 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructurally Aligned Subtask-Level Memory for Software Engineering Agents
Feb 25, 2026Large Language Models (LLMs) have demonstrated significant potential as autonomous software engineering (SWE) agents. Recent work has further explored augmenting these agents with memory mechanisms to support long-horizon reasoning. However, these approaches typically operate at a coarse instance granularity, treating the entire problem-solving episode as the atomic unit of storage and retrieval. We empirically demonstrate that instance-level memory suffers from a fundamental granularity mismatch, resulting in misguided retrieval when tasks with similar surface descriptions require distinct reasoning logic at specific stages. To address this, we propose Structurally Aligned Subtask-Level Memory, a method that aligns memory storage, retrieval, and updating with the agent's functional decomposition. Extensive experiments on SWE-bench Verified demonstrate that our method consistently outperforms both vanilla agents and strong instance-level memory baselines across diverse backbones, improving mean Pass@1 over the vanilla agent by +4.7 pp on average (e.g., +6.8 pp on Gemini 2.5 Pro). Performance gains grow with more interaction steps, showing that leveraging past experience benefits long-horizon reasoning in complex software engineering tasks.
GISA: A Benchmark for General Information-Seeking Assistant
Feb 09, 2026The advancement of large language models (LLMs) has significantly accelerated the development of search agents capable of autonomously gathering information through multi-turn web interactions. Various benchmarks have been proposed to evaluate such agents. However, existing benchmarks often construct queries backward from answers, producing unnatural tasks misaligned with real-world needs. Moreover, these benchmarks tend to focus on either locating specific information or aggregating information from multiple sources, while relying on static answer sets prone to data contamination. To bridge these gaps, we introduce GISA, a benchmark for General Information-Seeking Assistants comprising 373 human-crafted queries that reflect authentic information-seeking scenarios. GISA features four structured answer formats (item, set, list, and table), enabling deterministic evaluation. It integrates both deep reasoning and broad information aggregation within unified tasks, and includes a live subset with periodically updated answers to resist memorization. Notably, GISA provides complete human search trajectories for every query, offering gold-standard references for process-level supervision and imitation learning. Experiments on mainstream LLMs and commercial search products reveal that even the best-performing model achieves only 19.30\% exact match score, with performance notably degrading on tasks requiring complex planning and comprehensive information gathering. These findings highlight substantial room for future improvement.
CVE-Factory: Scaling Expert-Level Agentic Tasks for Code Security Vulnerability
Feb 03, 2026Evaluating and improving the security capabilities of code agents requires high-quality, executable vulnerability tasks. However, existing works rely on costly, unscalable manual reproduction and suffer from outdated data distributions. To address these, we present CVE-Factory, the first multi-agent framework to achieve expert-level quality in automatically transforming sparse CVE metadata into fully executable agentic tasks. Cross-validation against human expert reproductions shows that CVE-Factory achieves 95\% solution correctness and 96\% environment fidelity, confirming its expert-level quality. It is also evaluated on the latest realistic vulnerabilities and achieves a 66.2\% verified success. This automation enables two downstream contributions. First, we construct LiveCVEBench, a continuously updated benchmark of 190 tasks spanning 14 languages and 153 repositories that captures emerging threats including AI-tooling vulnerabilities. Second, we synthesize over 1,000 executable training environments, the first large-scale scaling of agentic tasks in code security. Fine-tuned Qwen3-32B improves from 5.3\% to 35.8\% on LiveCVEBench, surpassing Claude 4.5 Sonnet, with gains generalizing to Terminal Bench (12.5\% to 31.3\%). We open-source CVE-Factory, LiveCVEBench, Abacus-cve (fine-tuned model), training dataset, and leaderboard. All resources are available at https://github.com/livecvebench/CVE-Factory .
LLM-Aligned Geographic Item Tokenization for Local-Life Recommendation
Nov 18, 2025Recent advances in Large Language Models (LLMs) have enhanced text-based recommendation by enriching traditional ID-based methods with semantic generalization capabilities. Text-based methods typically encode item textual information via prompt design and generate discrete semantic IDs through item tokenization. However, in domain-specific tasks such as local-life services, simply injecting location information into prompts fails to capture fine-grained spatial characteristics and real-world distance awareness among items. To address this, we propose LGSID, an LLM-Aligned Geographic Item Tokenization Framework for Local-life Recommendation. This framework consists of two key components: (1) RL-based Geographic LLM Alignment, and (2) Hierarchical Geographic Item Tokenization. In the RL-based alignment module, we initially train a list-wise reward model to capture real-world spatial relationships among items. We then introduce a novel G-DPO algorithm that uses pre-trained reward model to inject generalized spatial knowledge and collaborative signals into LLMs while preserving their semantic understanding. Furthermore, we propose a hierarchical geographic item tokenization strategy, where primary tokens are derived from discrete spatial and content attributes, and residual tokens are refined using the aligned LLM's geographic representation vectors. Extensive experiments on real-world Kuaishou industry datasets show that LGSID consistently outperforms state-of-the-art discriminative and generative recommendation models. Ablation studies, visualizations, and case studies further validate its effectiveness.
A Plug-and-Play Spatially-Constrained Representation Enhancement Framework for Local-Life Recommendation
Nov 17, 2025Local-life recommendation have witnessed rapid growth, providing users with convenient access to daily essentials. However, this domain faces two key challenges: (1) spatial constraints, driven by the requirements of the local-life scenario, where items are usually shown only to users within a limited geographic area, indirectly reducing their exposure probability; and (2) long-tail sparsity, where few popular items dominate user interactions, while many high-quality long-tail items are largely overlooked due to imbalanced interaction opportunities. Existing methods typically adopt a user-centric perspective, such as modeling spatial user preferences or enhancing long-tail representations with collaborative filtering signals. However, we argue that an item-centric perspective is more suitable for this domain, focusing on enhancing long-tail items representation that align with the spatially-constrained characteristics of local lifestyle services. To tackle this issue, we propose ReST, a Plug-And-Play Spatially-Constrained Representation Enhancement Framework for Long-Tail Local-Life Recommendation. Specifically, we first introduce a Meta ID Warm-up Network, which initializes fundamental ID representations by injecting their basic attribute-level semantic information. Subsequently, we propose a novel Spatially-Constrained ID Representation Enhancement Network (SIDENet) based on contrastive learning, which incorporates two efficient strategies: a spatially-constrained hard sampling strategy and a dynamic representation alignment strategy. This design adaptively identifies weak ID representations based on their attribute-level information during training. It additionally enhances them by capturing latent item relationships within the spatially-constrained characteristics of local lifestyle services, while preserving compatibility with popular items.
OneLoc: Geo-Aware Generative Recommender Systems for Local Life Service
Aug 20, 2025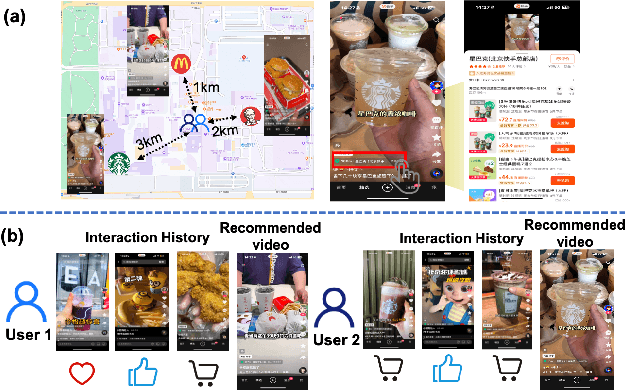
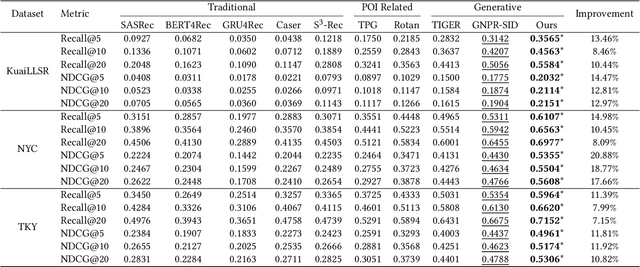
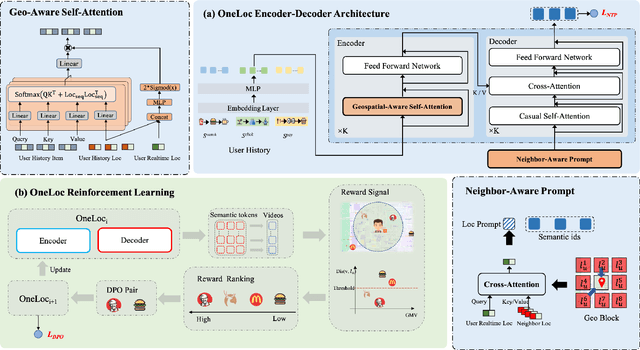

Local life service is a vital scenario in Kuaishou App, where video recommendation is intrinsically linked with store's location information. Thus, recommendation in our scenario is challenging because we should take into account user's interest and real-time location at the same time. In the face of such complex scenarios, end-to-end generative recommendation has emerged as a new paradigm, such as OneRec in the short video scenario, OneSug in the search scenario, and EGA in the advertising scenario. However, in local life service, an end-to-end generative recommendation model has not yet been developed as there are some key challenges to be solved. The first challenge is how to make full use of geographic information. The second challenge is how to balance multiple objectives, including user interests, the distance between user and stores, and some other business objectives. To address the challenges, we propose OneLoc. Specifically, we leverage geographic information from different perspectives: (1) geo-aware semantic ID incorporates both video and geographic information for tokenization, (2) geo-aware self-attention in the encoder leverages both video location similarity and user's real-time location, and (3) neighbor-aware prompt captures rich context information surrounding users for generation. To balance multiple objectives, we use reinforcement learning and propose two reward functions, i.e., geographic reward and GMV reward. With the above design, OneLoc achieves outstanding offline and online performance. In fact, OneLoc has been deployed in local life service of Kuaishou App. It serves 400 million active users daily, achieving 21.016% and 17.891% improvements in terms of gross merchandise value (GMV) and orders numbers.
FIM: Frequency-Aware Multi-View Interest Modeling for Local-Life Service Recommendation
Apr 30, 2025People's daily lives involve numerous periodic behaviors, such as eating and traveling. Local-life platforms cater to these recurring needs by providing essential services tied to daily routines. Therefore, users' periodic intentions are reflected in their interactions with the platforms. There are two main challenges in modeling users' periodic behaviors in the local-life service recommendation systems: 1) the diverse demands of users exhibit varying periodicities, which are difficult to distinguish as they are mixed in the behavior sequences; 2) the periodic behaviors of users are subject to dynamic changes due to factors such as holidays and promotional events. Existing methods struggle to distinguish the periodicities of diverse demands and overlook the importance of dynamically capturing changes in users' periodic behaviors. To this end, we employ a Frequency-Aware Multi-View Interest Modeling framework (FIM). Specifically, we propose a multi-view search strategy that decomposes users' demands from different perspectives to separate their various periodic intentions. This allows the model to comprehensively extract their periodic features than category-searched-only methods. Moreover, we propose a frequency-domain perception and evolution module. This module uses the Fourier Transform to convert users' temporal behaviors into the frequency domain, enabling the model to dynamically perceive their periodic features. Extensive offline experiments demonstrate that FIM achieves significant improvements on public and industrial datasets, showing its capability to effectively model users' periodic intentions. Furthermore, the model has been deployed on the Kuaishou local-life service platform. Through online A/B experiments, the transaction volume has been significantly improved.