 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulS2S-LLM: Unlocking Simultaneous Inference of Speech LLMs for Speech-to-Speech Translation
Apr 22, 2025



Simultaneous speech translation (SST) outputs translations in parallel with streaming speech input, balancing translation quality and latency. While large language models (LLMs) have been extended to handle the speech modality, streaming remains challenging as speech is prepended as a prompt for the entire generation process. To unlock LLM streaming capability, this paper proposes SimulS2S-LLM, which trains speech LLMs offline and employs a test-time policy to guide simultaneous inference. SimulS2S-LLM alleviates the mismatch between training and inference by extracting boundary-aware speech prompts that allows it to be better matched with text input data. SimulS2S-LLM achieves simultaneous speech-to-speech translation (Simul-S2ST) by predicting discrete output speech tokens and then synthesising output speech using a pre-trained vocoder. An incremental beam search is designed to expand the search space of speech token prediction without increasing latency. Experiments on the CVSS speech data show that SimulS2S-LLM offers a better translation quality-latency trade-off than existing methods that use the same training data, such as improving ASR-BLEU scores by 3 points at similar latency.
CASE-Bench: Context-Aware Safety Evaluation Benchmark for Large Language Models
Jan 24, 2025



Aligning large language models (LLMs) with human values is essential for their safe deployment and widespread adoption. Current LLM safety benchmarks often focus solely on the refusal of individual problematic queries, which overlooks the importance of the context where the query occurs and may cause undesired refusal of queries under safe contexts that diminish user experience. Addressing this gap, we introduce CASE-Bench, a Context-Aware Safety Evaluation Benchmark that integrates context into safety assessments of LLMs. CASE-Bench assigns distinct, formally described contexts to categorized queries based on Contextual Integrity theory. Additionally, in contrast to previous studies which mainly rely on majority voting from just a few annotators, we recruited a sufficient number of annotators necessary to ensure the detection of statistically significant differences among the experimental conditions based on power analysis. Our extensive analysis using CASE-Bench on various open-source and commercial LLMs reveals a substantial and significant influence of context on human judgments (p<0.0001 from a z-test), underscoring the necessity of context in safety evaluations. We also identify notable mismatches between human judgments and LLM responses, particularly in commercial models within safe contexts.
Transducer-Llama: Integrating LLMs into Streamable Transducer-based Speech Recognition
Dec 21, 2024



While large language models (LLMs) have been applied to automatic speech recognition (ASR), the task of making the model streamable remains a challenge. This paper proposes a novel model architecture, Transducer-Llama, that integrates LLMs into a Factorized Transducer (FT) model, naturally enabling streaming capabilities. Furthermore, given that the large vocabulary of LLMs can cause data sparsity issue and increased training costs for spoken language systems, this paper introduces an efficient vocabulary adaptation technique to align LLMs with speech system vocabularies. The results show that directly optimizing the FT model with a strong pre-trained LLM-based predictor using the RNN-T loss yields some but limited improvements over a smaller pre-trained LM predictor. Therefore, this paper proposes a weak-to-strong LM swap strategy, using a weak LM predictor during RNN-T loss training and then replacing it with a strong LLM. After LM replacement, the minimum word error rate (MWER) loss is employed to finetune the integration of the LLM predictor with the Transducer-Llama model. Experiments on the LibriSpeech and large-scale multi-lingual LibriSpeech corpora show that the proposed streaming Transducer-Llama approach gave a 17% relative WER reduction (WERR) over a strong FT baseline and a 32% WERR over an RNN-T baseline.
Confidence Estimation for Automatic Detection of Depression and Alzheimer's Disease Based on Clinical Interviews
Jul 29, 2024



Speech-based automatic detection of Alzheimer's disease (AD) and depression has attracted increased attention. Confidence estimation is crucial for a trust-worthy automatic diagnostic system which informs the clinician about the confidence of model predictions and helps reduce the risk of misdiagnosis. This paper investigates confidence estimation for automatic detection of AD and depression based on clinical interviews. A novel Bayesian approach is proposed which uses a dynamic Dirichlet prior distribution to model the second-order probability of the predictive distribution. Experimental results on the publicly available ADReSS and DAIC-WOZ datasets demonstrate that the proposed method outperforms a range of baselines for both classification accuracy and confidence estimation.
SOT Triggered Neural Clustering for Speaker Attributed ASR
Jul 02, 2024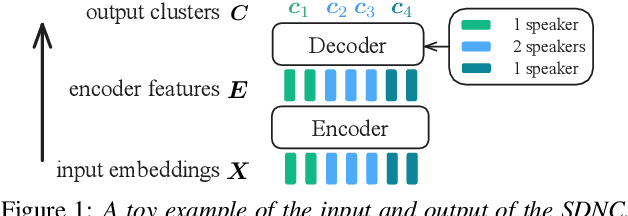
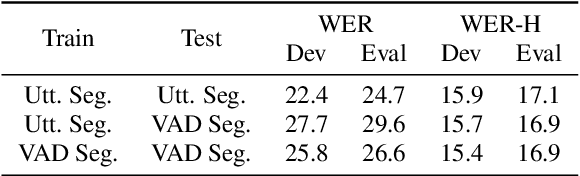
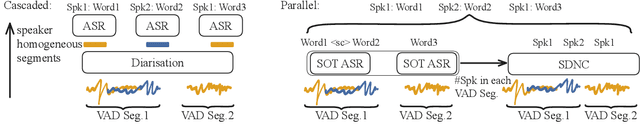

This paper introduces a novel approach to speaker-attributed ASR transcription using a neural clustering method. With a parallel processing mechanism, diarisation and ASR can be applied simultaneously, helping to prevent the accumulation of errors from one sub-system to the next in a cascaded system. This is achieved by the use of ASR, trained using a serialised output training method, together with segment-level discriminative neural clustering (SDNC) to assign speaker labels. With SDNC, our system does not require an extra non-neural clustering method to assign speaker labels, thus allowing the entire system to be based on neural networks. Experimental results on the AMI meeting dataset demonstrate that SDNC outperforms spectral clustering (SC) by a 19% relative diarisation error rate (DER) reduction on the AMI Eval set. When compared with the cascaded system with SC, the parallel system with SDNC gives a 7%/4% relative improvement in cpWER on the Dev/Eval set.
Label-Synchronous Neural Transducer for E2E Simultaneous Speech Translation
Jun 06, 2024



While the neural transducer is popular for online speech recognition, simultaneous speech translation (SST) requires both streaming and re-ordering capabilities. This paper presents the LS-Transducer-SST, a label-synchronous neural transducer for SST, which naturally possesses these two properties. The LS-Transducer-SST dynamically decides when to emit translation tokens based on an Auto-regressive Integrate-and-Fire (AIF) mechanism. A latency-controllable AIF is also proposed, which can control the quality-latency trade-off either only during decoding, or it can be used in both decoding and training. The LS-Transducer-SST can naturally utilise monolingual text-only data via its prediction network which helps alleviate the key issue of data sparsity for E2E SST. During decoding, a chunk-based incremental joint decoding technique is designed to refine and expand the search space. Experiments on the Fisher-CallHome Spanish (Es-En) and MuST-C En-De data show that the LS-Transducer-SST gives a better quality-latency trade-off than existing popular methods. For example, the LS-Transducer-SST gives a 3.1/2.9 point BLEU increase (Es-En/En-De) relative to CAAT at a similar latency and a 1.4 s reduction in average lagging latency with similar BLEU scores relative to Wait-k.
Wav2Prompt: End-to-End Speech Prompt Generation and Tuning For LLM in Zero and Few-shot Learning
Jun 01, 2024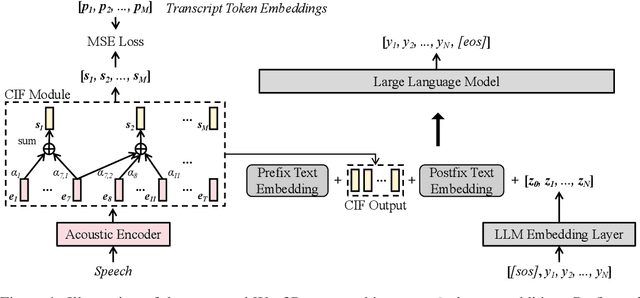
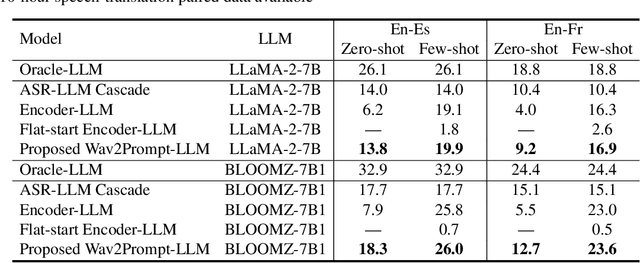


Wav2Prompt is proposed which allows straightforward integration between spoken input and a text-based large language model (LLM). Wav2Prompt uses a simple training process with only the same data used to train an automatic speech recognition (ASR) model. After training, Wav2Prompt learns continuous representations from speech and uses them as LLM prompts. To avoid task over-fitting issues found in prior work and preserve the emergent abilities of LLMs, Wav2Prompt takes LLM token embeddings as the training targets and utilises a continuous integrate-and-fire mechanism for explicit speech-text alignment. Therefore, a Wav2Prompt-LLM combination can be applied to zero-shot spoken language tasks such as speech translation (ST), speech understanding (SLU), speech question answering (SQA) and spoken-query-based QA (SQQA). It is shown that for these zero-shot tasks, Wav2Prompt performs similarly to an ASR-LLM cascade and better than recent prior work. If relatively small amounts of task-specific paired data are available in few-shot scenarios, the Wav2Prompt-LLM combination can be end-to-end (E2E) fine-tuned. The Wav2Prompt-LLM combination then yields greatly improved results relative to an ASR-LLM cascade for the above tasks. For instance, for English-French ST with the BLOOMZ-7B1 LLM, a Wav2Prompt-LLM combination gave a 8.5 BLEU point increase over an ASR-LLM cascade.
1st Place Solution to Odyssey Emotion Recognition Challenge Task1: Tackling Class Imbalance Problem
May 30, 2024



Speech emotion recognition is a challenging classification task with natural emotional speech, especially when the distribution of emotion types is imbalanced in the training and test data. In this case, it is more difficult for a model to learn to separate minority classes, resulting in those sometimes being ignored or frequently misclassified. Previous work has utilised class weighted loss for training, but problems remain as it sometimes causes over-fitting for minor classes or under-fitting for major classes. This paper presents the system developed by a multi-site team for the participation in the Odyssey 2024 Emotion Recognition Challenge Track-1. The challenge data has the aforementioned properties and therefore the presented systems aimed to tackle these issues, by introducing focal loss in optimisation when applying class weighted loss. Specifically, the focal loss is further weighted by prior-based class weights. Experimental results show that combining these two approaches brings better overall performance, by sacrificing performance on major classes. The system further employs a majority voting strategy to combine the outputs of an ensemble of 7 models. The models are trained independently, using different acoustic features and loss functions - with the aim to have different properties for different data. Hence these models show different performance preferences on major classes and minor classes. The ensemble system output obtained the best performance in the challenge, ranking top-1 among 68 submissions. It also outperformed all single models in our set. On the Odyssey 2024 Emotion Recognition Challenge Task-1 data the system obtained a Macro-F1 score of 35.69% and an accuracy of 37.32%.
Handling Ambiguity in Emotion: From Out-of-Domain Detection to Distribution Estimation
Feb 20, 2024



The subjective perception of emotion leads to inconsistent labels from human annotators. Typically, utterances lacking majority-agreed labels are excluded when training an emotion classifier, which cause problems when encountering ambiguous emotional expressions during testing. This paper investigates three methods to handle ambiguous emotion. First, we show that incorporating utterances without majority-agreed labels as an additional class in the classifier reduces the classification performance of the other emotion classes. Then, we propose detecting utterances with ambiguous emotions as out-of-domain samples by quantifying the uncertainty in emotion classification using evidential deep learning. This approach retains the classification accuracy while effectively detects ambiguous emotion expressions. Furthermore, to obtain fine-grained distinctions among ambiguous emotions, we propose representing emotion as a distribution instead of a single class label. The task is thus re-framed from classification to distribution estimation where every individual annotation is taken into account, not just the majority opinion. The evidential uncertainty measure is extended to quantify the uncertainty in emotion distribution estimation. Experimental results on the IEMOCAP and CREMA-D datasets demonstrate the superior capability of the proposed method in terms of majority class prediction, emotion distribution estimation, and uncertainty estimation.
Parameter Efficient Finetuning for Speech Emotion Recognition and Domain Adaptation
Feb 19, 2024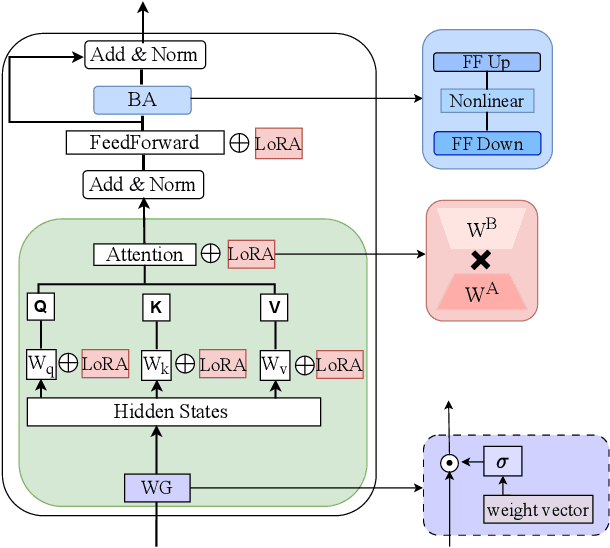
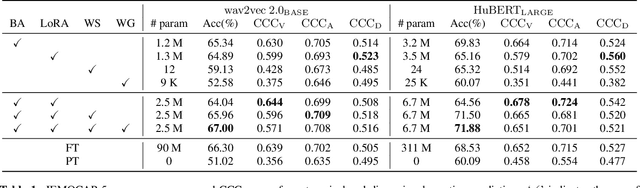
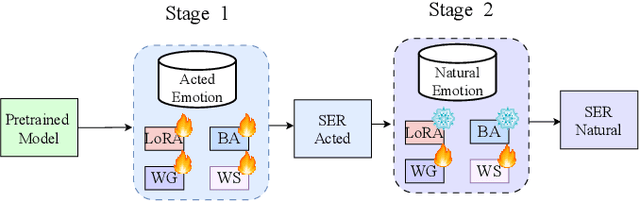
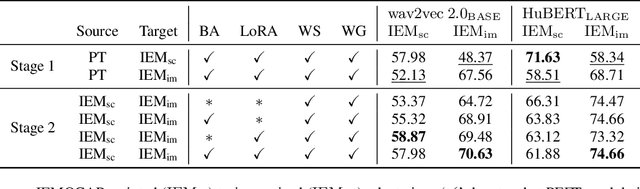
Foundation models have shown superior performance for speech emotion recognition (SER). However, given the limited data in emotion corpora, finetuning all parameters of large pre-trained models for SER can be both resource-intensive and susceptible to overfitting. This paper investigates parameter-efficient finetuning (PEFT) for SER. Various PEFT adaptors are systematically studied for both classification of discrete emotion categories and prediction of dimensional emotional attributes. The results demonstrate that the combination of PEFT methods surpasses full finetuning with a significant reduction in the number of trainable parameters. Furthermore, a two-stage adaptation strategy is proposed to adapt models trained on acted emotion data, which is more readily available, to make the model more adept at capturing natural emotional expressions. Both intra- and cross-corpus experiments validate the efficacy of the proposed approach in enhancing the performance on both the source and target domains.