 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM Audio Judge: A Unified Multimodal Framework for Perceptual Evaluation of Audio Separation
Jan 27, 2026The performance evaluation remains a complex challenge in audio separation, and existing evaluation metrics are often misaligned with human perception, course-grained, relying on ground truth signals. On the other hand, subjective listening tests remain the gold standard for real-world evaluation, but they are expensive, time-consuming, and difficult to scale. This paper addresses the growing need for automated systems capable of evaluating audio separation without human intervention. The proposed evaluation metric, SAM Audio Judge (SAJ), is a multimodal fine-grained reference-free objective metric, which shows highly alignment with human perceptions. SAJ supports three audio domains (speech, music and general sound events) and three prompt inputs (text, visual and span), covering four different dimensions of evaluation (recall, percision, faithfulness, and overall). SAM Audio Judge also shows potential applications in data filtering, pseudo-labeling large datasets and reranking in audio separation models. We release our code and pre-trained models at: https://github.com/facebookresearch/sam-audio.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Pushing the Frontier of Audiovisual Perception with Large-Scale Multimodal Correspondence Learning
Dec 22, 2025We introduce Perception Encoder Audiovisual, PE-AV, a new family of encoders for audio and video understanding trained with scaled contrastive learning. Built on PE, PE-AV makes several key contributions to extend representations to audio, and natively support joint embeddings across audio-video, audio-text, and video-text modalities. PE-AV's unified cross-modal embeddings enable novel tasks such as speech retrieval, and set a new state of the art across standard audio and video benchmarks. We unlock this by building a strong audiovisual data engine that synthesizes high-quality captions for O(100M) audio-video pairs, enabling large-scale supervision consistent across modalities. Our audio data includes speech, music, and general sound effects-avoiding single-domain limitations common in prior work. We exploit ten pairwise contrastive objectives, showing that scaling cross-modality and caption-type pairs strengthens alignment and improves zero-shot performance. We further develop PE-A-Frame by fine-tuning PE-AV with frame-level contrastive objectives, enabling fine-grained audio-frame-to-text alignment for tasks such as sound event detection.
SAM Audio: Segment Anything in Audio
Dec 19, 2025



General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
FlowDec: A flow-based full-band general audio codec with high perceptual quality
Mar 03, 2025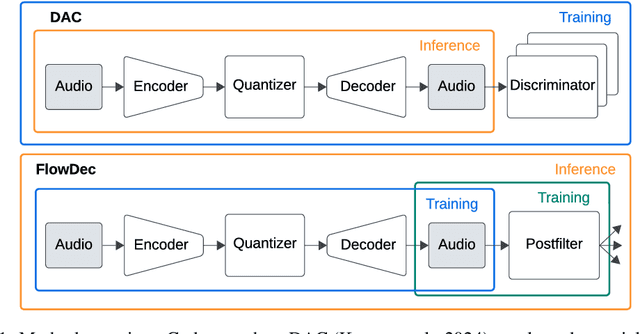
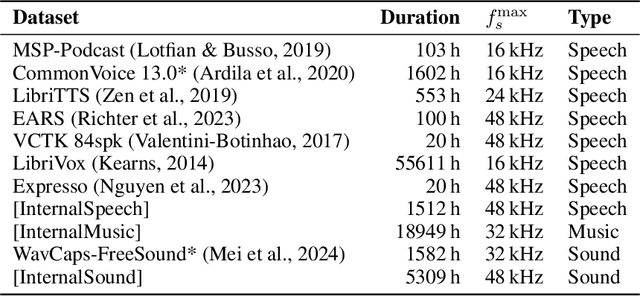

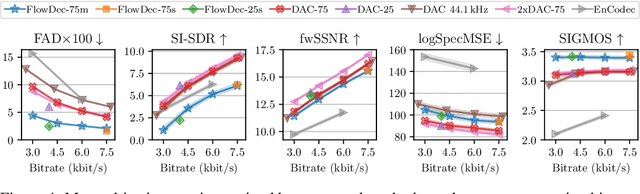
We propose FlowDec, a neural full-band audio codec for general audio sampled at 48 kHz that combines non-adversarial codec training with a stochastic postfilter based on a novel conditional flow matching method. Compared to the prior work ScoreDec which is based on score matching, we generalize from speech to general audio and move from 24 kbit/s to as low as 4 kbit/s, while improving output quality and reducing the required postfilter DNN evaluations from 60 to 6 without any fine-tuning or distillation techniques. We provide theoretical insights and geometric intuitions for our approach in comparison to ScoreDec as well as another recent work that uses flow matching, and conduct ablation studies on our proposed components. We show that FlowDec is a competitive alternative to the recent GAN-dominated stream of neural codecs, achieving FAD scores better than those of the established GAN-based codec DAC and listening test scores that are on par, and producing qualitatively more natural reconstructions for speech and harmonic structures in music.
Meta Audiobox Aesthetics: Unified Automatic Quality Assessment for Speech, Music, and Sound
Feb 07, 2025



The quantification of audio aesthetics remains a complex challenge in audio processing, primarily due to its subjective nature, which is influenced by human perception and cultural context. Traditional methods often depend on human listeners for evaluation, leading to inconsistencies and high resource demands. This paper addresses the growing need for automated systems capable of predicting audio aesthetics without human intervention. Such systems are crucial for applications like data filtering, pseudo-labeling large datasets, and evaluating generative audio models, especially as these models become more sophisticated. In this work, we introduce a novel approach to audio aesthetic evaluation by proposing new annotation guidelines that decompose human listening perspectives into four distinct axes. We develop and train no-reference, per-item prediction models that offer a more nuanced assessment of audio quality. Our models are evaluated against human mean opinion scores (MOS) and existing methods, demonstrating comparable or superior performance. This research not only advances the field of audio aesthetics but also provides open-source models and datasets to facilitate future work and benchmarking. We release our code and pre-trained model at: https://github.com/facebookresearch/audiobox-aesthetics
Audiobox TTA-RAG: Improving Zero-Shot and Few-Shot Text-To-Audio with Retrieval-Augmented Generation
Nov 07, 2024Current leading Text-To-Audio (TTA) generation models suffer from degraded performance on zero-shot and few-shot settings. It is often challenging to generate high-quality audio for audio events that are unseen or uncommon in the training set. Inspired by the success of Retrieval-Augmented Generation (RAG) in Large Language Model (LLM)-based knowledge-intensive tasks, we extend the TTA process with additional conditioning contexts. We propose Audiobox TTA-RAG, a novel retrieval-augmented TTA approach based on Audiobox, a conditional flow-matching audio generation model. Unlike the vanilla Audiobox TTA solution which generates audio conditioned on text, we augmented the conditioning input with retrieved audio samples that provide additional acoustic information to generate the target audio. Our retrieval method does not require the external database to have labeled audio, offering more practical use cases. To evaluate our proposed method, we curated test sets in zero-shot and few-shot settings. Our empirical results show that the proposed model can effectively leverage the retrieved audio samples and significantly improve zero-shot and few-shot TTA performance, with large margins on multiple evaluation metrics, while maintaining the ability to generate semantically aligned audio for the in-domain setting. In addition, we investigate the effect of different retrieval methods and data sources.
MusicFlow: Cascaded Flow Matching for Text Guided Music Generation
Oct 27, 2024



We introduce MusicFlow, a cascaded text-to-music generation model based on flow matching. Based on self-supervised representations to bridge between text descriptions and music audios, we construct two flow matching networks to model the conditional distribution of semantic and acoustic features. Additionally, we leverage masked prediction as the training objective, enabling the model to generalize to other tasks such as music infilling and continuation in a zero-shot manner. Experiments on MusicCaps reveal that the music generated by MusicFlow exhibits superior quality and text coherence despite being over $2\sim5$ times smaller and requiring $5$ times fewer iterative steps. Simultaneously, the model can perform other music generation tasks and achieves competitive performance in music infilling and continuation. Our code and model will be publicly available.
Movie Gen: A Cast of Media Foundation Models
Oct 17, 2024



We present Movie Gen, a cast of foundation models that generates high-quality, 1080p HD videos with different aspect ratios and synchronized audio. We also show additional capabilities such as precise instruction-based video editing and generation of personalized videos based on a user's image. Our models set a new state-of-the-art on multiple tasks: text-to-video synthesis, video personalization, video editing, video-to-audio generation, and text-to-audio generation. Our largest video generation model is a 30B parameter transformer trained with a maximum context length of 73K video tokens, corresponding to a generated video of 16 seconds at 16 frames-per-second. We show multiple technical innovations and simplifications on the architecture, latent spaces, training objectives and recipes, data curation, evaluation protocols, parallelization techniques, and inference optimizations that allow us to reap the benefits of scaling pre-training data, model size, and training compute for training large scale media generation models. We hope this paper helps the research community to accelerate progress and innovation in media generation models. All videos from this paper are available at https://go.fb.me/MovieGenResearchVideos.
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Jul 04, 2024



We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.