 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo One Left Behind: How to Exploit the Incomplete and Skewed Multi-Label Data for Conversion Rate Prediction
Dec 15, 2025



In most real-world online advertising systems, advertisers typically have diverse customer acquisition goals. A common solution is to use multi-task learning (MTL) to train a unified model on post-click data to estimate the conversion rate (CVR) for these diverse targets. In practice, CVR prediction often encounters missing conversion data as many advertisers submit only a subset of user conversion actions due to privacy or other constraints, making the labels of multi-task data incomplete. If the model is trained on all available samples where advertisers submit user conversion actions, it may struggle when deployed to serve a subset of advertisers targeting specific conversion actions, as the training and deployment data distributions are mismatched. While considerable MTL efforts have been made, a long-standing challenge is how to effectively train a unified model with the incomplete and skewed multi-label data. In this paper, we propose a fine-grained Knowledge transfer framework for Asymmetric Multi-Label data (KAML). We introduce an attribution-driven masking strategy (ADM) to better utilize data with asymmetric multi-label data in training. However, the more relaxed masking in ADM is a double-edged sword: it provides additional training signals but also introduces noise due to skewed data. To address this, we propose a hierarchical knowledge extraction mechanism (HKE) to model the sample discrepancy within the target task tower. Finally, to maximize the utility of unlabeled samples, we incorporate ranking loss strategy to further enhance our model. The effectiveness of KAML has been demonstrated through comprehensive evaluations on offline industry datasets and online A/B tests, which show significant performance improvements over existing MTL baselines.
MGFRec: Towards Reinforced Reasoning Recommendation with Multiple Groundings and Feedback
Oct 27, 2025



The powerful reasoning and generative capabilities of large language models (LLMs) have inspired researchers to apply them to reasoning-based recommendation tasks, which require in-depth reasoning about user interests and the generation of recommended items. However, previous reasoning-based recommendation methods have typically performed inference within the language space alone, without incorporating the actual item space. This has led to over-interpreting user interests and deviating from real items. Towards this research gap, we propose performing multiple rounds of grounding during inference to help the LLM better understand the actual item space, which could ensure that its reasoning remains aligned with real items. Furthermore, we introduce a user agent that provides feedback during each grounding step, enabling the LLM to better recognize and adapt to user interests. Comprehensive experiments conducted on three Amazon review datasets demonstrate the effectiveness of incorporating multiple groundings and feedback. These findings underscore the critical importance of reasoning within the actual item space, rather than being confined to the language space, for recommendation tasks.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneLoc: Geo-Aware Generative Recommender Systems for Local Life Service
Aug 20, 2025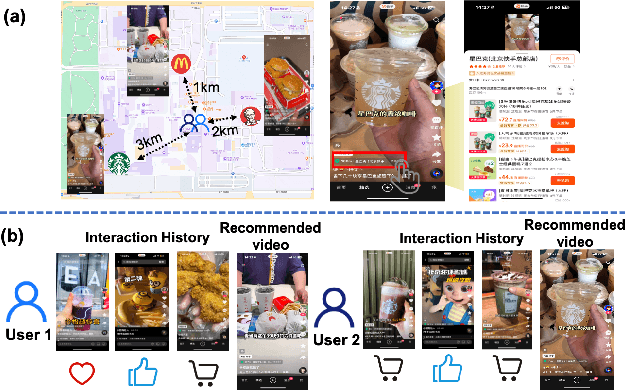
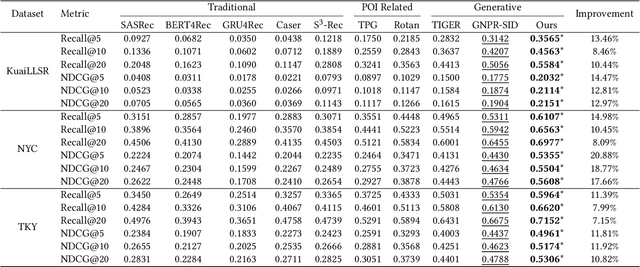
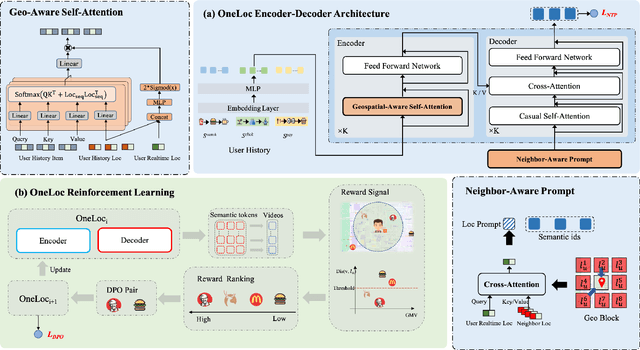

Local life service is a vital scenario in Kuaishou App, where video recommendation is intrinsically linked with store's location information. Thus, recommendation in our scenario is challenging because we should take into account user's interest and real-time location at the same time. In the face of such complex scenarios, end-to-end generative recommendation has emerged as a new paradigm, such as OneRec in the short video scenario, OneSug in the search scenario, and EGA in the advertising scenario. However, in local life service, an end-to-end generative recommendation model has not yet been developed as there are some key challenges to be solved. The first challenge is how to make full use of geographic information. The second challenge is how to balance multiple objectives, including user interests, the distance between user and stores, and some other business objectives. To address the challenges, we propose OneLoc. Specifically, we leverage geographic information from different perspectives: (1) geo-aware semantic ID incorporates both video and geographic information for tokenization, (2) geo-aware self-attention in the encoder leverages both video location similarity and user's real-time location, and (3) neighbor-aware prompt captures rich context information surrounding users for generation. To balance multiple objectives, we use reinforcement learning and propose two reward functions, i.e., geographic reward and GMV reward. With the above design, OneLoc achieves outstanding offline and online performance. In fact, OneLoc has been deployed in local life service of Kuaishou App. It serves 400 million active users daily, achieving 21.016% and 17.891% improvements in terms of gross merchandise value (GMV) and orders numbers.
Generative Representational Learning of Foundation Models for Recommendation
Jun 16, 2025Developing a single foundation model with the capability to excel across diverse tasks has been a long-standing objective in the field of artificial intelligence. As the wave of general-purpose foundation models sweeps across various domains, their influence has significantly extended to the field of recommendation systems. While recent efforts have explored recommendation foundation models for various generative tasks, they often overlook crucial embedding tasks and struggle with the complexities of multi-task learning, including knowledge sharing & conflict resolution, and convergence speed inconsistencies. To address these limitations, we introduce RecFound, a generative representational learning framework for recommendation foundation models. We construct the first comprehensive dataset for recommendation foundation models covering both generative and embedding tasks across diverse scenarios. Based on this dataset, we propose a novel multi-task training scheme featuring a Task-wise Mixture of Low-rank Experts (TMoLE) to handle knowledge sharing & conflict, a Step-wise Convergence-oriented Sample Scheduler (S2Sched) to address inconsistent convergence, and a Model Merge module to balance the performance across tasks. Experiments demonstrate that RecFound achieves state-of-the-art performance across various recommendation tasks, outperforming existing baselines.
Humanity's Last Code Exam: Can Advanced LLMs Conquer Human's Hardest Code Competition?
Jun 15, 2025Code generation is a core capability of large language models (LLMs), yet mainstream benchmarks (e.g., APPs and LiveCodeBench) contain questions with medium-level difficulty and pose no challenge to advanced LLMs. To better reflected the advanced reasoning and code generation ability, We introduce Humanity's Last Code Exam (HLCE), comprising 235 most challenging problems from the International Collegiate Programming Contest (ICPC World Finals) and the International Olympiad in Informatics (IOI) spanning 2010 - 2024. As part of HLCE, we design a harmonized online-offline sandbox that guarantees fully reproducible evaluation. Through our comprehensive evaluation, we observe that even the strongest reasoning LLMs: o4-mini(high) and Gemini-2.5 Pro, achieve pass@1 rates of only 15.9% and 11.4%, respectively. Meanwhile, we propose a novel "self-recognition" task to measure LLMs' awareness of their own capabilities. Results indicate that LLMs' self-recognition abilities are not proportionally correlated with their code generation performance. Finally, our empirical validation of test-time scaling laws reveals that current advanced LLMs have substantial room for improvement on complex programming tasks. We expect HLCE to become a milestone challenge for code generation and to catalyze advances in high-performance reasoning and human-AI collaborative programming. Our code and dataset are also public available(https://github.com/Humanity-s-Last-Code-Exam/HLCE).
Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
Pangu Light: Weight Re-Initialization for Pruning and Accelerating LLMs
May 26, 2025



Large Language Models (LLMs) deliver state-of-the-art capabilities across numerous tasks, but their immense size and inference costs pose significant computational challenges for practical deployment. While structured pruning offers a promising avenue for model compression, existing methods often struggle with the detrimental effects of aggressive, simultaneous width and depth reductions, leading to substantial performance degradation. This paper argues that a critical, often overlooked, aspect in making such aggressive joint pruning viable is the strategic re-initialization and adjustment of remaining weights to improve the model post-pruning training accuracies. We introduce Pangu Light, a framework for LLM acceleration centered around structured pruning coupled with novel weight re-initialization techniques designed to address this ``missing piece''. Our framework systematically targets multiple axes, including model width, depth, attention heads, and RMSNorm, with its effectiveness rooted in novel re-initialization methods like Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP) that mitigate performance drops by providing the network a better training starting point. Further enhancing efficiency, Pangu Light incorporates specialized optimizations such as absorbing Post-RMSNorm computations and tailors its strategies to Ascend NPU characteristics. The Pangu Light models consistently exhibit a superior accuracy-efficiency trade-off, outperforming prominent baseline pruning methods like Nemotron and established LLMs like Qwen3 series. For instance, on Ascend NPUs, Pangu Light-32B's 81.6 average score and 2585 tokens/s throughput exceed Qwen3-32B's 80.9 average score and 2225 tokens/s.
Towards Multi-Granularity Memory Association and Selection for Long-Term Conversational Agents
May 26, 2025Large Language Models (LLMs) have recently been widely adopted in conversational agents. However, the increasingly long interactions between users and agents accumulate extensive dialogue records, making it difficult for LLMs with limited context windows to maintain a coherent long-term dialogue memory and deliver personalized responses. While retrieval-augmented memory systems have emerged to address this issue, existing methods often depend on single-granularity memory segmentation and retrieval. This approach falls short in capturing deep memory connections, leading to partial retrieval of useful information or substantial noise, resulting in suboptimal performance. To tackle these limits, we propose MemGAS, a framework that enhances memory consolidation by constructing multi-granularity association, adaptive selection, and retrieval. MemGAS is based on multi-granularity memory units and employs Gaussian Mixture Models to cluster and associate new memories with historical ones. An entropy-based router adaptively selects optimal granularity by evaluating query relevance distributions and balancing information completeness and noise. Retrieved memories are further refined via LLM-based filtering. Experiments on four long-term memory benchmarks demonstrate that MemGAS outperforms state-of-the-art methods on both question answer and retrieval tasks, achieving superior performance across different query types and top-K settings.
The Real Barrier to LLM Agent Usability is Agentic ROI
May 23, 2025Large Language Model (LLM) agents represent a promising shift in human-AI interaction, moving beyond passive prompt-response systems to autonomous agents capable of reasoning, planning, and goal-directed action. Despite the widespread application in specialized, high-effort tasks like coding and scientific research, we highlight a critical usability gap in high-demand, mass-market applications. This position paper argues that the limited real-world adoption of LLM agents stems not only from gaps in model capabilities, but also from a fundamental tradeoff between the value an agent can provide and the costs incurred during real-world use. Hence, we call for a shift from solely optimizing model performance to a broader, utility-driven perspective: evaluating agents through the lens of the overall agentic return on investment (Agent ROI). By identifying key factors that determine Agentic ROI--information quality, agent time, and cost--we posit a zigzag development trajectory in optimizing agentic ROI: first scaling up to improve the information quality, then scaling down to minimize the time and cost. We outline the roadmap across different development stages to bridge the current usability gaps, aiming to make LLM agents truly scalable, accessible, and effective in real-world contexts.