 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecomposer: Event-roll-guided generative audio editing
Sep 05, 2025Editing complex real-world sound scenes is difficult because individual sound sources overlap in time. Generative models can fill-in missing or corrupted details based on their strong prior understanding of the data domain. We present a system for editing individual sound events within complex scenes able to delete, insert, and enhance individual sound events based on textual edit descriptions (e.g., ``enhance Door'') and a graphical representation of the event timing derived from an ``event roll'' transcription. We present an encoder-decoder transformer working on SoundStream representations, trained on synthetic (input, desired output) audio example pairs formed by adding isolated sound events to dense, real-world backgrounds. Evaluation reveals the importance of each part of the edit descriptions -- action, class, timing. Our work demonstrates ``recomposition'' is an important and practical application.
Unsupervised Multi-channel Separation and Adaptation
May 18, 2023


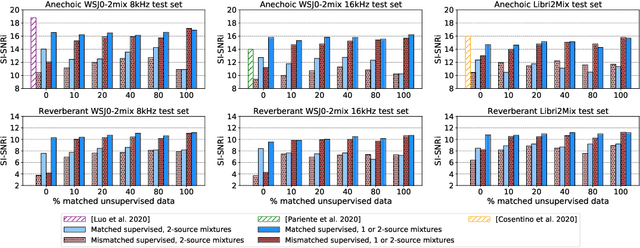
A key challenge in machine learning is to generalize from training data to an application domain of interest. This work generalizes the recently-proposed mixture invariant training (MixIT) algorithm to perform unsupervised learning in the multi-channel setting. We use MixIT to train a model on far-field microphone array recordings of overlapping reverberant and noisy speech from the AMI Corpus. The models are trained on both supervised and unsupervised training data, and are tested on real AMI recordings containing overlapping speech. To objectively evaluate our models, we also use a synthetic multi-channel AMI test set. Holding network architectures constant, we find that a fine-tuned semi-supervised model yields the largest improvement to SI-SNR and to human listening ratings across synthetic and real datasets, outperforming supervised models trained on well-matched synthetic data. Our results demonstrate that unsupervised learning through MixIT enables model adaptation on both single- and multi-channel real-world speech recordings.
NUBO: A Transparent Python Package for Bayesian Optimisation
May 11, 2023NUBO, short for Newcastle University Bayesian Optimisation, is a Bayesian optimisation framework for the optimisation of expensive-to-evaluate black-box functions, such as physical experiments and computer simulators. Bayesian optimisation is a cost-efficient optimisation strategy that uses surrogate modelling via Gaussian processes to represent an objective function and acquisition functions to guide the selection of candidate points to approximate the global optimum of the objective function. NUBO itself focuses on transparency and user experience to make Bayesian optimisation easily accessible to researchers from all disciplines. Clean and understandable code, precise references, and thorough documentation ensure transparency, while user experience is ensured by a modular and flexible design, easy-to-write syntax, and careful selection of Bayesian optimisation algorithms. NUBO allows users to tailor Bayesian optimisation to their specific problem by writing the optimisation loop themselves using the provided building blocks. It supports sequential single-point, parallel multi-point, and asynchronous optimisation of bounded, constrained, and/or mixed (discrete and continuous) parameter input spaces. Only algorithms and methods that are extensively tested and validated to perform well are included in NUBO. This ensures that the package remains compact and does not overwhelm the user with an unnecessarily large number of options. The package is written in Python but does not require expert knowledge of Python to optimise your simulators and experiments. NUBO is distributed as open-source software under the BSD 3-Clause licence.
Distance-Based Sound Separation
Jul 01, 2022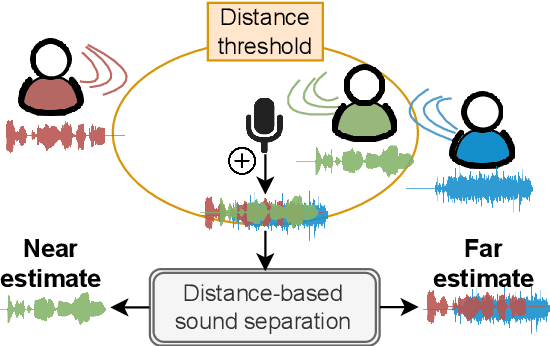
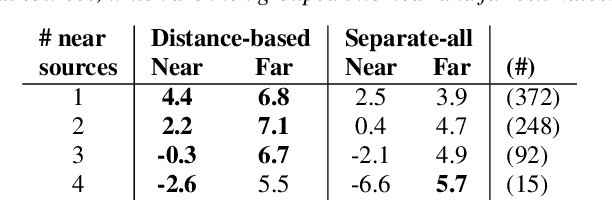
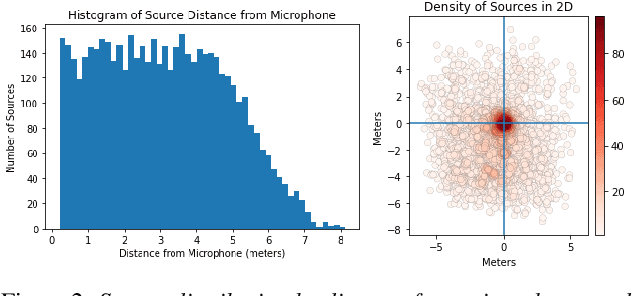

We propose the novel task of distance-based sound separation, where sounds are separated based only on their distance from a single microphone. In the context of assisted listening devices, proximity provides a simple criterion for sound selection in noisy environments that would allow the user to focus on sounds relevant to a local conversation. We demonstrate the feasibility of this approach by training a neural network to separate near sounds from far sounds in single channel synthetic reverberant mixtures, relative to a threshold distance defining the boundary between near and far. With a single nearby speaker and four distant speakers, the model improves scale-invariant signal to noise ratio by 4.4 dB for near sounds and 6.8 dB for far sounds.
End-to-End Diarization for Variable Number of Speakers with Local-Global Networks and Discriminative Speaker Embeddings
May 05, 2021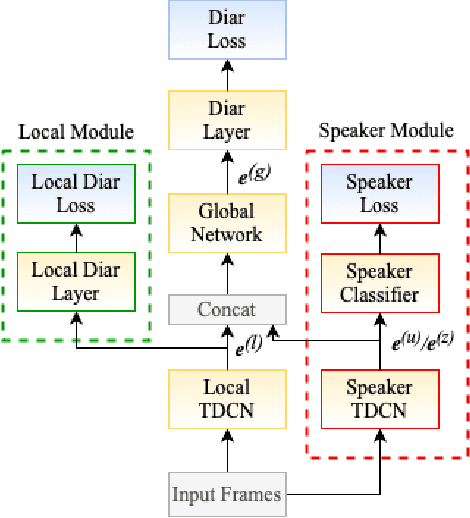
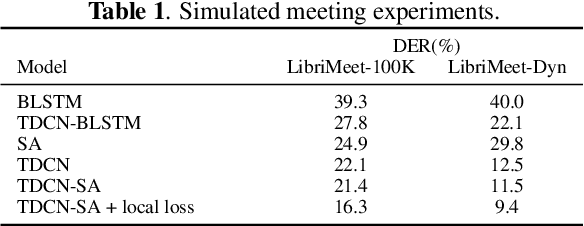
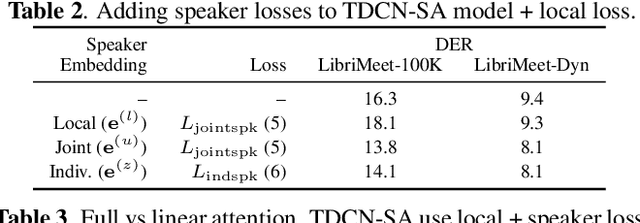
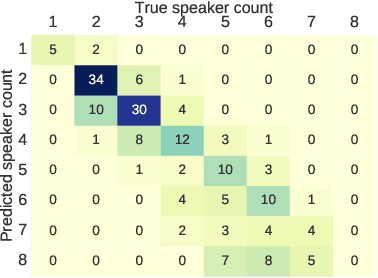
We present an end-to-end deep network model that performs meeting diarization from single-channel audio recordings. End-to-end diarization models have the advantage of handling speaker overlap and enabling straightforward handling of discriminative training, unlike traditional clustering-based diarization methods. The proposed system is designed to handle meetings with unknown numbers of speakers, using variable-number permutation-invariant cross-entropy based loss functions. We introduce several components that appear to help with diarization performance, including a local convolutional network followed by a global self-attention module, multi-task transfer learning using a speaker identification component, and a sequential approach where the model is refined with a second stage. These are trained and validated on simulated meeting data based on LibriSpeech and LibriTTS datasets; final evaluations are done using LibriCSS, which consists of simulated meetings recorded using real acoustics via loudspeaker playback. The proposed model performs better than previously proposed end-to-end diarization models on these data.
* 5 pages, 2 figures, ICASSP 2021
VoiceFilter-Lite: Streaming Targeted Voice Separation for On-Device Speech Recognition
Sep 09, 2020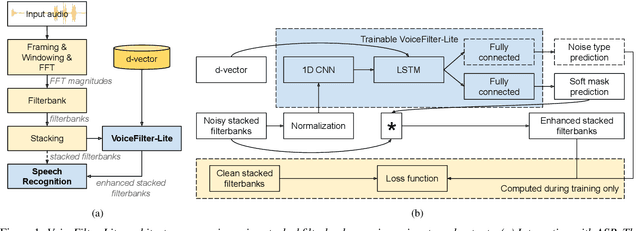

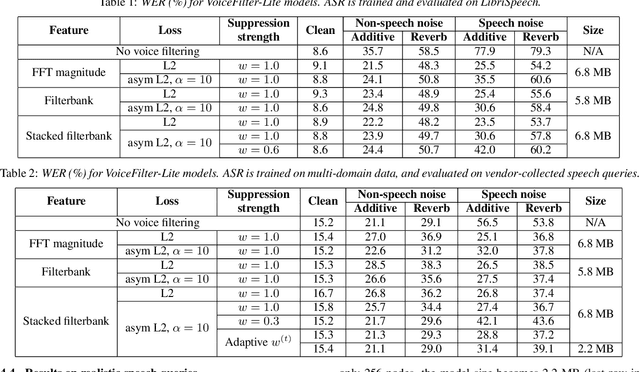
We introduce VoiceFilter-Lite, a single-channel source separation model that runs on the device to preserve only the speech signals from a target user, as part of a streaming speech recognition system. Delivering such a model presents numerous challenges: It should improve the performance when the input signal consists of overlapped speech, and must not hurt the speech recognition performance under all other acoustic conditions. Besides, this model must be tiny, fast, and perform inference in a streaming fashion, in order to have minimal impact on CPU, memory, battery and latency. We propose novel techniques to meet these multi-faceted requirements, including using a new asymmetric loss, and adopting adaptive runtime suppression strength. We also show that such a model can be quantized as a 8-bit integer model and run in realtime.
Unsupervised Sound Separation Using Mixtures of Mixtures
Jun 23, 2020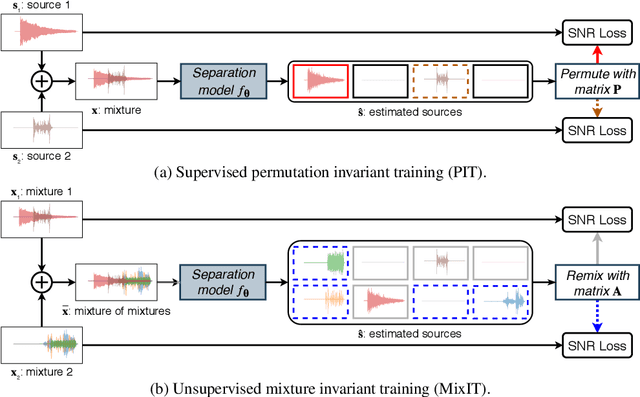
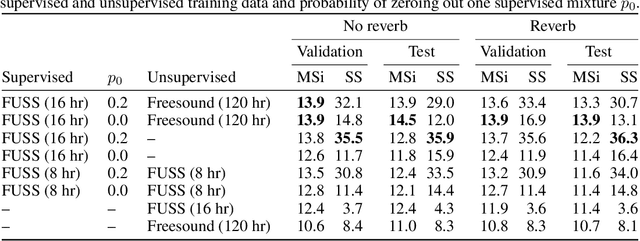
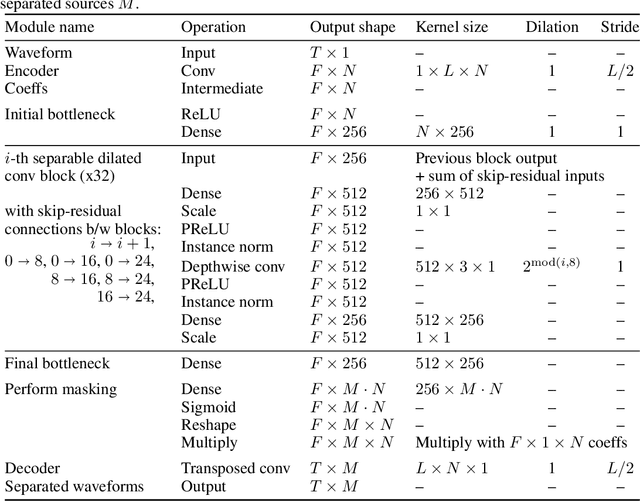
In recent years, rapid progress has been made on the problem of single-channel sound separation using supervised training of deep neural networks. In such supervised approaches, the model is trained to predict the component sources from synthetic mixtures created by adding up isolated ground-truth sources. The reliance on this synthetic training data is problematic because good performance depends upon the degree of match between the training data and real-world audio, especially in terms of the acoustic conditions and distribution of sources. The acoustic properties can be challenging to accurately simulate, and the distribution of sound types may be hard to replicate. In this paper, we propose a completely unsupervised method, mixture invariant training (MixIT), that requires only single-channel acoustic mixtures. In MixIT, training examples are constructed by mixing together existing mixtures, and the model separates them into a variable number of latent sources, such that the separated sources can be remixed to approximate the original mixtures. We show that MixIT can achieve competitive performance compared to supervised methods on speech separation. Using MixIT in a semi-supervised learning setting enables unsupervised domain adaptation and learning from large amounts of real-world data without ground-truth source waveforms. In particular, we significantly improve reverberant speech separation performance by incorporating reverberant mixtures, train a speech enhancement system from noisy mixtures, and improve universal sound separation by incorporating a large amount of in-the-wild data.
Alternating Between Spectral and Spatial Estimation for Speech Separation and Enhancement
Nov 18, 2019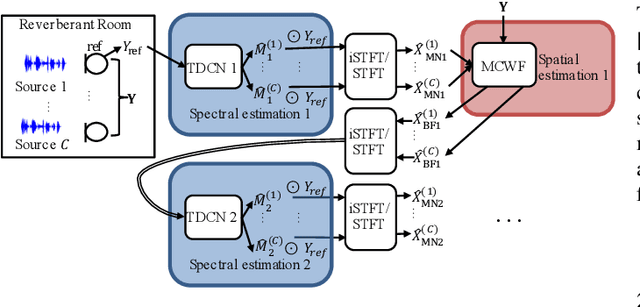
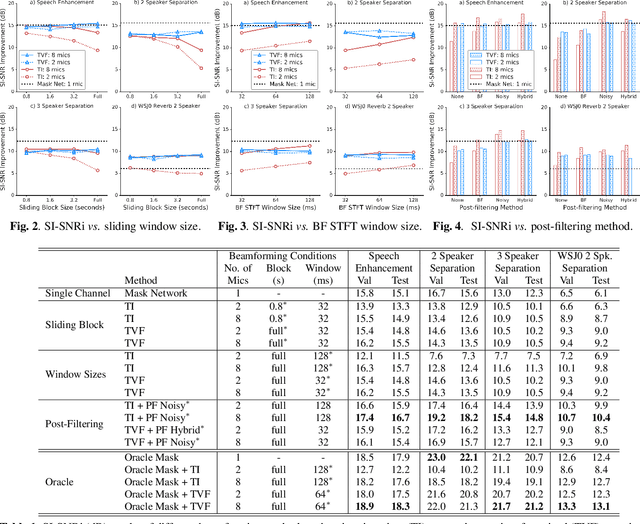
This work investigates alternation between spectral separation using masking-based networks and spatial separation using multichannel beamforming. In this framework, the spectral separation is performed using a mask-based deep network. The result of mask-based separation is used, in turn, to estimate a spatial beamformer. The output of the beamformer is fed back into another mask-based separation network. We explore multiple ways of computing time-varying covariance matrices to improve beamforming, including factorizing the spatial covariance into a time-varying amplitude component and time-invariant spatial component. For the subsequent mask-based filtering, we consider different modes, including masking the noisy input, masking the beamformer output, and a hybrid approach combining both. Our best method first uses spectral separation, then spatial beamforming, and finally a spectral post-filter, and demonstrates an average improvement of 2.8 dB over baseline mask-based separation, across four different reverberant speech enhancement and separation tasks.
Universal Sound Separation
May 08, 2019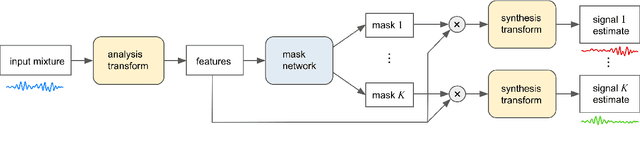
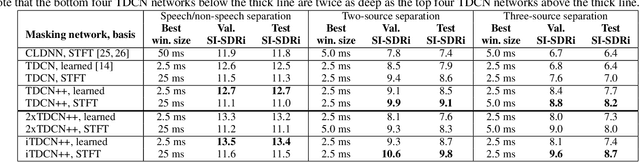
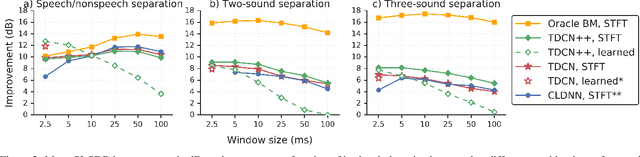
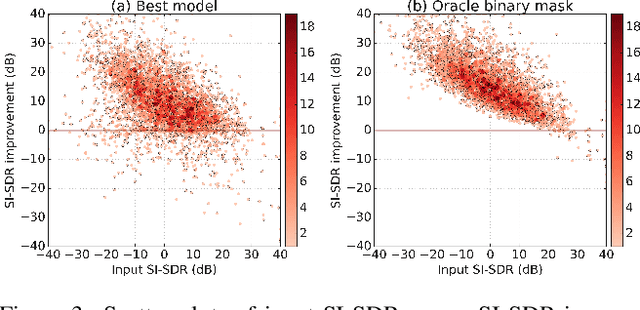
Recent deep learning approaches have achieved impressive performance on speech enhancement and separation tasks. However, these approaches have not been investigated for separating mixtures of arbitrary sounds of different types, a task we refer to as universal sound separation, and it is unknown whether performance on speech tasks carries over to non-speech tasks. To study this question, we develop a universal dataset of mixtures containing arbitrary sounds, and use it to investigate the space of mask-based separation architectures, varying both the overall network architecture and the framewise analysis-synthesis basis for signal transformations. These network architectures include convolutional long short-term memory networks and time-dilated convolution stacks inspired by the recent success of time-domain enhancement networks like ConvTasNet. For the latter architecture, we also propose novel modifications that further improve separation performance. In terms of the framewise analysis-synthesis basis, we explore using either a short-time Fourier transform (STFT) or a learnable basis, as used in ConvTasNet, and for both of these bases, we examine the effect of window size. In particular, for STFTs, we find that longer windows (25-50 ms) work best for speech/non-speech separation, while shorter windows (2.5 ms) work best for arbitrary sounds. For learnable bases, shorter windows (2.5 ms) work best on all tasks. Surprisingly, for universal sound separation, STFTs outperform learnable bases. Our best methods produce an improvement in scale-invariant signal-to-distortion ratio of over 13 dB for speech/non-speech separation and close to 10 dB for universal sound separation.
VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Oct 27, 2018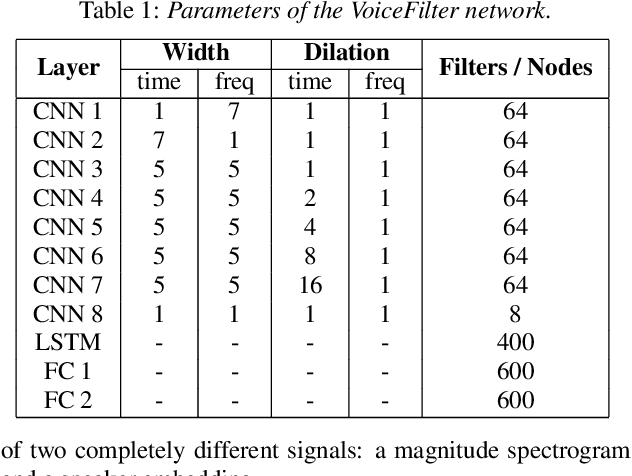
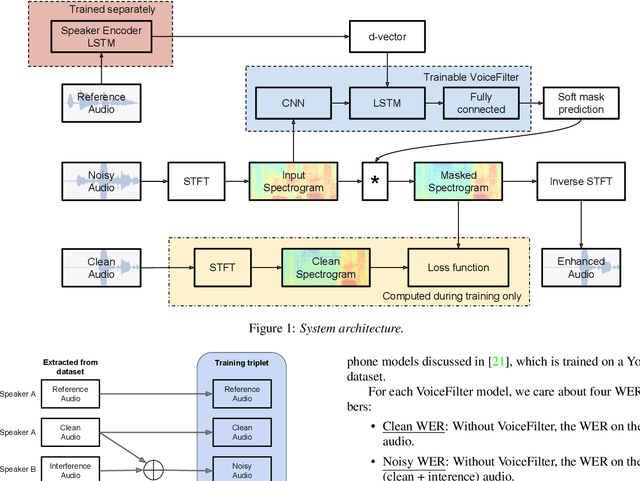
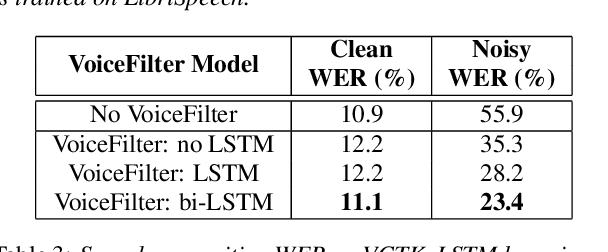
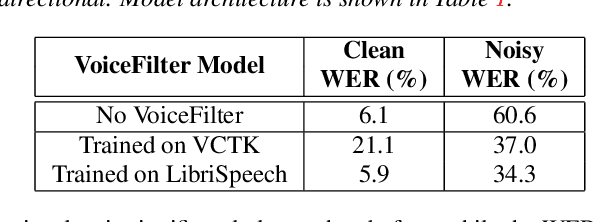
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.