 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtualMLE: A Virtual ML Engineer that Optimizes Sequential Recommenders
Jun 02, 2026Recent advancements in Large Language Models (LLMs) have demonstrated remarkable capabilities in reasoning, reflection, and tool utilization, unlocking new paradigms for automating complex engineering workflows. However, in the domain of sequential recommendation (SR), tuning models on new datasets still relies heavily on the manual trial-and-error of experienced machine learning engineers. To bridge this gap, we propose \textbf{VirtualMLE}, an LLM-agent framework that leverages the cognitive capabilities of LLMs to organize recommender optimizing into a closed loop of execution, reflection, and memory update. After each trial, the agent explicitly analyzes the observed outcomes and stores concise heuristic feedback in a hierarchical memory system. We evaluate VirtualMLE on three Amazon SR benchmarks with two representative backbones, SASRec and HSTU. VirtualMLE reaches competitive recommendation quality with substantially fewer trials. Furthermore, we observe that cognition summaries distilled from previous datasets can significantly accelerate the search process on unseen datasets, demonstrating the potential of transferring tuning heuristics. Overall, our results provide compelling evidence that LLM agents equipped with reflection and memory can serve as practical virtual engineers to automate and amortize heuristic learning in SR optimization. Our codes are available.
GLASS: A Generative Recommender for Long-sequence Modeling via SID-Tier and Semantic Search
Feb 05, 2026Leveraging long-term user behavioral patterns is a key trajectory for enhancing the accuracy of modern recommender systems. While generative recommender systems have emerged as a transformative paradigm, they face hurdles in effectively modeling extensive historical sequences. To address this challenge, we propose GLASS, a novel framework that integrates long-term user interests into the generative process via SID-Tier and Semantic Search. We first introduce SID-Tier, a module that maps long-term interactions into a unified interest vector to enhance the prediction of the initial SID token. Unlike traditional retrieval models that struggle with massive item spaces, SID-Tier leverages the compact nature of the semantic codebook to incorporate cross features between the user's long-term history and candidate semantic codes. Furthermore, we present semantic hard search, which utilizes generated coarse-grained semantic ID as dynamic keys to extract relevant historical behaviors, which are then fused via an adaptive gated fusion module to recalibrate the trajectory of subsequent fine-grained tokens. To address the inherent data sparsity in semantic hard search, we propose two strategies: semantic neighbor augmentation and codebook resizing. Extensive experiments on two large-scale real-world datasets, TAOBAO-MM and KuaiRec, demonstrate that GLASS outperforms state-of-the-art baselines, achieving significant gains in recommendation quality. Our codes are made publicly available to facilitate further research in generative recommendation.
ALPBench: A Benchmark for Attribution-level Long-term Personal Behavior Understanding
Feb 03, 2026Recent advances in large language models have highlighted their potential for personalized recommendation, where accurately capturing user preferences remains a key challenge. Leveraging their strong reasoning and generalization capabilities, LLMs offer new opportunities for modeling long-term user behavior. To systematically evaluate this, we introduce ALPBench, a Benchmark for Attribution-level Long-term Personal Behavior Understanding. Unlike item-focused benchmarks, ALPBench predicts user-interested attribute combinations, enabling ground-truth evaluation even for newly introduced items. It models preferences from long-term historical behaviors rather than users' explicitly expressed requests, better reflecting enduring interests. User histories are represented as natural language sequences, allowing interpretable, reasoning-based personalization. ALPBench enables fine-grained evaluation of personalization by focusing on the prediction of attribute combinations task that remains highly challenging for current LLMs due to the need to capture complex interactions among multiple attributes and reason over long-term user behavior sequences.
Unleashing the Native Recommendation Potential: LLM-Based Generative Recommendation via Structured Term Identifiers
Jan 11, 2026Leveraging the vast open-world knowledge and understanding capabilities of Large Language Models (LLMs) to develop general-purpose, semantically-aware recommender systems has emerged as a pivotal research direction in generative recommendation. However, existing methods face bottlenecks in constructing item identifiers. Text-based methods introduce LLMs' vast output space, leading to hallucination, while methods based on Semantic IDs (SIDs) encounter a semantic gap between SIDs and LLMs' native vocabulary, requiring costly vocabulary expansion and alignment training. To address this, this paper introduces Term IDs (TIDs), defined as a set of semantically rich and standardized textual keywords, to serve as robust item identifiers. We propose GRLM, a novel framework centered on TIDs, employs Context-aware Term Generation to convert item's metadata into standardized TIDs and utilizes Integrative Instruction Fine-tuning to collaboratively optimize term internalization and sequential recommendation. Additionally, Elastic Identifier Grounding is designed for robust item mapping. Extensive experiments on real-world datasets demonstrate that GRLM significantly outperforms baselines across multiple scenarios, pointing a promising direction for generalizable and high-performance generative recommendation systems.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
OneLoc: Geo-Aware Generative Recommender Systems for Local Life Service
Aug 20, 2025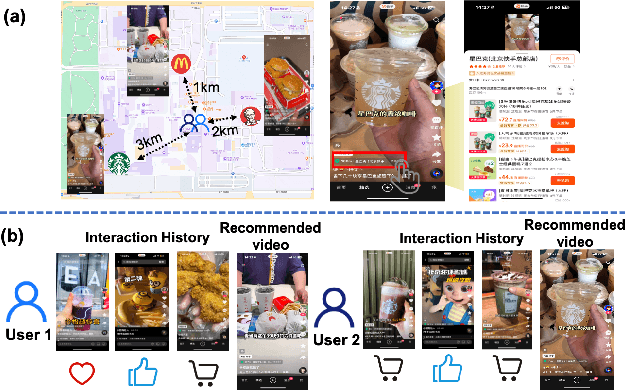
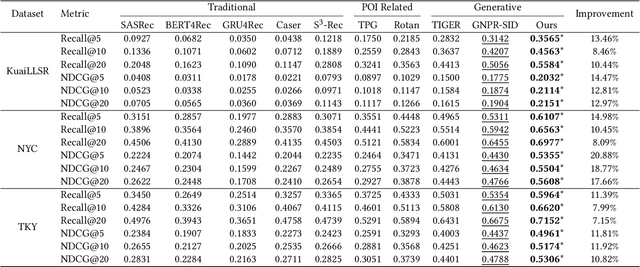
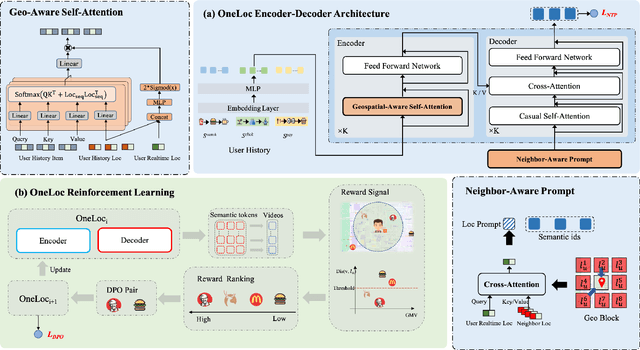

Local life service is a vital scenario in Kuaishou App, where video recommendation is intrinsically linked with store's location information. Thus, recommendation in our scenario is challenging because we should take into account user's interest and real-time location at the same time. In the face of such complex scenarios, end-to-end generative recommendation has emerged as a new paradigm, such as OneRec in the short video scenario, OneSug in the search scenario, and EGA in the advertising scenario. However, in local life service, an end-to-end generative recommendation model has not yet been developed as there are some key challenges to be solved. The first challenge is how to make full use of geographic information. The second challenge is how to balance multiple objectives, including user interests, the distance between user and stores, and some other business objectives. To address the challenges, we propose OneLoc. Specifically, we leverage geographic information from different perspectives: (1) geo-aware semantic ID incorporates both video and geographic information for tokenization, (2) geo-aware self-attention in the encoder leverages both video location similarity and user's real-time location, and (3) neighbor-aware prompt captures rich context information surrounding users for generation. To balance multiple objectives, we use reinforcement learning and propose two reward functions, i.e., geographic reward and GMV reward. With the above design, OneLoc achieves outstanding offline and online performance. In fact, OneLoc has been deployed in local life service of Kuaishou App. It serves 400 million active users daily, achieving 21.016% and 17.891% improvements in terms of gross merchandise value (GMV) and orders numbers.
MISS: Multi-Modal Tree Indexing and Searching with Lifelong Sequential Behavior for Retrieval Recommendation
Aug 20, 2025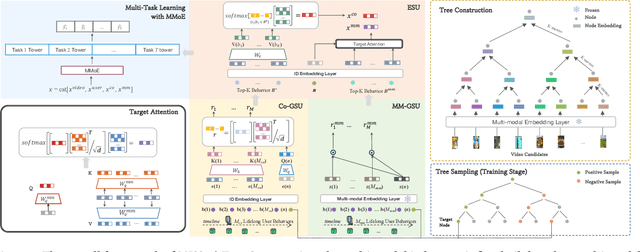
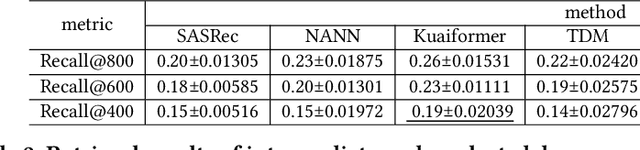
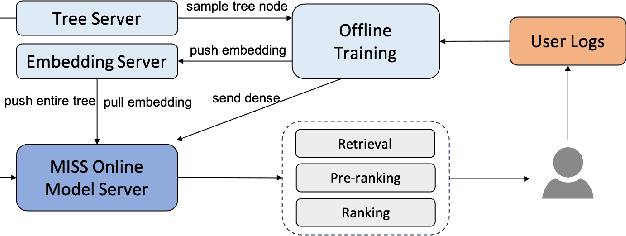
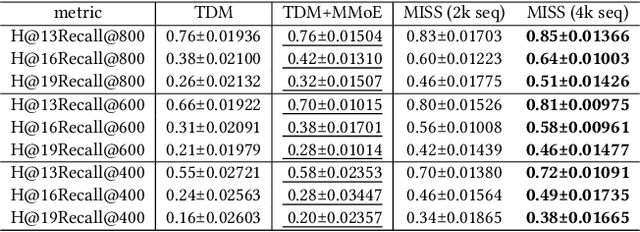
Large-scale industrial recommendation systems typically employ a two-stage paradigm of retrieval and ranking to handle huge amounts of information. Recent research focuses on improving the performance of retrieval model. A promising way is to introduce extensive information about users and items. On one hand, lifelong sequential behavior is valuable. Existing lifelong behavior modeling methods in ranking stage focus on the interaction of lifelong behavior and candidate items from retrieval stage. In retrieval stage, it is difficult to utilize lifelong behavior because of a large corpus of candidate items. On the other hand, existing retrieval methods mostly relay on interaction information, potentially disregarding valuable multi-modal information. To solve these problems, we represent the pioneering exploration of leveraging multi-modal information and lifelong sequence model within the advanced tree-based retrieval model. We propose Multi-modal Indexing and Searching with lifelong Sequence (MISS), which contains a multi-modal index tree and a multi-modal lifelong sequence modeling module. Specifically, for better index structure, we propose multi-modal index tree, which is built using the multi-modal embedding to precisely represent item similarity. To precisely capture diverse user interests in user lifelong sequence, we propose collaborative general search unit (Co-GSU) and multi-modal general search unit (MM-GSU) for multi-perspective interests searching.