 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Generative Recommendation
Feb 12, 2026Generative Recommendation has emerged as a transformative paradigm, reformulating recommendation as an end-to-end autoregressive sequence generation task. Despite its promise, existing preference optimization methods typically rely on binary outcome correctness, suffering from a systemic limitation we term uncertainty blindness. This issue manifests in the neglect of the model's intrinsic generation confidence, the variation in sample learning difficulty, and the lack of explicit confidence expression, directly leading to unstable training dynamics and unquantifiable decision risks. In this paper, we propose Uncertainty-aware Generative Recommendation (UGR), a unified framework that leverages uncertainty as a critical signal for adaptive optimization. UGR synergizes three mechanisms: (1) an uncertainty-weighted reward to penalize confident errors; (2) difficulty-aware optimization dynamics to prevent premature convergence; and (3) explicit confidence alignment to empower the model with confidence expression capabilities. Extensive experiments demonstrate that UGR not only yields superior recommendation performance but also fundamentally stabilizes training, preventing the performance degradation often observed in standard methods. Furthermore, the learned confidence enables reliable downstream risk-aware applications.
Don't Start Over: A Cost-Effective Framework for Migrating Personalized Prompts Between LLMs
Jan 17, 2026Personalization in Large Language Models (LLMs) often relies on user-specific soft prompts. However, these prompts become obsolete when the foundation model is upgraded, necessitating costly, full-scale retraining. To overcome this limitation, we propose the Prompt-level User Migration Adapter (PUMA), a lightweight framework to efficiently migrate personalized prompts across incompatible models. PUMA utilizes a parameter-efficient adapter to bridge the semantic gap, combined with a group-based user selection strategy to significantly reduce training costs. Experiments on three large-scale datasets show our method matches or even surpasses the performance of retraining from scratch, reducing computational cost by up to 98%. The framework demonstrates strong generalization across diverse model architectures and robustness in advanced scenarios like chained and aggregated migrations, offering a practical path for the sustainable evolution of personalized AI by decoupling user assets from the underlying models.
MindRec: A Diffusion-driven Coarse-to-Fine Paradigm for Generative Recommendation
Nov 18, 2025



Recent advancements in large language model-based recommendation systems often represent items as text or semantic IDs and generate recommendations in an auto-regressive manner. However, due to the left-to-right greedy decoding strategy and the unidirectional logical flow, such methods often fail to produce globally optimal recommendations. In contrast, human reasoning does not follow a rigid left-to-right sequence. Instead, it often begins with keywords or intuitive insights, which are then refined and expanded. Inspired by this fact, we propose MindRec, a diffusion-driven coarse-to-fine generative paradigm that emulates human thought processes. Built upon a diffusion language model, MindRec departs from auto-regressive generation by leveraging a masked diffusion process to reconstruct items in a flexible, non-sequential manner. Particularly, our method first generates key tokens that reflect user preferences, and then expands them into the complete item, enabling adaptive and human-like generation. To further emulate the structured nature of human decision-making, we organize items into a hierarchical category tree. This structure guides the model to first produce the coarse-grained category and then progressively refine its selection through finer-grained subcategories before generating the specific item. To mitigate the local optimum problem inherent in greedy decoding, we design a novel beam search algorithm, Diffusion Beam Search, tailored for our mind-inspired generation paradigm. Experimental results demonstrate that MindRec yields a 9.5\% average improvement in top-1 accuracy over state-of-the-art methods, highlighting its potential to enhance recommendation performance. The implementation is available via https://github.com/Mr-Peach0301/MindRec.
MGFRec: Towards Reinforced Reasoning Recommendation with Multiple Groundings and Feedback
Oct 27, 2025



The powerful reasoning and generative capabilities of large language models (LLMs) have inspired researchers to apply them to reasoning-based recommendation tasks, which require in-depth reasoning about user interests and the generation of recommended items. However, previous reasoning-based recommendation methods have typically performed inference within the language space alone, without incorporating the actual item space. This has led to over-interpreting user interests and deviating from real items. Towards this research gap, we propose performing multiple rounds of grounding during inference to help the LLM better understand the actual item space, which could ensure that its reasoning remains aligned with real items. Furthermore, we introduce a user agent that provides feedback during each grounding step, enabling the LLM to better recognize and adapt to user interests. Comprehensive experiments conducted on three Amazon review datasets demonstrate the effectiveness of incorporating multiple groundings and feedback. These findings underscore the critical importance of reasoning within the actual item space, rather than being confined to the language space, for recommendation tasks.
Optimizing Knowledge Integration in Retrieval-Augmented Generation with Self-Selection
Feb 10, 2025



Retrieval-Augmented Generation (RAG), which integrates external knowledge into Large Language Models (LLMs), has proven effective in enabling LLMs to produce more accurate and reliable responses. However, it remains a significant challenge how to effectively integrate external retrieved knowledge with internal parametric knowledge in LLMs. In this work, we propose a novel Self-Selection RAG framework, where the LLM is made to select from pairwise responses generated with internal parametric knowledge solely and with external retrieved knowledge together to achieve enhanced accuracy. To this end, we devise a Self-Selection-RGP method to enhance the capabilities of the LLM in both generating and selecting the correct answer, by training the LLM with Direct Preference Optimization (DPO) over a curated Retrieval Generation Preference (RGP) dataset. Experimental results with two open-source LLMs (i.e., Llama2-13B-Chat and Mistral-7B) well demonstrate the superiority of our approach over other baseline methods on Natural Questions (NQ) and TrivialQA datasets.
Beyond Near-Field: Far-Field Location Division Multiple Access in Downlink MIMO Systems
Jun 18, 2024



Exploring channel dimensions has been the driving force behind breakthroughs in successive generations of mobile communication systems. In 5G, space division multiple access (SDMA) leveraging massive MIMO has been crucial in enhancing system capacity through spatial differentiation of users. However, SDMA can only finely distinguish users at adjacent angles in ultra-dense networks by extremely large-scale antenna arrays. For a long time, most research has focused on the angle domain of the space, overlooking the potential of the distance domain. Near-field location division multiple access (LDMA) was proposed based on the beam-focusing effect yielded by near-field spherical propagation model, partitioning channel resources by both angle and distance. To achieve a similar idea in the far-field region, this paper introduces a far-field LDMA scheme for wideband systems based on orthogonal frequency division multiplexing (OFDM). Benefiting from frequency diverse arrays (FDA), it becomes possible to manipulate beams in the distance domain. Combined with OFDM, the inherent cyclic prefix ensures a complete OFDM symbol can be received without losing distance information, while the matched filter of OFDM helps eliminate the time-variance of FDA steering vectors. Theoretical and simulation results show that LDMA can fully exploit the additional degrees of freedom in the distance domain to significantly improve spectral efficiency, especially in narrow sector multiple access (MA) scenarios. Moreover, LDMA can maintain independence between array elements even in single-path channels, making it stand out in MA schemes at millimeter-wave and higher frequency bands.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022



Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.
A Simple and Effective Method to Improve Zero-Shot Cross-Lingual Transfer Learning
Oct 18, 2022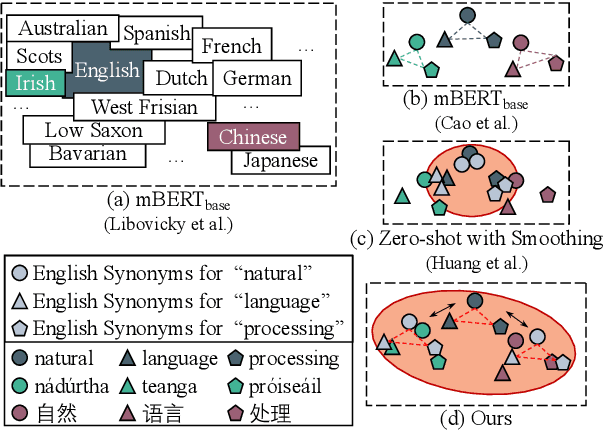
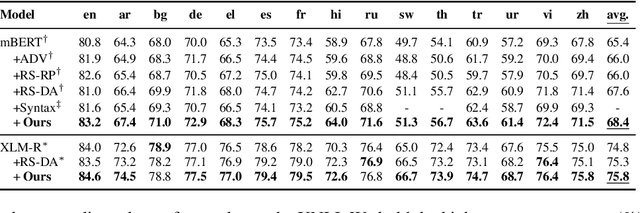
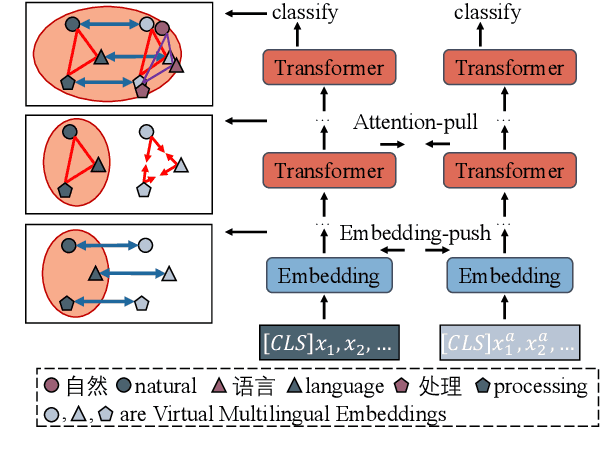
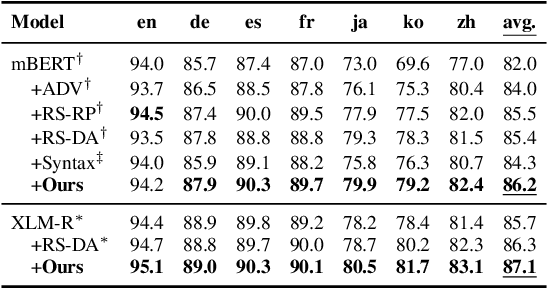
Existing zero-shot cross-lingual transfer methods rely on parallel corpora or bilingual dictionaries, which are expensive and impractical for low-resource languages. To disengage from these dependencies, researchers have explored training multilingual models on English-only resources and transferring them to low-resource languages. However, its effect is limited by the gap between embedding clusters of different languages. To address this issue, we propose Embedding-Push, Attention-Pull, and Robust targets to transfer English embeddings to virtual multilingual embeddings without semantic loss, thereby improving cross-lingual transferability. Experimental results on mBERT and XLM-R demonstrate that our method significantly outperforms previous works on the zero-shot cross-lingual text classification task and can obtain a better multilingual alignment.
SAMP: A Toolkit for Model Inference with Self-Adaptive Mixed-Precision
Sep 19, 2022
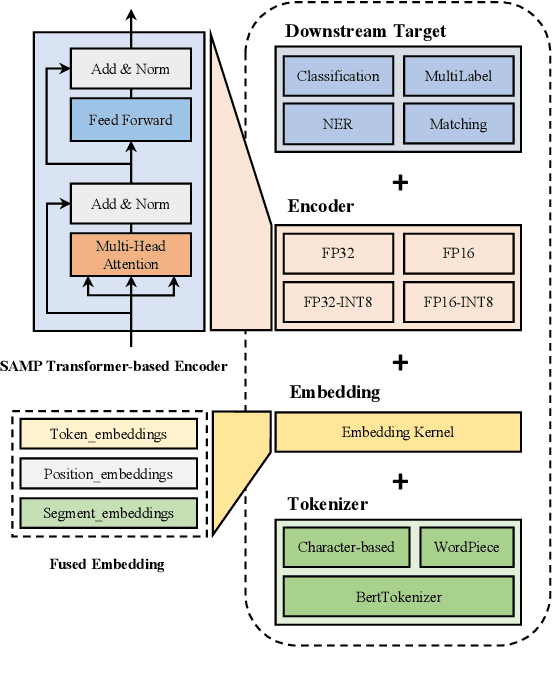
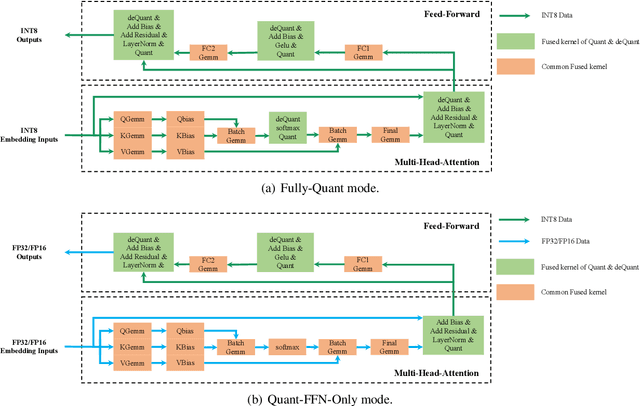
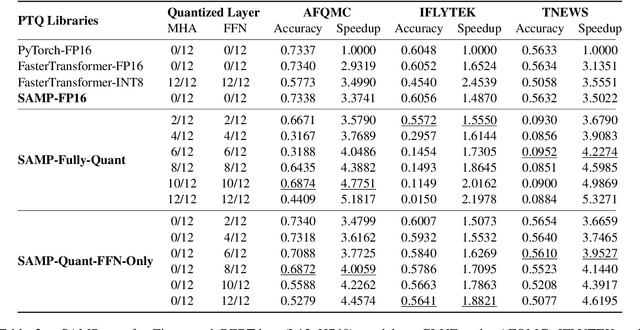
The latest industrial inference engines, such as FasterTransformer1 and TurboTransformers, have verified that half-precision floating point (FP16) and 8-bit integer (INT8) quantization can greatly improve model inference speed. However, the existing FP16 or INT8 quantization methods are too complicated, and improper usage will lead to performance damage greatly. In this paper, we develop a toolkit for users to easily quantize their models for inference, in which a Self-Adaptive Mixed-Precision (SAMP) is proposed to automatically control quantization rate by a mixed-precision architecture to balance efficiency and performance. Experimental results show that our SAMP toolkit has a higher speedup than PyTorch and FasterTransformer while ensuring the required performance. In addition, SAMP is based on a modular design, decoupling the tokenizer, embedding, encoder and target layers, which allows users to handle various downstream tasks and can be seamlessly integrated into PyTorch.
On the Characterizations of OTFS Modulation over multipath Rapid Fading Channel
Mar 30, 2021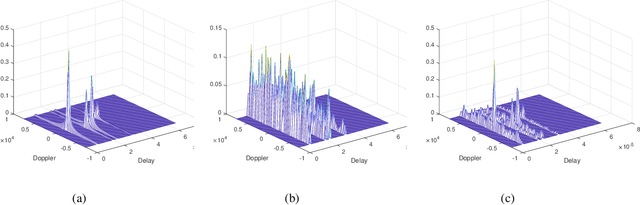
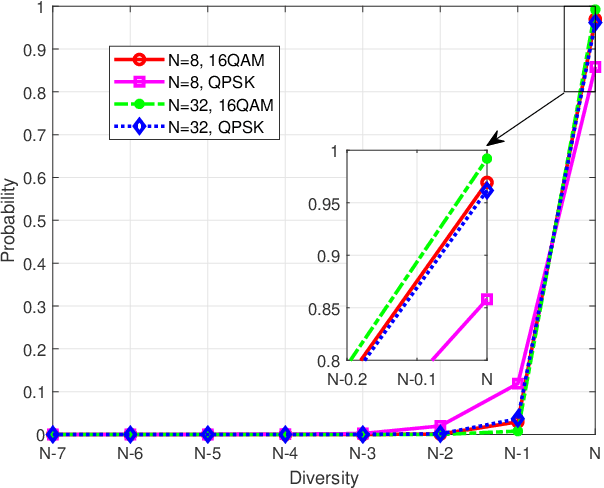
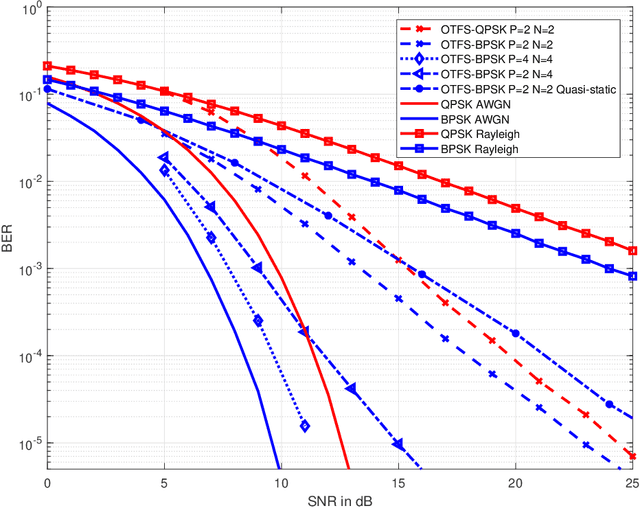
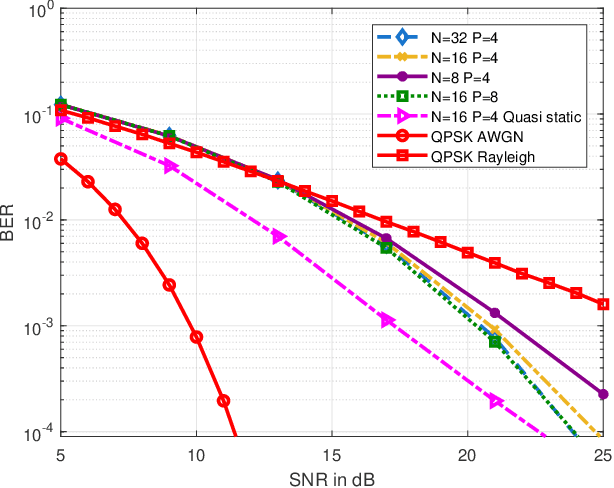
Orthogonal time frequency space (OTFS) modulation has been confirmed to provide significant performance advantages against Doppler in high-mobility scenarios. The core feature of OTFS is that the time-variant channel is converted into a non-fading 2D channel in the delay-Doppler (DD) domain so that all symbols experience the same channel gain. In now available literature, the channel is assumed to be quasi-static over an OTFS frame. As for more practical channels, the input-output relation will be time-variant as the environment or medium changes. In this paper, we analyze the characterizations of OTFS modulation over a more general multipath channel, where the signal of each path has experienced a unique rapid fading. First, we derive the explicit input-output relationship of OTFS in the DD domain for the case of ideal pulse and rectangular pulse. It is shown that the rapid fading will produce extra Doppler dispersion without impacting on delay domain. We next demonstrate that OTFS can be interpreted as an efficient time diversity technology that combines space-time encoding and interleaving. Simulation results reveal that OTFS is insensitive to rapid fading and still outperforms orthogonal frequency-division multiplexing (OFDM) in these types of channels.