 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Representational Learning of Foundation Models for Recommendation
Jun 16, 2025Developing a single foundation model with the capability to excel across diverse tasks has been a long-standing objective in the field of artificial intelligence. As the wave of general-purpose foundation models sweeps across various domains, their influence has significantly extended to the field of recommendation systems. While recent efforts have explored recommendation foundation models for various generative tasks, they often overlook crucial embedding tasks and struggle with the complexities of multi-task learning, including knowledge sharing & conflict resolution, and convergence speed inconsistencies. To address these limitations, we introduce RecFound, a generative representational learning framework for recommendation foundation models. We construct the first comprehensive dataset for recommendation foundation models covering both generative and embedding tasks across diverse scenarios. Based on this dataset, we propose a novel multi-task training scheme featuring a Task-wise Mixture of Low-rank Experts (TMoLE) to handle knowledge sharing & conflict, a Step-wise Convergence-oriented Sample Scheduler (S2Sched) to address inconsistent convergence, and a Model Merge module to balance the performance across tasks. Experiments demonstrate that RecFound achieves state-of-the-art performance across various recommendation tasks, outperforming existing baselines.
LLM4Tag: Automatic Tagging System for Information Retrieval via Large Language Models
Feb 19, 2025



Tagging systems play an essential role in various information retrieval applications such as search engines and recommender systems. Recently, Large Language Models (LLMs) have been applied in tagging systems due to their extensive world knowledge, semantic understanding, and reasoning capabilities. Despite achieving remarkable performance, existing methods still have limitations, including difficulties in retrieving relevant candidate tags comprehensively, challenges in adapting to emerging domain-specific knowledge, and the lack of reliable tag confidence quantification. To address these three limitations above, we propose an automatic tagging system LLM4Tag. First, a graph-based tag recall module is designed to effectively and comprehensively construct a small-scale highly relevant candidate tag set. Subsequently, a knowledge-enhanced tag generation module is employed to generate accurate tags with long-term and short-term knowledge injection. Finally, a tag confidence calibration module is introduced to generate reliable tag confidence scores. Extensive experiments over three large-scale industrial datasets show that LLM4Tag significantly outperforms the state-of-the-art baselines and LLM4Tag has been deployed online for content tagging to serve hundreds of millions of users.
An Automatic Graph Construction Framework based on Large Language Models for Recommendation
Dec 24, 2024Graph neural networks (GNNs) have emerged as state-of-the-art methods to learn from graph-structured data for recommendation. However, most existing GNN-based recommendation methods focus on the optimization of model structures and learning strategies based on pre-defined graphs, neglecting the importance of the graph construction stage. Earlier works for graph construction usually rely on speciffic rules or crowdsourcing, which are either too simplistic or too labor-intensive. Recent works start to utilize large language models (LLMs) to automate the graph construction, in view of their abundant open-world knowledge and remarkable reasoning capabilities. Nevertheless, they generally suffer from two limitations: (1) invisibility of global view (e.g., overlooking contextual information) and (2) construction inefficiency. To this end, we introduce AutoGraph, an automatic graph construction framework based on LLMs for recommendation. Specifically, we first use LLMs to infer the user preference and item knowledge, which is encoded as semantic vectors. Next, we employ vector quantization to extract the latent factors from the semantic vectors. The latent factors are then incorporated as extra nodes to link the user/item nodes, resulting in a graph with in-depth global-view semantics. We further design metapath-based message aggregation to effectively aggregate the semantic and collaborative information. The framework is model-agnostic and compatible with different backbone models. Extensive experiments on three real-world datasets demonstrate the efficacy and efffciency of AutoGraph compared to existing baseline methods. We have deployed AutoGraph in Huawei advertising platform, and gain a 2.69% improvement on RPM and a 7.31% improvement on eCPM in the online A/B test. Currently AutoGraph has been used as the main trafffc model, serving hundreds of millions of people.
LIBER: Lifelong User Behavior Modeling Based on Large Language Models
Nov 22, 2024



CTR prediction plays a vital role in recommender systems. Recently, large language models (LLMs) have been applied in recommender systems due to their emergence abilities. While leveraging semantic information from LLMs has shown some improvements in the performance of recommender systems, two notable limitations persist in these studies. First, LLM-enhanced recommender systems encounter challenges in extracting valuable information from lifelong user behavior sequences within textual contexts for recommendation tasks. Second, the inherent variability in human behaviors leads to a constant stream of new behaviors and irregularly fluctuating user interests. This characteristic imposes two significant challenges on existing models. On the one hand, it presents difficulties for LLMs in effectively capturing the dynamic shifts in user interests within these sequences, and on the other hand, there exists the issue of substantial computational overhead if the LLMs necessitate recurrent calls upon each update to the user sequences. In this work, we propose Lifelong User Behavior Modeling (LIBER) based on large language models, which includes three modules: (1) User Behavior Streaming Partition (UBSP), (2) User Interest Learning (UIL), and (3) User Interest Fusion (UIF). Initially, UBSP is employed to condense lengthy user behavior sequences into shorter partitions in an incremental paradigm, facilitating more efficient processing. Subsequently, UIL leverages LLMs in a cascading way to infer insights from these partitions. Finally, UIF integrates the textual outputs generated by the aforementioned processes to construct a comprehensive representation, which can be incorporated by any recommendation model to enhance performance. LIBER has been deployed on Huawei's music recommendation service and achieved substantial improvements in users' play count and play time by 3.01% and 7.69%.
AIE: Auction Information Enhanced Framework for CTR Prediction in Online Advertising
Aug 15, 2024



Click-Through Rate (CTR) prediction is a fundamental technique for online advertising recommendation and the complex online competitive auction process also brings many difficulties to CTR optimization. Recent studies have shown that introducing posterior auction information contributes to the performance of CTR prediction. However, existing work doesn't fully capitalize on the benefits of auction information and overlooks the data bias brought by the auction, leading to biased and suboptimal results. To address these limitations, we propose Auction Information Enhanced Framework (AIE) for CTR prediction in online advertising, which delves into the problem of insufficient utilization of auction signals and first reveals the auction bias. Specifically, AIE introduces two pluggable modules, namely Adaptive Market-price Auxiliary Module (AM2) and Bid Calibration Module (BCM), which work collaboratively to excavate the posterior auction signals better and enhance the performance of CTR prediction. Furthermore, the two proposed modules are lightweight, model-agnostic, and friendly to inference latency. Extensive experiments are conducted on a public dataset and an industrial dataset to demonstrate the effectiveness and compatibility of AIE. Besides, a one-month online A/B test in a large-scale advertising platform shows that AIE improves the base model by 5.76% and 2.44% in terms of eCPM and CTR, respectively.
Vector Quantization for Recommender Systems: A Review and Outlook
May 06, 2024Vector quantization, renowned for its unparalleled feature compression capabilities, has been a prominent topic in signal processing and machine learning research for several decades and remains widely utilized today. With the emergence of large models and generative AI, vector quantization has gained popularity in recommender systems, establishing itself as a preferred solution. This paper starts with a comprehensive review of vector quantization techniques. It then explores systematic taxonomies of vector quantization methods for recommender systems (VQ4Rec), examining their applications from multiple perspectives. Further, it provides a thorough introduction to research efforts in diverse recommendation scenarios, including efficiency-oriented approaches and quality-oriented approaches. Finally, the survey analyzes the remaining challenges and anticipates future trends in VQ4Rec, including the challenges associated with the training of vector quantization, the opportunities presented by large language models, and emerging trends in multimodal recommender systems. We hope this survey can pave the way for future researchers in the recommendation community and accelerate their exploration in this promising field.
ALT: Towards Fine-grained Alignment between Language and CTR Models for Click-Through Rate Prediction
Oct 30, 2023



Click-through rate (CTR) prediction plays as a core function module in various personalized online services. According to the data modality and input format, the models for CTR prediction can be mainly classified into two categories. The first one is the traditional CTR models that take as inputs the one-hot encoded ID features of tabular modality, which aims to capture the collaborative signals via feature interaction modeling. The second category takes as inputs the sentences of textual modality obtained by hard prompt templates, where pretrained language models (PLMs) are adopted to extract the semantic knowledge. These two lines of research generally focus on different characteristics of the same input data (i.e., textual and tabular modalities), forming a distinct complementary relationship with each other. Therefore, in this paper, we propose to conduct fine-grained feature-level Alignment between Language and CTR models (ALT) for CTR prediction. Apart from the common CLIP-like instance-level contrastive learning, we further design a novel joint reconstruction pretraining task for both masked language and tabular modeling. Specifically, the masked data of one modality (i.e., tokens or features) has to be recovered with the help of the other modality, which establishes the feature-level interaction and alignment via sufficient mutual information extraction between dual modalities. Moreover, we propose three different finetuning strategies with the option to train the aligned language and CTR models separately or jointly for downstream CTR prediction tasks, thus accommodating the varying efficacy and efficiency requirements for industrial applications. Extensive experiments on three real-world datasets demonstrate that ALT outperforms SOTA baselines, and is highly compatible for various language and CTR models.
ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
Aug 22, 2023



With large language models (LLMs) achieving remarkable breakthroughs in natural language processing (NLP) domains, LLM-enhanced recommender systems have received much attention and have been actively explored currently. In this paper, we focus on adapting and empowering a pure large language model for zero-shot and few-shot recommendation tasks. First and foremost, we identify and formulate the lifelong sequential behavior incomprehension problem for LLMs in recommendation domains, i.e., LLMs fail to extract useful information from a textual context of long user behavior sequence, even if the length of context is far from reaching the context limitation of LLMs. To address such an issue and improve the recommendation performance of LLMs, we propose a novel framework, namely Retrieval-enhanced Large Language models (ReLLa) for recommendation tasks in both zero-shot and few-shot settings. For zero-shot recommendation, we perform semantic user behavior retrieval (SUBR) to improve the data quality of testing samples, which greatly reduces the difficulty for LLMs to extract the essential knowledge from user behavior sequences. As for few-shot recommendation, we further design retrieval-enhanced instruction tuning (ReiT) by adopting SUBR as a data augmentation technique for training samples. Specifically, we develop a mixed training dataset consisting of both the original data samples and their retrieval-enhanced counterparts. We conduct extensive experiments on a real-world public dataset (i.e., MovieLens-1M) to demonstrate the superiority of ReLLa compared with existing baseline models, as well as its capability for lifelong sequential behavior comprehension.
How Can Recommender Systems Benefit from Large Language Models: A Survey
Jun 28, 2023Recommender systems (RS) play important roles to match users' information needs for Internet applications. In natural language processing (NLP) domains, large language model (LLM) has shown astonishing emergent abilities (e.g., instruction following, reasoning), thus giving rise to the promising research direction of adapting LLM to RS for performance enhancements and user experience improvements. In this paper, we conduct a comprehensive survey on this research direction from an application-oriented view. We first summarize existing research works from two orthogonal perspectives: where and how to adapt LLM to RS. For the "WHERE" question, we discuss the roles that LLM could play in different stages of the recommendation pipeline, i.e., feature engineering, feature encoder, scoring/ranking function, and pipeline controller. For the "HOW" question, we investigate the training and inference strategies, resulting in two fine-grained taxonomy criteria, i.e., whether to tune LLMs or not, and whether to involve conventional recommendation model (CRM) for inference. Detailed analysis and general development trajectories are provided for both questions, respectively. Then, we highlight key challenges in adapting LLM to RS from three aspects, i.e., efficiency, effectiveness, and ethics. Finally, we summarize the survey and discuss the future prospects. We also actively maintain a GitHub repository for papers and other related resources in this rising direction: https://github.com/CHIANGEL/Awesome-LLM-for-RecSys.
IntTower: the Next Generation of Two-Tower Model for Pre-Ranking System
Oct 18, 2022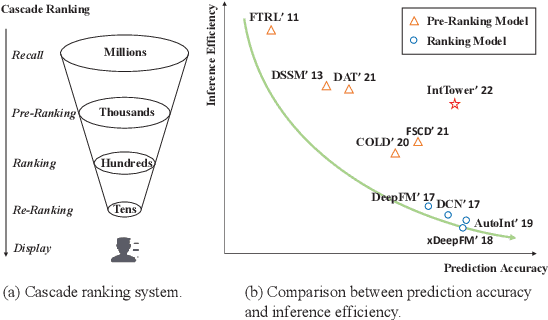
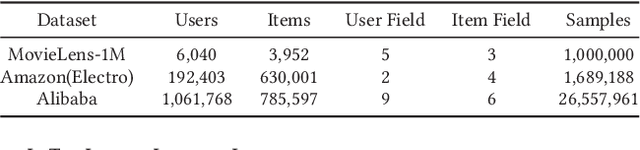
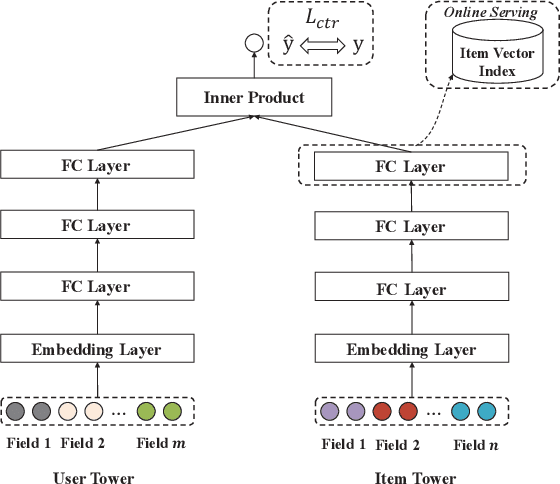
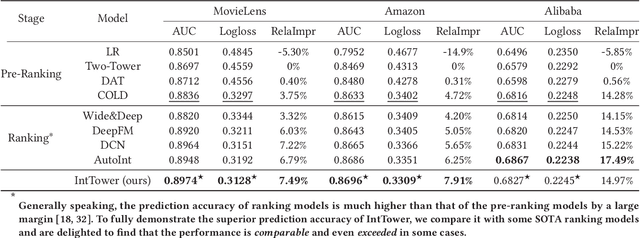
Scoring a large number of candidates precisely in several milliseconds is vital for industrial pre-ranking systems. Existing pre-ranking systems primarily adopt the \textbf{two-tower} model since the ``user-item decoupling architecture'' paradigm is able to balance the \textit{efficiency} and \textit{effectiveness}. However, the cost of high efficiency is the neglect of the potential information interaction between user and item towers, hindering the prediction accuracy critically. In this paper, we show it is possible to design a two-tower model that emphasizes both information interactions and inference efficiency. The proposed model, IntTower (short for \textit{Interaction enhanced Two-Tower}), consists of Light-SE, FE-Block and CIR modules. Specifically, lightweight Light-SE module is used to identify the importance of different features and obtain refined feature representations in each tower. FE-Block module performs fine-grained and early feature interactions to capture the interactive signals between user and item towers explicitly and CIR module leverages a contrastive interaction regularization to further enhance the interactions implicitly. Experimental results on three public datasets show that IntTower outperforms the SOTA pre-ranking models significantly and even achieves comparable performance in comparison with the ranking models. Moreover, we further verify the effectiveness of IntTower on a large-scale advertisement pre-ranking system. The code of IntTower is publicly available\footnote{https://github.com/archersama/IntTower}