 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCONCAT: Consensus- and Confidence-Driven Ad Hoc Teaming for Efficient LLM-Based Multi-Agent Systems
May 28, 2026Although large language model (LLM) based multi-agent systems (MAS) show their capability to solve complex tasks and achieve higher performance over single agent systems, they lead to huge computational overheads because of heavy communication between agents. Previous research has made efforts to train a sparse multi-agent graph or fine-tune a planner to orchestrate the workflow better. However, such extra training processes introduce computational costs and limit MAS to specific domains, therefore compromising their generalizability. In this paper, we propose CONCAT, a training-free multi-agent collaboration framework based on CONsensus and Confidence-driven Ad hoc Teaming to efficiently organize agent interactions. Specifically, agents are clustered based on their initial answers, and leaders of each cluster are selected based on the agents' confidence. Then, a heuristic function based on the Theory of Mind is designed to predict the collaboration benefits between every two leaders according to their answers and confidence. Finally, an ad hoc multi-agent network is organized after evicting a percentage of communications based on the predicted benefits. Experiments across three LLMs and three benchmarks show that CONCAT achieves up to 2.02x higher efficiency (accuracy/latency ratio) than LLM-Debate and outperforms training-aware methods such as AgentDropout, while reducing average latency by 50.1% on Qwen2.5-14B-Instruct, without any task-specific training.
When KV Cache Reuse Fails in Multi-Agent Systems: Cross-Candidate Interaction is Crucial for LLM Judges
Jan 13, 2026Multi-agent LLM systems routinely generate multiple candidate responses that are aggregated by an LLM judge. To reduce the dominant prefill cost in such pipelines, recent work advocates KV cache reuse across partially shared contexts and reports substantial speedups for generation agents. In this work, we show that these efficiency gains do not transfer uniformly to judge-centric inference. Across GSM8K, MMLU, and HumanEval, we find that reuse strategies that are effective for execution agents can severely perturb judge behavior: end-task accuracy may appear stable, yet the judge's selection becomes highly inconsistent with dense prefill. We quantify this risk using Judge Consistency Rate (JCR) and provide diagnostics showing that reuse systematically weakens cross-candidate attention, especially for later candidate blocks. Our ablation further demonstrates that explicit cross-candidate interaction is crucial for preserving dense-prefill decisions. Overall, our results identify a previously overlooked failure mode of KV cache reuse and highlight judge-centric inference as a distinct regime that demands dedicated, risk-aware system design.
GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection
Dec 10, 2025



Building AI systems for GUI automation task has attracted remarkable research efforts, where MLLMs are leveraged for processing user requirements and give operations. However, GUI automation includes a wide range of tasks, from document processing to online shopping, from CAD to video editing. Diversity between particular tasks requires MLLMs for GUI automation to have heterogeneous capabilities and master multidimensional expertise, raising problems on constructing such a model. To address such challenge, we propose GAIR: GUI Automation via Information-Joint Reasoning and Group Reflection, a novel MLLM-based GUI automation agent framework designed for integrating knowledge and combining capabilities from heterogeneous models to build GUI automation agent systems with higher performance. Since different GUI-specific MLLMs are trained on different dataset and thus have different strengths, GAIR introduced a general-purpose MLLM for jointly processing the information from multiple GUI-specific models, further enhancing performance of the agent framework. The general-purpose MLLM also serves as decision maker, trying to execute a reasonable operation based on previously gathered information. When the general-purpose model thinks that there isn't sufficient information for a reasonable decision, GAIR would transit into group reflection status, where the general-purpose model would provide GUI-specific models with different instructions and hints based on their strengths and weaknesses, driving them to gather information with more significance and accuracy that can support deeper reasoning and decision. We evaluated the effectiveness and reliability of GAIR through extensive experiments on GUI benchmarks.
Pangu Pro MoE: Mixture of Grouped Experts for Efficient Sparsity
May 28, 2025The surgence of Mixture of Experts (MoE) in Large Language Models promises a small price of execution cost for a much larger model parameter count and learning capacity, because only a small fraction of parameters are activated for each input token. However, it is commonly observed that some experts are activated far more often than others, leading to system inefficiency when running the experts on different devices in parallel. Therefore, we introduce Mixture of Grouped Experts (MoGE), which groups the experts during selection and balances the expert workload better than MoE in nature. It constrains tokens to activate an equal number of experts within each predefined expert group. When a model execution is distributed on multiple devices, this architectural design ensures a balanced computational load across devices, significantly enhancing throughput, particularly for the inference phase. Further, we build Pangu Pro MoE on Ascend NPUs, a sparse model based on MoGE with 72 billion total parameters, 16 billion of which are activated for each token. The configuration of Pangu Pro MoE is optimized for Ascend 300I Duo and 800I A2 through extensive system simulation studies. Our experiments indicate that MoGE indeed leads to better expert load balancing and more efficient execution for both model training and inference on Ascend NPUs. The inference performance of Pangu Pro MoE achieves 1148 tokens/s per card and can be further improved to 1528 tokens/s per card by speculative acceleration, outperforming comparable 32B and 72B Dense models. Furthermore, we achieve an excellent cost-to-performance ratio for model inference on Ascend 300I Duo. Our studies show that Ascend NPUs are capable of training Pangu Pro MoE with massive parallelization to make it a leading model within the sub-100B total parameter class, outperforming prominent open-source models like GLM-Z1-32B and Qwen3-32B.
Adaptive Federated Dropout: Improving Communication Efficiency and Generalization for Federated Learning
Nov 08, 2020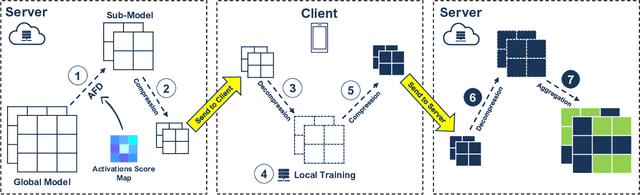
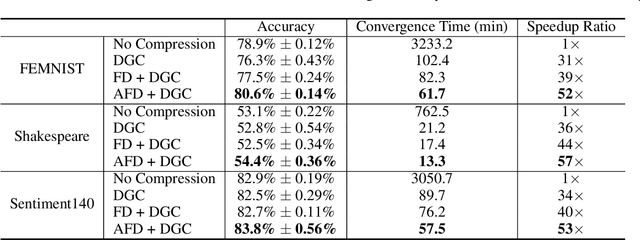
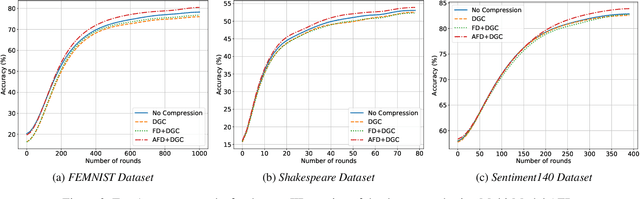
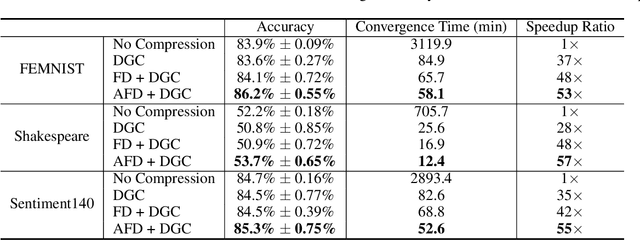
With more regulations tackling users' privacy-sensitive data protection in recent years, access to such data has become increasingly restricted and controversial. To exploit the wealth of data generated and located at distributed entities such as mobile phones, a revolutionary decentralized machine learning setting, known as Federated Learning, enables multiple clients located at different geographical locations to collaboratively learn a machine learning model while keeping all their data on-device. However, the scale and decentralization of federated learning present new challenges. Communication between the clients and the server is considered a main bottleneck in the convergence time of federated learning. In this paper, we propose and study Adaptive Federated Dropout (AFD), a novel technique to reduce the communication costs associated with federated learning. It optimizes both server-client communications and computation costs by allowing clients to train locally on a selected subset of the global model. We empirically show that this strategy, combined with existing compression methods, collectively provides up to 57x reduction in convergence time. It also outperforms the state-of-the-art solutions for communication efficiency. Furthermore, it improves model generalization by up to 1.7%.
Compiler-Level Matrix Multiplication Optimization for Deep Learning
Sep 23, 2019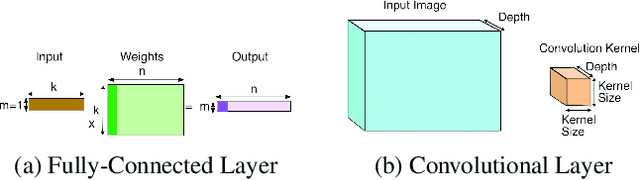
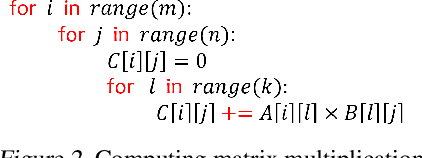
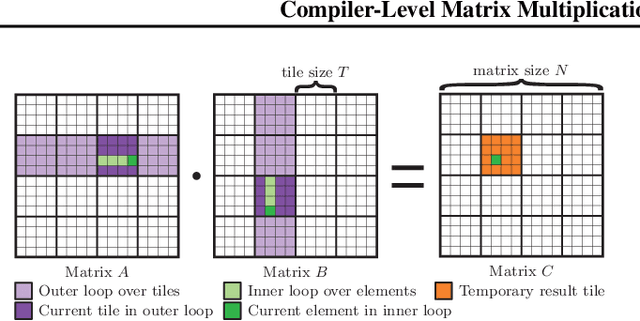

An important linear algebra routine, GEneral Matrix Multiplication (GEMM), is a fundamental operator in deep learning. Compilers need to translate these routines into low-level code optimized for specific hardware. Compiler-level optimization of GEMM has significant performance impact on training and executing deep learning models. However, most deep learning frameworks rely on hardware-specific operator libraries in which GEMM optimization has been mostly achieved by manual tuning, which restricts the performance on different target hardware. In this paper, we propose two novel algorithms for GEMM optimization based on the TVM framework, a lightweight Greedy Best First Search (G-BFS) method based on heuristic search, and a Neighborhood Actor Advantage Critic (N-A2C) method based on reinforcement learning. Experimental results show significant performance improvement of the proposed methods, in both the optimality of the solution and the cost of search in terms of time and fraction of the search space explored. Specifically, the proposed methods achieve 24% and 40% savings in GEMM computation time over state-of-the-art XGBoost and RNN methods, respectively, while exploring only 0.1% of the search space. The proposed approaches have potential to be applied to other operator-level optimizations.