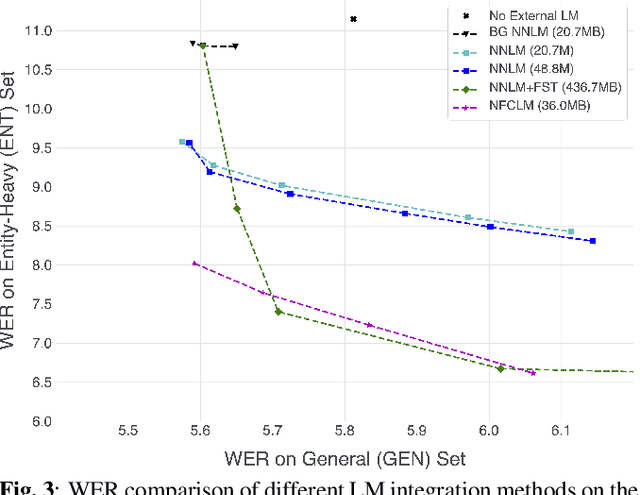
Recurrent Neural Network Transducer (RNN-T), like most end-to-end speech recognition model architectures, has an implicit neural network language model (NNLM) and cannot easily leverage unpaired text data during training. Previous work has proposed various fusion methods to incorporate external NNLMs into end-to-end ASR to address this weakness. In this paper, we propose extensions to these techniques that allow RNN-T to exploit external NNLMs during both training and inference time, resulting in 13-18% relative Word Error Rate improvement on Librispeech compared to strong baselines. Furthermore, our methods do not incur extra algorithmic latency and allow for flexible plug-and-play of different NNLMs without re-training. We also share in-depth analysis to better understand the benefits of the different NNLM fusion methods. Our work provides a reliable technique for leveraging unpaired text data to significantly improve RNN-T while keeping the system streamable, flexible, and lightweight.
A Streaming On-Device End-to-End Model Surpassing Server-Side Conventional Model Quality and Latency
Mar 28, 2020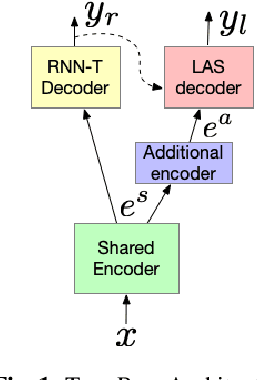
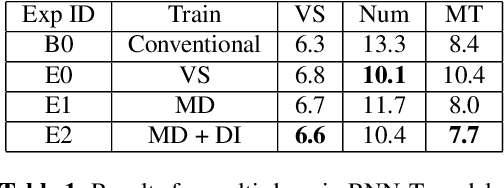
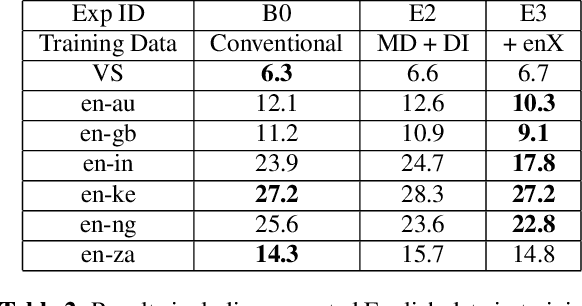
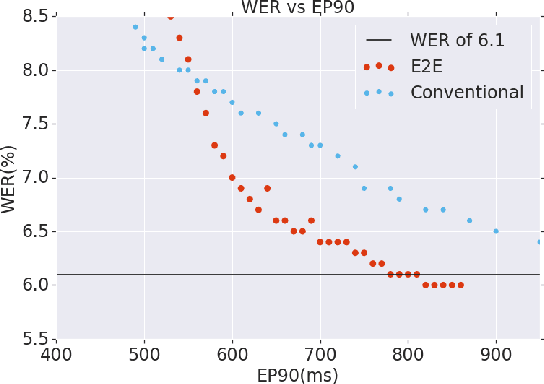
Thus far, end-to-end (E2E) models have not been shown to outperform state-of-the-art conventional models with respect to both quality, i.e., word error rate (WER), and latency, i.e., the time the hypothesis is finalized after the user stops speaking. In this paper, we develop a first-pass Recurrent Neural Network Transducer (RNN-T) model and a second-pass Listen, Attend, Spell (LAS) rescorer that surpasses a conventional model in both quality and latency. On the quality side, we incorporate a large number of utterances across varied domains to increase acoustic diversity and the vocabulary seen by the model. We also train with accented English speech to make the model more robust to different pronunciations. In addition, given the increased amount of training data, we explore a varied learning rate schedule. On the latency front, we explore using the end-of-sentence decision emitted by the RNN-T model to close the microphone, and also introduce various optimizations to improve the speed of LAS rescoring. Overall, we find that RNN-T+LAS offers a better WER and latency tradeoff compared to a conventional model. For example, for the same latency, RNN-T+LAS obtains a 8% relative improvement in WER, while being more than 400-times smaller in model size.
Phoneme-Based Contextualization for Cross-Lingual Speech Recognition in End-to-End Models
Jul 22, 2019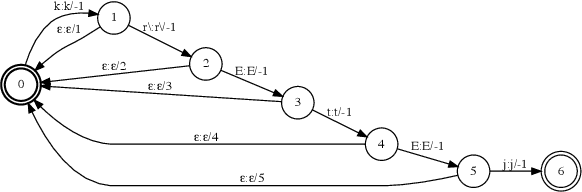


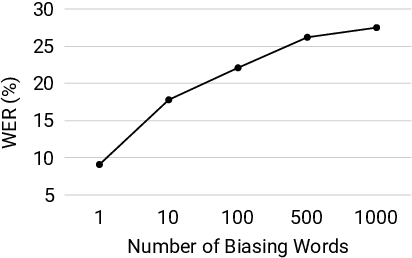
Contextual automatic speech recognition, i.e., biasing recognition towards a given context (e.g. user's playlists, or contacts), is challenging in end-to-end (E2E) models. Such models maintain a limited number of candidates during beam-search decoding, and have been found to recognize rare named entities poorly. The problem is exacerbated when biasing towards proper nouns in foreign languages, e.g., geographic location names, which are virtually unseen in training and are thus out-of-vocabulary (OOV). While grapheme or wordpiece E2E models might have a difficult time spelling OOV words, phonemes are more acoustically salient and past work has shown that E2E phoneme models can better predict such words. In this work, we propose an E2E model containing both English wordpieces and phonemes in the modeling space, and perform contextual biasing of foreign words at the phoneme level by mapping pronunciations of foreign words into similar English phonemes. In experimental evaluations, we find that the proposed approach performs 16% better than a grapheme-only biasing model, and 8% better than a wordpiece-only biasing model on a foreign place name recognition task, with only slight degradation on regular English tasks.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Model Unit Exploration for Sequence-to-Sequence Speech Recognition
Feb 05, 2019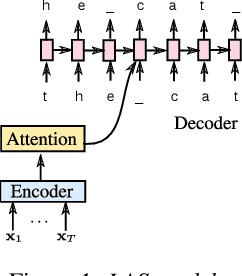
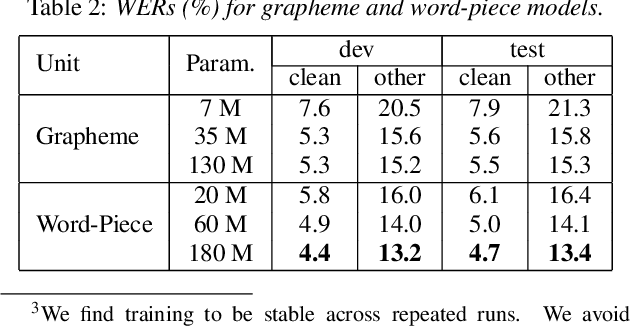
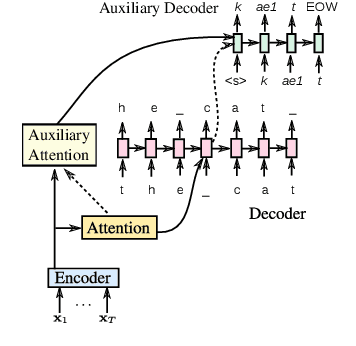
We evaluate attention-based encoder-decoder models along two dimensions: choice of target unit (phoneme, grapheme, and word-piece), and the amount of available training data. We conduct experiments on the LibriSpeech 100hr, 460hr, and 960hr tasks; across all tasks, we find that grapheme or word-piece models consistently outperform phoneme-based models, even though they are evaluated without a lexicon or an external language model. On the 960hr task the word-piece model achieves a word error rate (WER) of 4.7% on the test-clean set and 13.4% on the test-other set, which improves to 3.6% (clean) and 10.3% (other) when decoded with an LSTM LM: the lowest reported numbers using sequence-to-sequence models. We also conduct a detailed analysis of the various models, and investigate their complementarity: we find that we can improve WERs by up to 9% relative by rescoring N-best lists generated from the word-piece model with either the phoneme or the grapheme model. Rescoring an N-best list generated by the phonemic system, however, provides limited improvements. Further analysis shows that the word-piece-based models produce more diverse N-best hypotheses, resulting in lower oracle WERs, than the phonemic system.
NN-grams: Unifying neural network and n-gram language models for Speech Recognition
Jun 23, 2016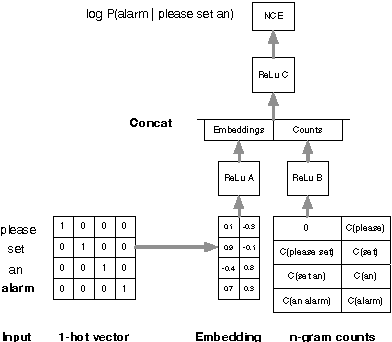


We present NN-grams, a novel, hybrid language model integrating n-grams and neural networks (NN) for speech recognition. The model takes as input both word histories as well as n-gram counts. Thus, it combines the memorization capacity and scalability of an n-gram model with the generalization ability of neural networks. We report experiments where the model is trained on 26B words. NN-grams are efficient at run-time since they do not include an output soft-max layer. The model is trained using noise contrastive estimation (NCE), an approach that transforms the estimation problem of neural networks into one of binary classification between data samples and noise samples. We present results with noise samples derived from either an n-gram distribution or from speech recognition lattices. NN-grams outperforms an n-gram model on an Italian speech recognition dictation task.
On the Compression of Recurrent Neural Networks with an Application to LVCSR acoustic modeling for Embedded Speech Recognition
May 02, 2016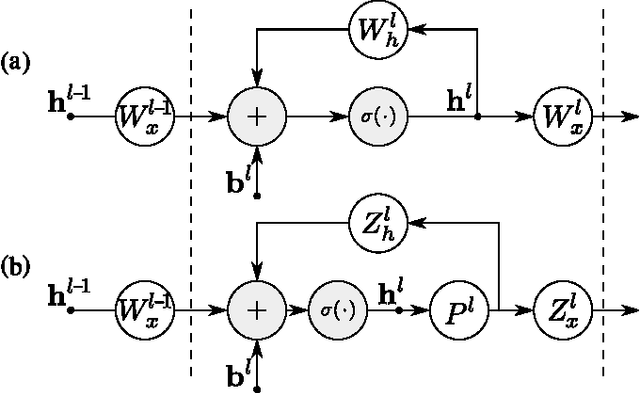
We study the problem of compressing recurrent neural networks (RNNs). In particular, we focus on the compression of RNN acoustic models, which are motivated by the goal of building compact and accurate speech recognition systems which can be run efficiently on mobile devices. In this work, we present a technique for general recurrent model compression that jointly compresses both recurrent and non-recurrent inter-layer weight matrices. We find that the proposed technique allows us to reduce the size of our Long Short-Term Memory (LSTM) acoustic model to a third of its original size with negligible loss in accuracy.