 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecomposer: Event-roll-guided generative audio editing
Sep 05, 2025Editing complex real-world sound scenes is difficult because individual sound sources overlap in time. Generative models can fill-in missing or corrupted details based on their strong prior understanding of the data domain. We present a system for editing individual sound events within complex scenes able to delete, insert, and enhance individual sound events based on textual edit descriptions (e.g., ``enhance Door'') and a graphical representation of the event timing derived from an ``event roll'' transcription. We present an encoder-decoder transformer working on SoundStream representations, trained on synthetic (input, desired output) audio example pairs formed by adding isolated sound events to dense, real-world backgrounds. Evaluation reveals the importance of each part of the edit descriptions -- action, class, timing. Our work demonstrates ``recomposition'' is an important and practical application.
G-Augment: Searching For The Meta-Structure Of Data Augmentation Policies For ASR
Oct 19, 2022
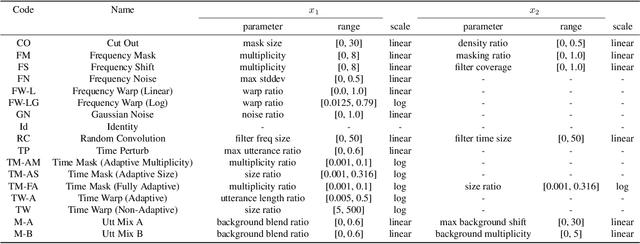
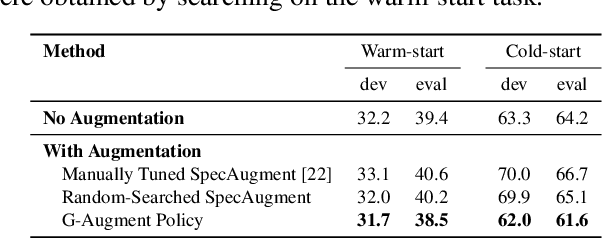
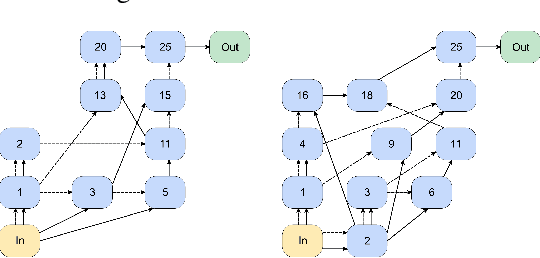
Data augmentation is a ubiquitous technique used to provide robustness to automatic speech recognition (ASR) training. However, even as so much of the ASR training process has become automated and more "end-to-end", the data augmentation policy (what augmentation functions to use, and how to apply them) remains hand-crafted. We present Graph-Augment, a technique to define the augmentation space as directed acyclic graphs (DAGs) and search over this space to optimize the augmentation policy itself. We show that given the same computational budget, policies produced by G-Augment are able to perform better than SpecAugment policies obtained by random search on fine-tuning tasks on CHiME-6 and AMI. G-Augment is also able to establish a new state-of-the-art ASR performance on the CHiME-6 evaluation set (30.7% WER). We further demonstrate that G-Augment policies show better transfer properties across warm-start to cold-start training and model size compared to random-searched SpecAugment policies.
WaveGrad 2: Iterative Refinement for Text-to-Speech Synthesis
Jun 19, 2021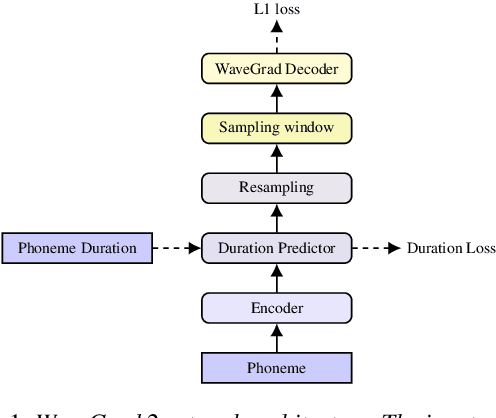
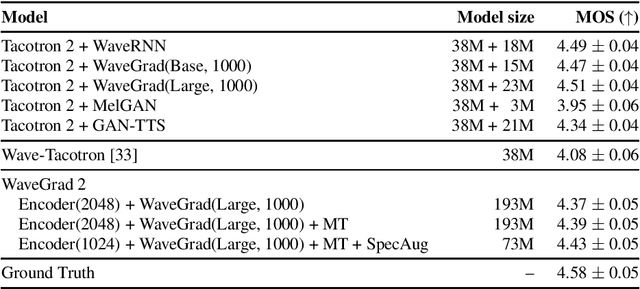
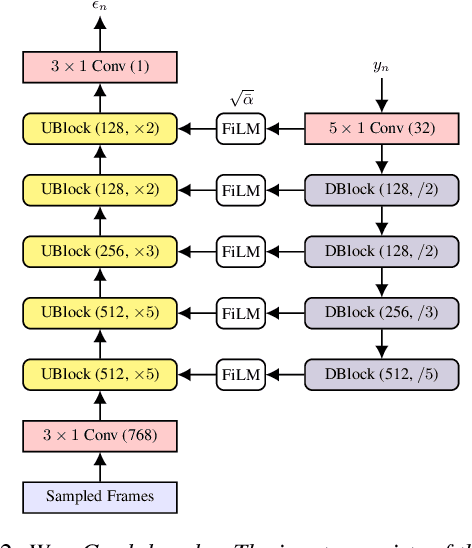

This paper introduces WaveGrad 2, a non-autoregressive generative model for text-to-speech synthesis. WaveGrad 2 is trained to estimate the gradient of the log conditional density of the waveform given a phoneme sequence. The model takes an input phoneme sequence, and through an iterative refinement process, generates an audio waveform. This contrasts to the original WaveGrad vocoder which conditions on mel-spectrogram features, generated by a separate model. The iterative refinement process starts from Gaussian noise, and through a series of refinement steps (e.g., 50 steps), progressively recovers the audio sequence. WaveGrad 2 offers a natural way to trade-off between inference speed and sample quality, through adjusting the number of refinement steps. Experiments show that the model can generate high fidelity audio, approaching the performance of a state-of-the-art neural TTS system. We also report various ablation studies over different model configurations. Audio samples are available at https://wavegrad.github.io/v2.
Sparse, Efficient, and Semantic Mixture Invariant Training: Taming In-the-Wild Unsupervised Sound Separation
Jun 01, 2021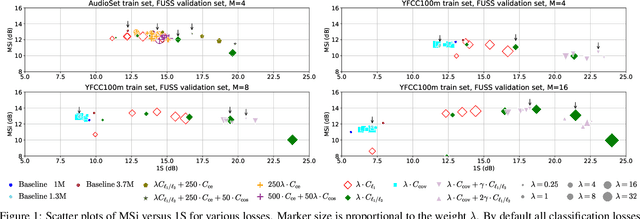
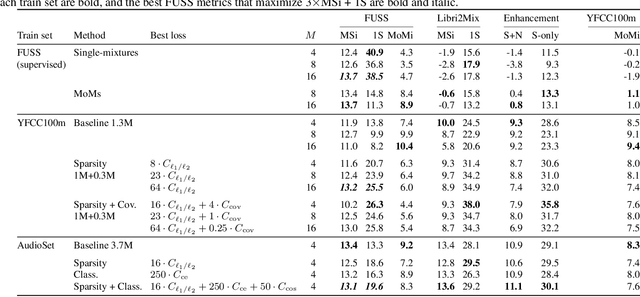
Supervised neural network training has led to significant progress on single-channel sound separation. This approach relies on ground truth isolated sources, which precludes scaling to widely available mixture data and limits progress on open-domain tasks. The recent mixture invariant training (MixIT) method enables training on in-the wild data; however, it suffers from two outstanding problems. First, it produces models which tend to over-separate, producing more output sources than are present in the input. Second, the exponential computational complexity of the MixIT loss limits the number of feasible output sources. These problems interact: increasing the number of output sources exacerbates over-separation. In this paper we address both issues. To combat over-separation we introduce new losses: sparsity losses that favor fewer output sources and a covariance loss that discourages correlated outputs. We also experiment with a semantic classification loss by predicting weak class labels for each mixture. To extend MixIT to larger numbers of sources, we introduce an efficient approximation using a fast least-squares solution, projected onto the MixIT constraint set. Our experiments show that the proposed losses curtail over-separation and improve overall performance. The best performance is achieved using larger numbers of output sources, enabled by our efficient MixIT loss, combined with sparsity losses to prevent over-separation. On the FUSS test set, we achieve over 13 dB in multi-source SI-SNR improvement, while boosting single-source reconstruction SI-SNR by over 17 dB.
Wave-Tacotron: Spectrogram-free end-to-end text-to-speech synthesis
Nov 06, 2020
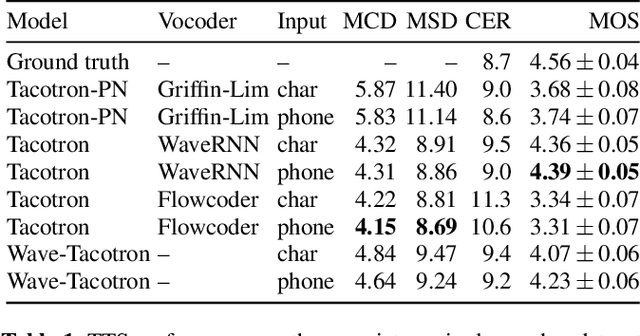
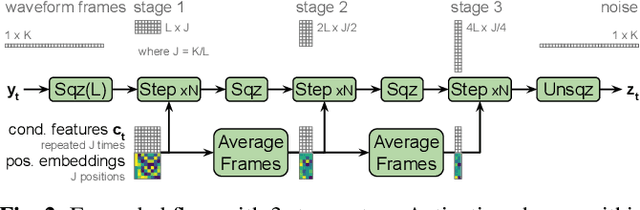
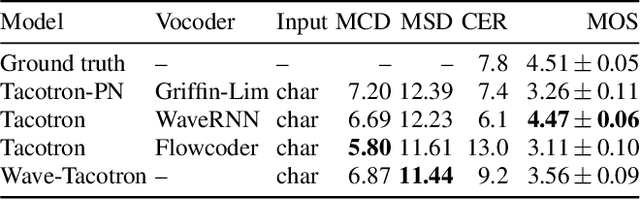
We describe a sequence-to-sequence neural network which can directly generate speech waveforms from text inputs. The architecture extends the Tacotron model by incorporating a normalizing flow into the autoregressive decoder loop. Output waveforms are modeled as a sequence of non-overlapping fixed-length frames, each one containing hundreds of samples. The interdependencies of waveform samples within each frame are modeled using the normalizing flow, enabling parallel training and synthesis. Longer-term dependencies are handled autoregressively by conditioning each flow on preceding frames. This model can be optimized directly with maximum likelihood, without using intermediate, hand-designed features nor additional loss terms. Contemporary state-of-the-art text-to-speech (TTS) systems use a cascade of separately learned models: one (such as Tacotron) which generates intermediate features (such as spectrograms) from text, followed by a vocoder (such as WaveRNN) which generates waveform samples from the intermediate features. The proposed system, in contrast, does not use a fixed intermediate representation, and learns all parameters end-to-end. Experiments show that the proposed model generates speech with quality approaching a state-of-the-art neural TTS system, with significantly improved generation speed.
Multitask Training with Text Data for End-to-End Speech Recognition
Oct 27, 2020
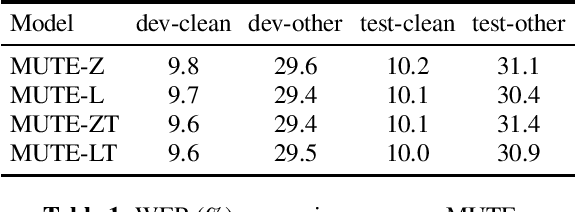

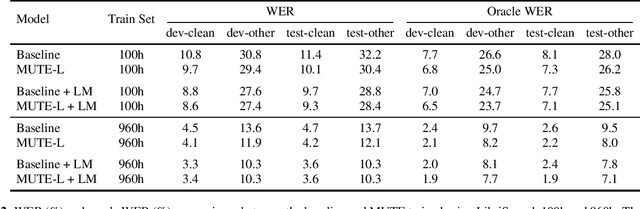
We propose a multitask training method for attention-based end-to-end speech recognition models to better incorporate language level information. We regularize the decoder in a sequence-to-sequence architecture by multitask training it on both the speech recognition task and a next-token prediction language modeling task. Trained on either the 100 hour subset of LibriSpeech or the full 960 hour dataset, the proposed method leads to an 11% relative performance improvement over the baseline and is comparable to language model shallow fusion, without requiring an additional neural network during decoding. Analyses of sample output sentences and the word error rate on rare words demonstrate that the proposed method can incorporate language level information effectively.
WaveGrad: Estimating Gradients for Waveform Generation
Sep 02, 2020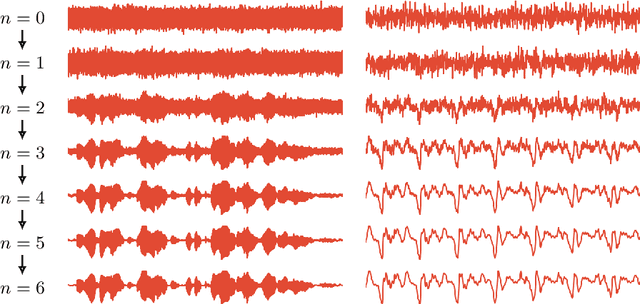
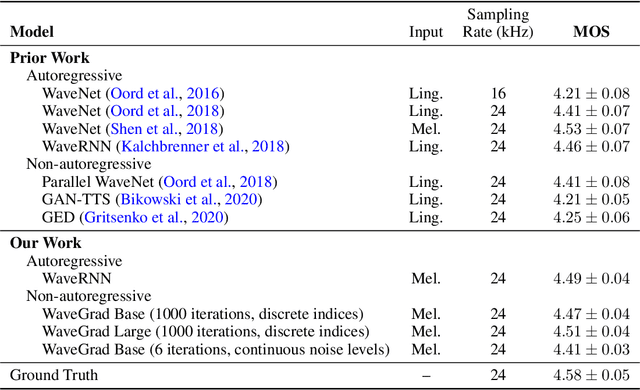
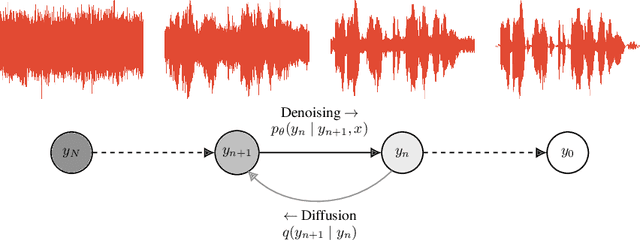

This paper introduces WaveGrad, a conditional model for waveform generation through estimating gradients of the data density. This model is built on the prior work on score matching and diffusion probabilistic models. It starts from Gaussian white noise and iteratively refines the signal via a gradient-based sampler conditioned on the mel-spectrogram. WaveGrad is non-autoregressive, and requires only a constant number of generation steps during inference. It can use as few as 6 iterations to generate high fidelity audio samples. WaveGrad is simple to train, and implicitly optimizes for the weighted variational lower-bound of the log-likelihood. Empirical experiments reveal WaveGrad to generate high fidelity audio samples matching a strong likelihood-based autoregressive baseline with less sequential operations.
Unsupervised Sound Separation Using Mixtures of Mixtures
Jun 23, 2020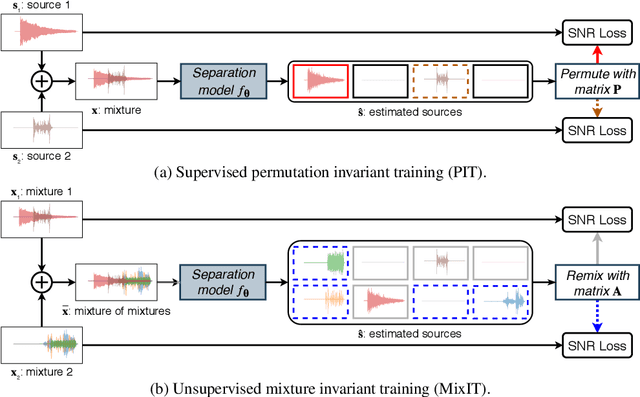
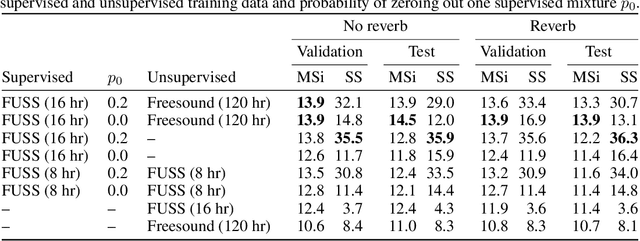
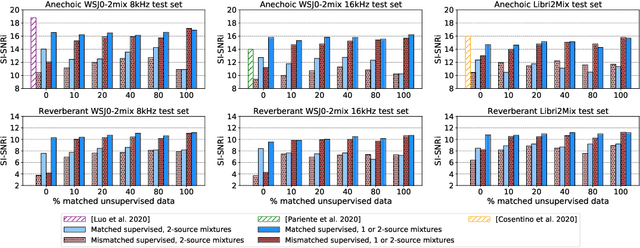
In recent years, rapid progress has been made on the problem of single-channel sound separation using supervised training of deep neural networks. In such supervised approaches, the model is trained to predict the component sources from synthetic mixtures created by adding up isolated ground-truth sources. The reliance on this synthetic training data is problematic because good performance depends upon the degree of match between the training data and real-world audio, especially in terms of the acoustic conditions and distribution of sources. The acoustic properties can be challenging to accurately simulate, and the distribution of sound types may be hard to replicate. In this paper, we propose a completely unsupervised method, mixture invariant training (MixIT), that requires only single-channel acoustic mixtures. In MixIT, training examples are constructed by mixing together existing mixtures, and the model separates them into a variable number of latent sources, such that the separated sources can be remixed to approximate the original mixtures. We show that MixIT can achieve competitive performance compared to supervised methods on speech separation. Using MixIT in a semi-supervised learning setting enables unsupervised domain adaptation and learning from large amounts of real-world data without ground-truth source waveforms. In particular, we significantly improve reverberant speech separation performance by incorporating reverberant mixtures, train a speech enhancement system from noisy mixtures, and improve universal sound separation by incorporating a large amount of in-the-wild data.
Fully-hierarchical fine-grained prosody modeling for interpretable speech synthesis
Feb 06, 2020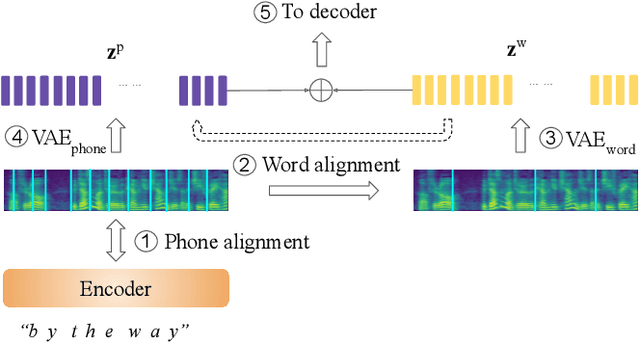
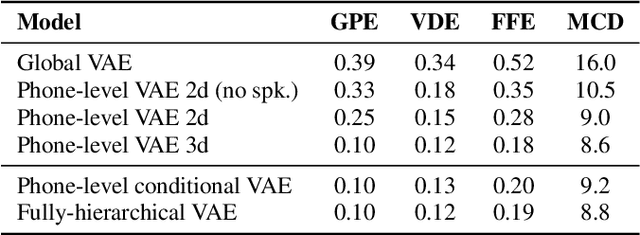
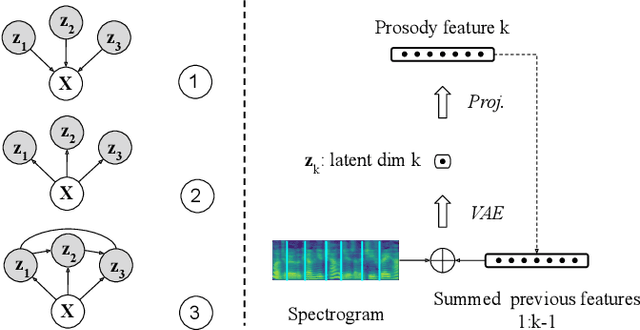
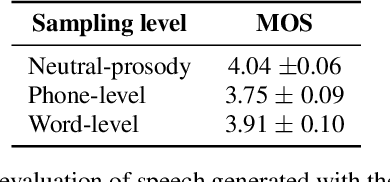
This paper proposes a hierarchical, fine-grained and interpretable latent variable model for prosody based on the Tacotron 2 text-to-speech model. It achieves multi-resolution modeling of prosody by conditioning finer level representations on coarser level ones. Additionally, it imposes hierarchical conditioning across all latent dimensions using a conditional variational auto-encoder (VAE) with an auto-regressive structure. Evaluation of reconstruction performance illustrates that the new structure does not degrade the model while allowing better interpretability. Interpretations of prosody attributes are provided together with the comparison between word-level and phone-level prosody representations. Moreover, both qualitative and quantitative evaluations are used to demonstrate the improvement in the disentanglement of the latent dimensions.
Generating diverse and natural text-to-speech samples using a quantized fine-grained VAE and auto-regressive prosody prior
Feb 06, 2020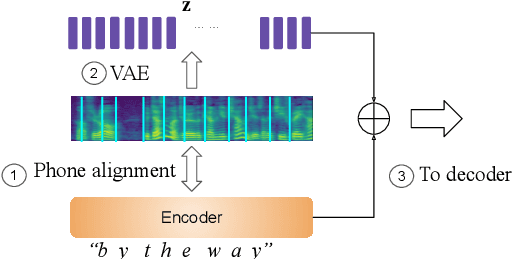
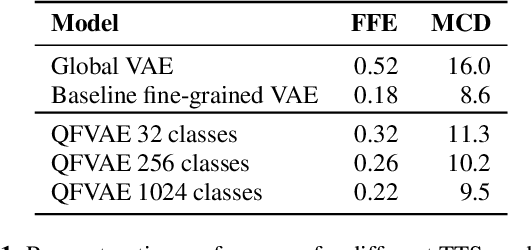
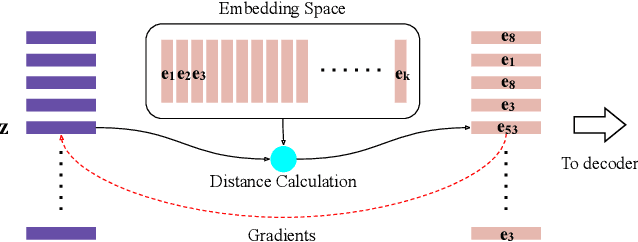
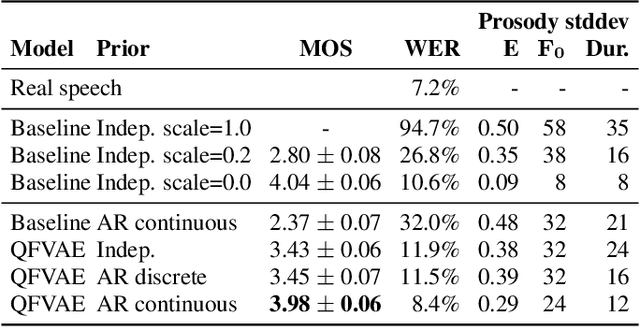
Recent neural text-to-speech (TTS) models with fine-grained latent features enable precise control of the prosody of synthesized speech. Such models typically incorporate a fine-grained variational autoencoder (VAE) structure, extracting latent features at each input token (e.g., phonemes). However, generating samples with the standard VAE prior often results in unnatural and discontinuous speech, with dramatic prosodic variation between tokens. This paper proposes a sequential prior in a discrete latent space which can generate more naturally sounding samples. This is accomplished by discretizing the latent features using vector quantization (VQ), and separately training an autoregressive (AR) prior model over the result. We evaluate the approach using listening tests, objective metrics of automatic speech recognition (ASR) performance, and measurements of prosody attributes. Experimental results show that the proposed model significantly improves the naturalness in random sample generation. Furthermore, initial experiments demonstrate that randomly sampling from the proposed model can be used as data augmentation to improve the ASR performance.