 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKwai Summary Attention Technical Report
Apr 27, 2026Long-context ability, has become one of the most important iteration direction of next-generation Large Language Models, particularly in semantic understanding/reasoning, code agentic intelligence and recommendation system. However, the standard softmax attention exhibits quadratic time complexity with respect to sequence length. As the sequence length increases, this incurs substantial overhead in long-context settings, leading the training and inference costs of extremely long sequences deteriorate rapidly. Existing solutions mitigate this issue through two technique routings: i) Reducing the KV cache per layer, such as from the head-level compression GQA, and the embedding dimension-level compression MLA, but the KV cache remains linearly dependent on the sequence length at a 1:1 ratio. ii) Interleaving with KV Cache friendly architecture, such as local attention SWA, linear kernel GDN, but often involve trade-offs among KV Cache and long-context modeling effectiveness. Besides the two technique routings, we argue that there exists an intermediate path not well explored: {Maintaining a linear relationship between the KV cache and sequence length, but performing semantic-level compression through a specific ratio $k$}. This $O(n/k)$ path does not pursue a ``minimum KV cache'', but rather trades acceptable memory costs for complete, referential, and interpretable retention of long distant dependency. Motivated by this, we propose Kwai Summary Attention (KSA), a novel attention mechanism that reduces sequence modeling cost by compressing historical contexts into learnable summary tokens.
Kelix Technical Report
Feb 12, 2026Autoregressive large language models (LLMs) scale well by expressing diverse tasks as sequences of discrete natural-language tokens and training with next-token prediction, which unifies comprehension and generation under self-supervision. Extending this paradigm to multimodal data requires a shared, discrete representation across modalities. However, most vision-language models (VLMs) still rely on a hybrid interface: discrete text tokens paired with continuous Vision Transformer (ViT) features. Because supervision is largely text-driven, these models are often biased toward understanding and cannot fully leverage large-scale self-supervised learning on non-text data. Recent work has explored discrete visual tokenization to enable fully autoregressive multimodal modeling, showing promising progress toward unified understanding and generation. Yet existing discrete vision tokens frequently lose information due to limited code capacity, resulting in noticeably weaker understanding than continuous-feature VLMs. We present Kelix, a fully discrete autoregressive unified model that closes the understanding gap between discrete and continuous visual representations.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
Less is More: Non-uniform Road Segments are Efficient for Bus Arrival Prediction
Dec 08, 2025In bus arrival time prediction, the process of organizing road infrastructure network data into homogeneous entities is known as segmentation. Segmenting a road network is widely recognized as the first and most critical step in developing an arrival time prediction system, particularly for auto-regressive-based approaches. Traditional methods typically employ a uniform segmentation strategy, which fails to account for varying physical constraints along roads, such as road conditions, intersections, and points of interest, thereby limiting prediction efficiency. In this paper, we propose a Reinforcement Learning (RL)-based approach to efficiently and adaptively learn non-uniform road segments for arrival time prediction. Our method decouples the prediction process into two stages: 1) Non-uniform road segments are extracted based on their impact scores using the proposed RL framework; and 2) A linear prediction model is applied to the selected segments to make predictions. This method ensures optimal segment selection while maintaining computational efficiency, offering a significant improvement over traditional uniform approaches. Furthermore, our experimental results suggest that the linear approach can even achieve better performance than more complex methods. Extensive experiments demonstrate the superiority of the proposed method, which not only enhances efficiency but also improves learning performance on large-scale benchmarks. The dataset and the code are publicly accessible at: https://github.com/pangjunbiao/Less-is-More.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025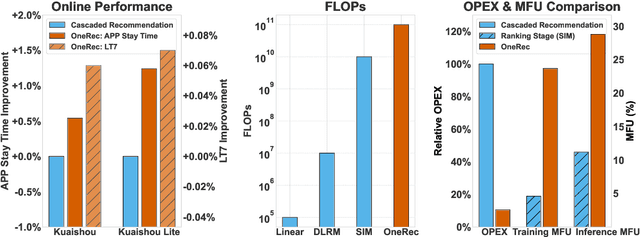

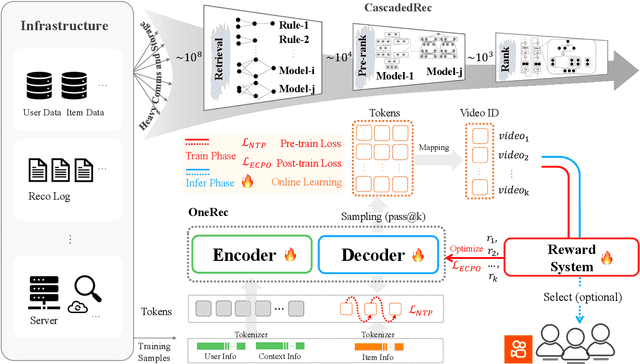
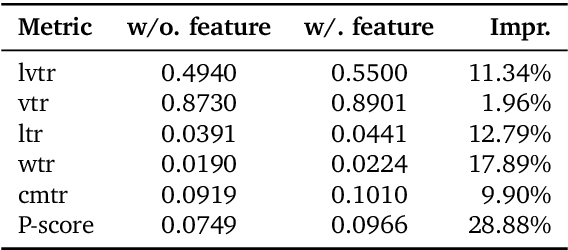
Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Other Vehicle Trajectories Are Also Needed: A Driving World Model Unifies Ego-Other Vehicle Trajectories in Video Latant Space
Mar 12, 2025Advanced end-to-end autonomous driving systems predict other vehicles' motions and plan ego vehicle's trajectory. The world model that can foresee the outcome of the trajectory has been used to evaluate the end-to-end autonomous driving system. However, existing world models predominantly emphasize the trajectory of the ego vehicle and leave other vehicles uncontrollable. This limitation hinders their ability to realistically simulate the interaction between the ego vehicle and the driving scenario. In addition, it remains a challenge to match multiple trajectories with each vehicle in the video to control the video generation. To address above issues, a driving \textbf{W}orld \textbf{M}odel named EOT-WM is proposed in this paper, unifying \textbf{E}go-\textbf{O}ther vehicle \textbf{T}rajectories in videos. Specifically, we first project ego and other vehicle trajectories in the BEV space into the image coordinate to match each trajectory with its corresponding vehicle in the video. Then, trajectory videos are encoded by the Spatial-Temporal Variational Auto Encoder to align with driving video latents spatially and temporally in the unified visual space. A trajectory-injected diffusion Transformer is further designed to denoise the noisy video latents for video generation with the guidance of ego-other vehicle trajectories. In addition, we propose a metric based on control latent similarity to evaluate the controllability of trajectories. Extensive experiments are conducted on the nuScenes dataset, and the proposed model outperforms the state-of-the-art method by 30\% in FID and 55\% in FVD. The model can also predict unseen driving scenes with self-produced trajectories.
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Feb 26, 2025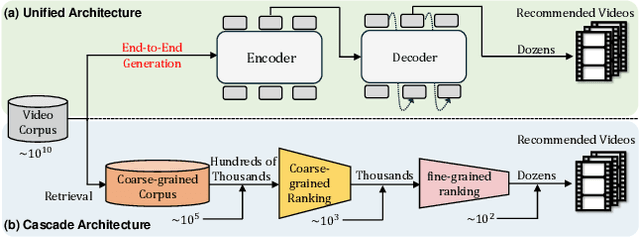
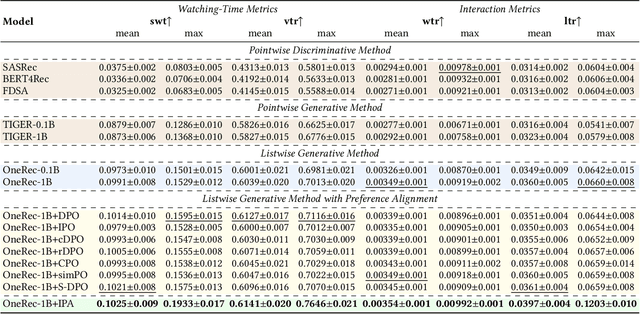
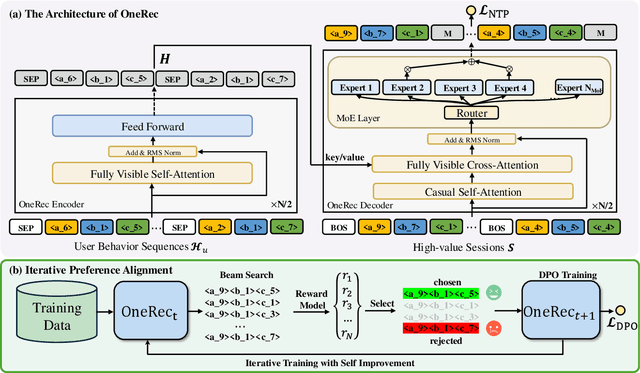

Recently, generative retrieval-based recommendation systems have emerged as a promising paradigm. However, most modern recommender systems adopt a retrieve-and-rank strategy, where the generative model functions only as a selector during the retrieval stage. In this paper, we propose OneRec, which replaces the cascaded learning framework with a unified generative model. To the best of our knowledge, this is the first end-to-end generative model that significantly surpasses current complex and well-designed recommender systems in real-world scenarios. Specifically, OneRec includes: 1) an encoder-decoder structure, which encodes the user's historical behavior sequences and gradually decodes the videos that the user may be interested in. We adopt sparse Mixture-of-Experts (MoE) to scale model capacity without proportionally increasing computational FLOPs. 2) a session-wise generation approach. In contrast to traditional next-item prediction, we propose a session-wise generation, which is more elegant and contextually coherent than point-by-point generation that relies on hand-crafted rules to properly combine the generated results. 3) an Iterative Preference Alignment module combined with Direct Preference Optimization (DPO) to enhance the quality of the generated results. Unlike DPO in NLP, a recommendation system typically has only one opportunity to display results for each user's browsing request, making it impossible to obtain positive and negative samples simultaneously. To address this limitation, We design a reward model to simulate user generation and customize the sampling strategy. Extensive experiments have demonstrated that a limited number of DPO samples can align user interest preferences and significantly improve the quality of generated results. We deployed OneRec in the main scene of Kuaishou, achieving a 1.6\% increase in watch-time, which is a substantial improvement.
Unsupervised Abnormal Stop Detection for Long Distance Coaches with Low-Frequency GPS
Nov 07, 2024



In our urban life, long distance coaches supply a convenient yet economic approach to the transportation of the public. One notable problem is to discover the abnormal stop of the coaches due to the important reason, i.e., illegal pick up on the way which possibly endangers the safety of passengers. It has become a pressing issue to detect the coach abnormal stop with low-quality GPS. In this paper, we propose an unsupervised method that helps transportation managers to efficiently discover the Abnormal Stop Detection (ASD) for long distance coaches. Concretely, our method converts the ASD problem into an unsupervised clustering framework in which both the normal stop and the abnormal one are decomposed. Firstly, we propose a stop duration model for the low frequency GPS based on the assumption that a coach changes speed approximately in a linear approach. Secondly, we strip the abnormal stops from the normal stop points by the low rank assumption. The proposed method is conceptually simple yet efficient, by leveraging low rank assumption to handle normal stop points, our approach enables domain experts to discover the ASD for coaches, from a case study motivated by traffic managers. Datset and code are publicly available at: https://github.com/pangjunbiao/IPPs.
ELASTIC: Efficient Linear Attention for Sequential Interest Compression
Aug 20, 2024



State-of-the-art sequential recommendation models heavily rely on transformer's attention mechanism. However, the quadratic computational and memory complexities of self attention have limited its scalability for modeling users' long range behaviour sequences. To address this problem, we propose ELASTIC, an Efficient Linear Attention for SequenTial Interest Compression, requiring only linear time complexity and decoupling model capacity from computational cost. Specifically, ELASTIC introduces a fixed length interest experts with linear dispatcher attention mechanism which compresses the long-term behaviour sequences to a significantly more compact representation which reduces up to 90% GPU memory usage with x2.7 inference speed up. The proposed linear dispatcher attention mechanism significantly reduces the quadratic complexity and makes the model feasible for adequately modeling extremely long sequences. Moreover, in order to retain the capacity for modeling various user interests, ELASTIC initializes a vast learnable interest memory bank and sparsely retrieves compressed user's interests from the memory with a negligible computational overhead. The proposed interest memory retrieval technique significantly expands the cardinality of available interest space while keeping the same computational cost, thereby striking a trade-off between recommendation accuracy and efficiency. To validate the effectiveness of our proposed ELASTIC, we conduct extensive experiments on various public datasets and compare it with several strong sequential recommenders. Experimental results demonstrate that ELASTIC consistently outperforms baselines by a significant margin and also highlight the computational efficiency of ELASTIC when modeling long sequences. We will make our implementation code publicly available.