 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRNN-T Models Fail to Generalize to Out-of-Domain Audio: Causes and Solutions
May 17, 2020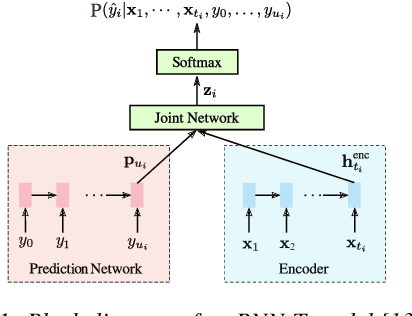
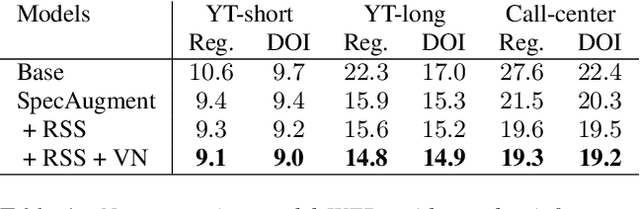
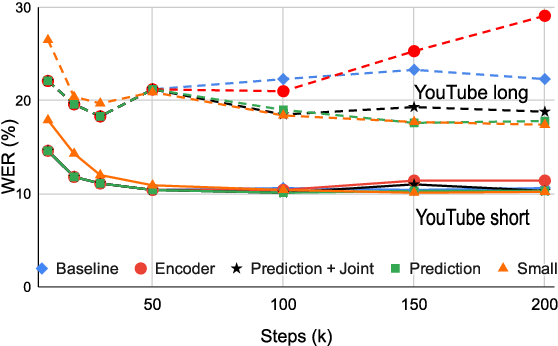
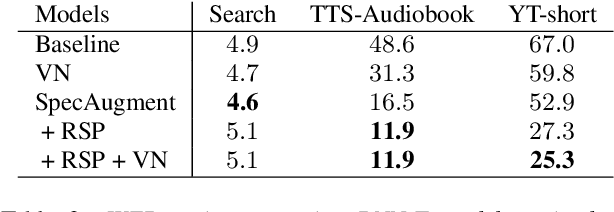
In recent years, all-neural end-to-end approaches have obtained state-of-the-art results on several challenging automatic speech recognition (ASR) tasks. However, most existing works focus on building ASR models where train and test data are drawn from the same domain. This results in poor generalization characteristics on mismatched-domains: e.g., end-to-end models trained on short segments perform poorly when evaluated on longer utterances. In this work, we analyze the generalization properties of streaming and non-streaming recurrent neural network transducer (RNN-T) based end-to-end models in order to identify model components that negatively affect generalization performance. We propose two solutions: combining multiple regularization techniques during training, and using dynamic overlapping inference. On a long-form YouTube test set, when the non-streaming RNN-T model is trained with shorter segments of data, the proposed combination improves word error rate (WER) from 22.3% to 14.8%; when the streaming RNN-T model trained on short Search queries, the proposed techniques improve WER on the YouTube set from 67.0% to 25.3%. Finally, when trained on Librispeech, we find that dynamic overlapping inference improves WER on YouTube from 99.8% to 33.0%.
A comparison of end-to-end models for long-form speech recognition
Nov 06, 2019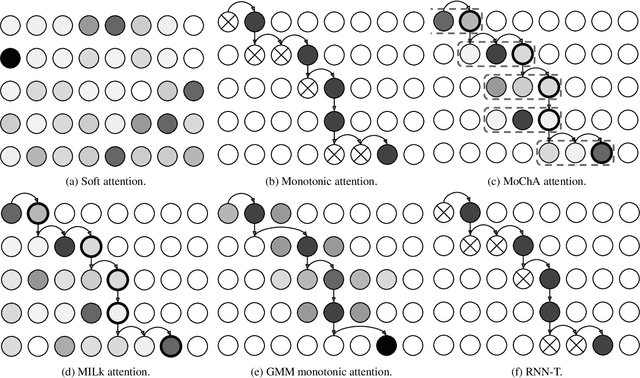

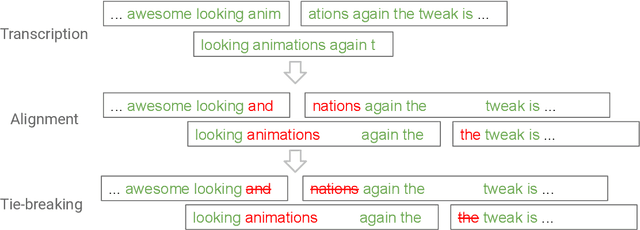
End-to-end automatic speech recognition (ASR) models, including both attention-based models and the recurrent neural network transducer (RNN-T), have shown superior performance compared to conventional systems. However, previous studies have focused primarily on short utterances that typically last for just a few seconds or, at most, a few tens of seconds. Whether such architectures are practical on long utterances that last from minutes to hours remains an open question. In this paper, we both investigate and improve the performance of end-to-end models on long-form transcription. We first present an empirical comparison of different end-to-end models on a real world long-form task and demonstrate that the RNN-T model is much more robust than attention-based systems in this regime. We next explore two improvements to attention-based systems that significantly improve its performance: restricting the attention to be monotonic, and applying a novel decoding algorithm that breaks long utterances into shorter overlapping segments. Combining these two improvements, we show that attention-based end-to-end models can be very competitive to RNN-T on long-form speech recognition.
StarNet: Targeted Computation for Object Detection in Point Clouds
Aug 29, 2019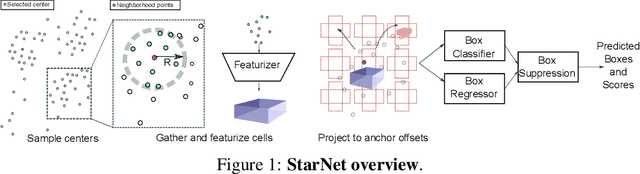
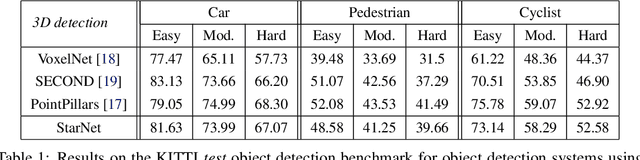
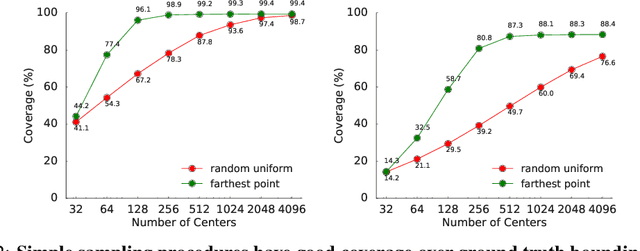
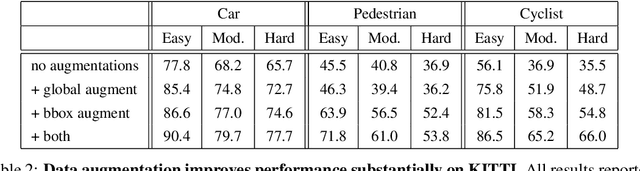
LiDAR sensor systems provide high resolution spatial information about the environment for self-driving cars. Therefore, detecting objects from point clouds derived from LiDAR represents a critical problem. Previous work on object detection from LiDAR has emphasized re-purposing convolutional approaches from traditional camera imagery. In this work, we present an object detection system designed specifically for point cloud data blending aspects of one-stage and two-stage systems. We observe that objects in point clouds are quite distinct from traditional camera images: objects are sparse and vary widely in location, but do not exhibit scale distortions observed in single camera perspective. These two observations suggest that simple and cheap data-driven object proposals to maximize spatial coverage or match the observed densities of point cloud data may suffice. This recognition paired with a local, non-convolutional, point-based network permits building an object detector for point clouds that may be trained only once, but adapted to different computational settings -- targeted to different predictive priorities or spatial regions. We demonstrate this flexibility and the targeted detection strategies on both the KITTI detection dataset as well as on the large-scale Waymo Open Dataset. Furthermore, we find that a single network is competitive with other point cloud detectors across a range of computational budgets, while being more flexible to adapt to contextual priorities.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Model Unit Exploration for Sequence-to-Sequence Speech Recognition
Feb 05, 2019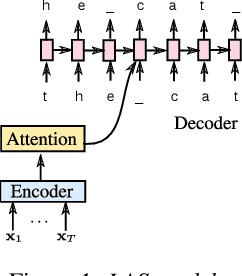
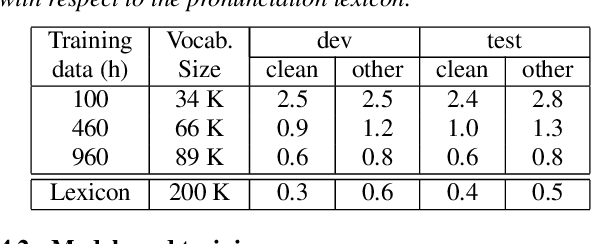
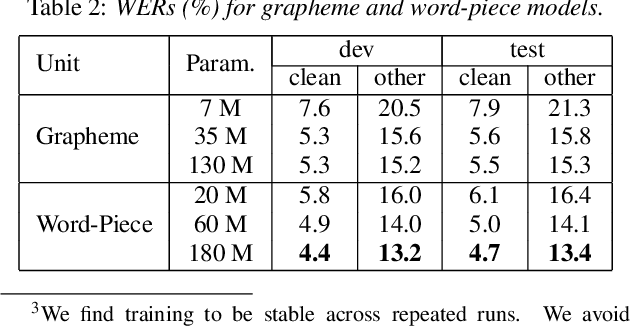
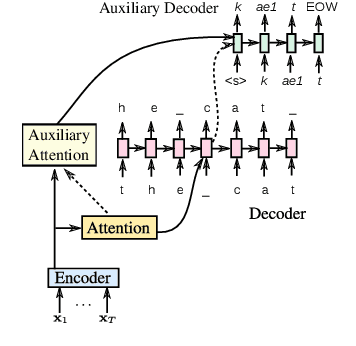
We evaluate attention-based encoder-decoder models along two dimensions: choice of target unit (phoneme, grapheme, and word-piece), and the amount of available training data. We conduct experiments on the LibriSpeech 100hr, 460hr, and 960hr tasks; across all tasks, we find that grapheme or word-piece models consistently outperform phoneme-based models, even though they are evaluated without a lexicon or an external language model. On the 960hr task the word-piece model achieves a word error rate (WER) of 4.7% on the test-clean set and 13.4% on the test-other set, which improves to 3.6% (clean) and 10.3% (other) when decoded with an LSTM LM: the lowest reported numbers using sequence-to-sequence models. We also conduct a detailed analysis of the various models, and investigate their complementarity: we find that we can improve WERs by up to 9% relative by rescoring N-best lists generated from the word-piece model with either the phoneme or the grapheme model. Rescoring an N-best list generated by the phonemic system, however, provides limited improvements. Further analysis shows that the word-piece-based models produce more diverse N-best hypotheses, resulting in lower oracle WERs, than the phonemic system.
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis
Nov 05, 2018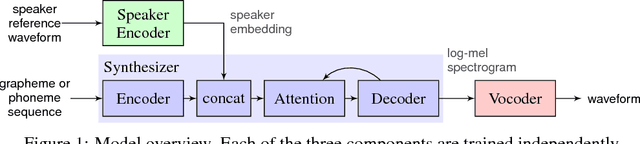

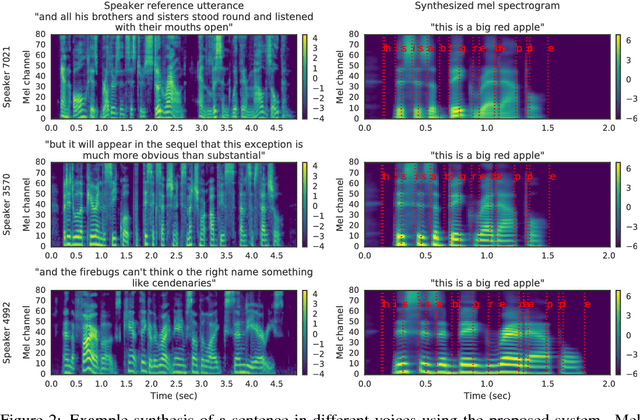
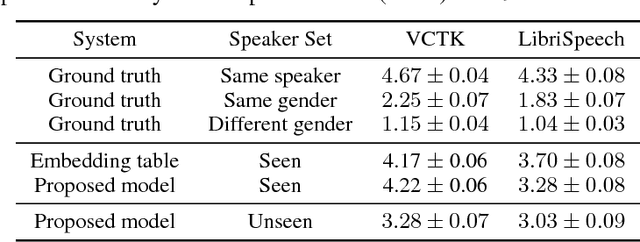
We describe a neural network-based system for text-to-speech (TTS) synthesis that is able to generate speech audio in the voice of many different speakers, including those unseen during training. Our system consists of three independently trained components: (1) a speaker encoder network, trained on a speaker verification task using an independent dataset of noisy speech from thousands of speakers without transcripts, to generate a fixed-dimensional embedding vector from seconds of reference speech from a target speaker; (2) a sequence-to-sequence synthesis network based on Tacotron 2, which generates a mel spectrogram from text, conditioned on the speaker embedding; (3) an auto-regressive WaveNet-based vocoder that converts the mel spectrogram into a sequence of time domain waveform samples. We demonstrate that the proposed model is able to transfer the knowledge of speaker variability learned by the discriminatively-trained speaker encoder to the new task, and is able to synthesize natural speech from speakers that were not seen during training. We quantify the importance of training the speaker encoder on a large and diverse speaker set in order to obtain the best generalization performance. Finally, we show that randomly sampled speaker embeddings can be used to synthesize speech in the voice of novel speakers dissimilar from those used in training, indicating that the model has learned a high quality speaker representation.
Hierarchical Generative Modeling for Controllable Speech Synthesis
Oct 16, 2018
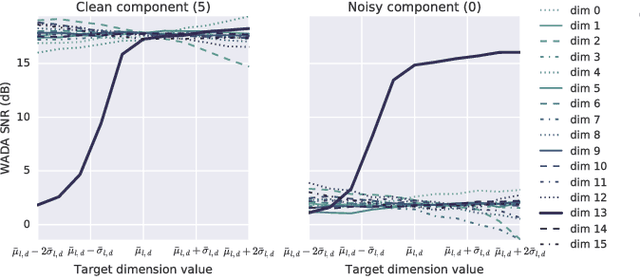
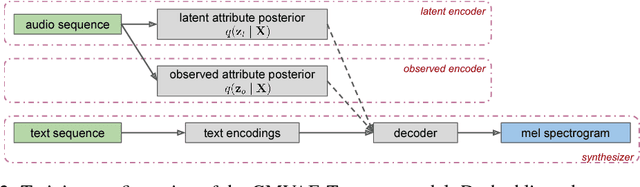

This paper proposes a neural end-to-end text-to-speech (TTS) model which can control latent attributes in the generated speech that are rarely annotated in the training data, such as speaking style, accent, background noise, and recording conditions. The model is formulated as a conditional generative model with two levels of hierarchical latent variables. The first level is a categorical variable, which represents attribute groups (e.g. clean/noisy) and provides interpretability. The second level, conditioned on the first, is a multivariate Gaussian variable, which characterizes specific attribute configurations (e.g. noise level, speaking rate) and enables disentangled fine-grained control over these attributes. This amounts to using a Gaussian mixture model (GMM) for the latent distribution. Extensive evaluation demonstrates its ability to control the aforementioned attributes. In particular, it is capable of consistently synthesizing high-quality clean speech regardless of the quality of the training data for the target speaker.
Speech recognition for medical conversations
Jun 20, 2018
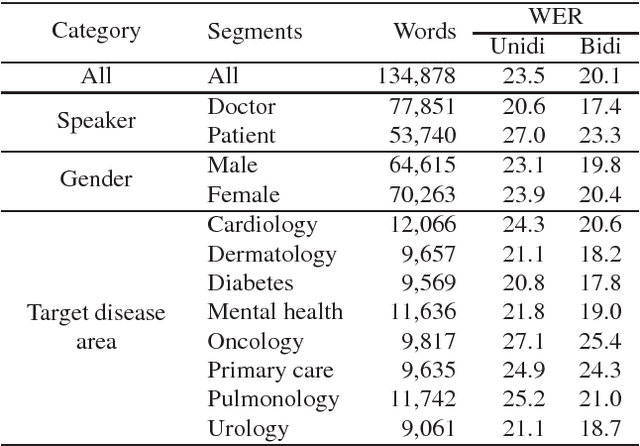
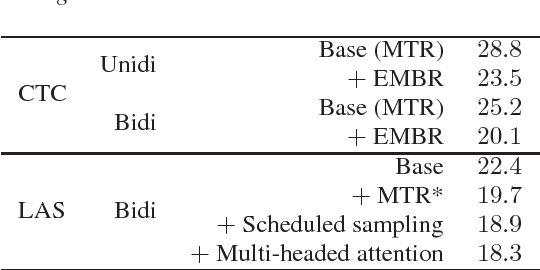
In this work we explored building automatic speech recognition models for transcribing doctor patient conversation. We collected a large scale dataset of clinical conversations ($14,000$ hr), designed the task to represent the real word scenario, and explored several alignment approaches to iteratively improve data quality. We explored both CTC and LAS systems for building speech recognition models. The LAS was more resilient to noisy data and CTC required more data clean up. A detailed analysis is provided for understanding the performance for clinical tasks. Our analysis showed the speech recognition models performed well on important medical utterances, while errors occurred in causal conversations. Overall we believe the resulting models can provide reasonable quality in practice.
State-of-the-art Speech Recognition With Sequence-to-Sequence Models
Feb 23, 2018
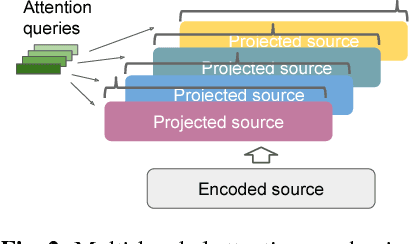
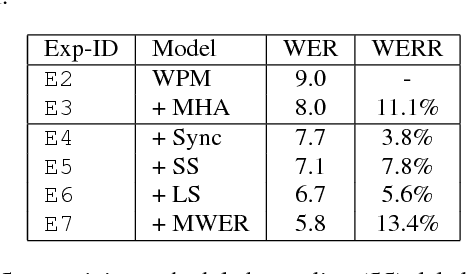
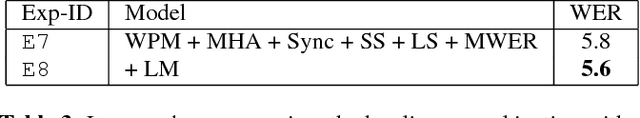
Attention-based encoder-decoder architectures such as Listen, Attend, and Spell (LAS), subsume the acoustic, pronunciation and language model components of a traditional automatic speech recognition (ASR) system into a single neural network. In previous work, we have shown that such architectures are comparable to state-of-theart ASR systems on dictation tasks, but it was not clear if such architectures would be practical for more challenging tasks such as voice search. In this work, we explore a variety of structural and optimization improvements to our LAS model which significantly improve performance. On the structural side, we show that word piece models can be used instead of graphemes. We also introduce a multi-head attention architecture, which offers improvements over the commonly-used single-head attention. On the optimization side, we explore synchronous training, scheduled sampling, label smoothing, and minimum word error rate optimization, which are all shown to improve accuracy. We present results with a unidirectional LSTM encoder for streaming recognition. On a 12, 500 hour voice search task, we find that the proposed changes improve the WER from 9.2% to 5.6%, while the best conventional system achieves 6.7%; on a dictation task our model achieves a WER of 4.1% compared to 5% for the conventional system.
An analysis of incorporating an external language model into a sequence-to-sequence model
Dec 06, 2017

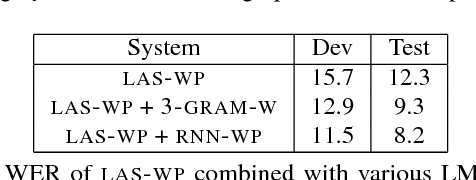

Attention-based sequence-to-sequence models for automatic speech recognition jointly train an acoustic model, language model, and alignment mechanism. Thus, the language model component is only trained on transcribed audio-text pairs. This leads to the use of shallow fusion with an external language model at inference time. Shallow fusion refers to log-linear interpolation with a separately trained language model at each step of the beam search. In this work, we investigate the behavior of shallow fusion across a range of conditions: different types of language models, different decoding units, and different tasks. On Google Voice Search, we demonstrate that the use of shallow fusion with a neural LM with wordpieces yields a 9.1% relative word error rate reduction (WERR) over our competitive attention-based sequence-to-sequence model, obviating the need for second-pass rescoring.