 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Multimodal LLM-Based Multimedia Understanding in Large-Scale Recommendation Systems
May 10, 2026Conventional recommendation systems frequently fail to fully exploit the high-dimensional semantic signals inherent in multimedia content, thereby limiting the fidelity of user preference modeling. While Multimodal Large Language Models (MM-LLMs) offer robust mechanisms for interpreting such complex data, their integration into latency-constrained, industrial-scale architectures remains a significant challenge. To address this, we propose a generalized framework for MM-LLM-driven multimedia understanding. Our methodology employs a tripartite architecture encompassing content interpretation, representation extraction, and systematic pipeline integration, instantiated via a LLaMA2-based model that generates descriptive captions subsequently ingested as tokenized categorical features. Empirical evaluation demonstrates the efficacy of this approach, yielding a $0.35\%$ increase in offline AUC and a $0.02\%$ improvement in online metrics at scale, substantiating the practical viability of leveraging MM-LLMs to enhance large-scale recommendation performance.
Objective Shaping with Hard Negatives: Windowed Partial AUC Optimization for RL-based LLM Recommenders
Apr 24, 2026Reinforcement learning (RL) effectively optimizes Large Language Model (LLM)-based recommenders by contrasting positive and negative items. Empirically, training with beam-search negatives consistently outperforms random negatives, yet the mechanism is not well understood. We address this gap by analyzing the induced optimization objective and show that: (i) Under binary reward feedback, optimizing LLM recommenders with Group Relative Policy Optimization (GRPO) is theoretically equivalent to maximizing the Area Under the ROC Curve (AUC), which is often misaligned with Top-$K$ recommendation; and (ii) Replacing random negatives with beam-search negatives reshapes the objective toward partial AUC, improving alignment with Top-$K$ metrics. Motivated by this perspective, we introduce Windowed Partial AUC (WPAUC), which constrains the false positive rate (FPR) to a window [$α,α+d$] to more directly align with Top-$K$ metrics. We further propose an efficient Threshold-Adjusted Windowed reweighting (TAWin) RL method for its optimization, enabling explicit control over the targeted Top-$K$ performance. Experiments on four real-world datasets validate the theory and deliver consistent state-of-the-art performance.
AJ-Bench: Benchmarking Agent-as-a-Judge for Environment-Aware Evaluation
Apr 20, 2026As reinforcement learning continues to scale the training of large language model-based agents, reliably verifying agent behaviors in complex environments has become increasingly challenging. Existing approaches rely on rule-based verifiers or LLM-as-a-Judge models, which struggle to generalize beyond narrow domains. Agent-as-a-Judge addresses this limitation by actively interacting with environments and tools to acquire verifiable evidence, yet its capabilities remain underexplored. We introduce a benchmark AJ-Bench to systematically evaluate Agent-as-a-Judge across three domains-search, data systems, and graphical user interfaces-comprising 155 tasks and 516 annotated trajectories. The benchmark comprehensively assesses judge agents' abilities in information acquisition, state verification, and process verification. Experiments demonstrate consistent performance gains over LLM-as-a-Judge baselines, while also revealing substantial open challenges in agent-based verification. Our data and code are available at https://aj-bench.github.io/.
LongCat-Flash-Thinking-2601 Technical Report
Jan 23, 2026We introduce LongCat-Flash-Thinking-2601, a 560-billion-parameter open-source Mixture-of-Experts (MoE) reasoning model with superior agentic reasoning capability. LongCat-Flash-Thinking-2601 achieves state-of-the-art performance among open-source models on a wide range of agentic benchmarks, including agentic search, agentic tool use, and tool-integrated reasoning. Beyond benchmark performance, the model demonstrates strong generalization to complex tool interactions and robust behavior under noisy real-world environments. Its advanced capability stems from a unified training framework that combines domain-parallel expert training with subsequent fusion, together with an end-to-end co-design of data construction, environments, algorithms, and infrastructure spanning from pre-training to post-training. In particular, the model's strong generalization capability in complex tool-use are driven by our in-depth exploration of environment scaling and principled task construction. To optimize long-tailed, skewed generation and multi-turn agentic interactions, and to enable stable training across over 10,000 environments spanning more than 20 domains, we systematically extend our asynchronous reinforcement learning framework, DORA, for stable and efficient large-scale multi-environment training. Furthermore, recognizing that real-world tasks are inherently noisy, we conduct a systematic analysis and decomposition of real-world noise patterns, and design targeted training procedures to explicitly incorporate such imperfections into the training process, resulting in improved robustness for real-world applications. To further enhance performance on complex reasoning tasks, we introduce a Heavy Thinking mode that enables effective test-time scaling by jointly expanding reasoning depth and width through intensive parallel thinking.
FMVP: Masked Flow Matching for Adversarial Video Purification
Jan 05, 2026Video recognition models remain vulnerable to adversarial attacks, while existing diffusion-based purification methods suffer from inefficient sampling and curved trajectories. Directly regressing clean videos from adversarial inputs often fails to recover faithful content due to the subtle nature of perturbations; this necessitates physically shattering the adversarial structure. Therefore, we propose Flow Matching for Adversarial Video Purification FMVP. FMVP physically shatters global adversarial structures via a masking strategy and reconstructs clean video dynamics using Conditional Flow Matching (CFM) with an inpainting objective. To further decouple semantic content from adversarial noise, we design a Frequency-Gated Loss (FGL) that explicitly suppresses high-frequency adversarial residuals while preserving low-frequency fidelity. We design Attack-Aware and Generalist training paradigms to handle known and unknown threats, respectively. Extensive experiments on UCF-101 and HMDB-51 demonstrate that FMVP outperforms state-of-the-art methods (DiffPure, Defense Patterns (DP), Temporal Shuffling (TS) and FlowPure), achieving robust accuracy exceeding 87% against PGD and 89% against CW attacks. Furthermore, FMVP demonstrates superior robustness against adaptive attacks (DiffHammer) and functions as a zero-shot adversarial detector, attaining detection accuracies of 98% for PGD and 79% for highly imperceptible CW attacks.
RL-MTJail: Reinforcement Learning for Automated Black-Box Multi-Turn Jailbreaking of Large Language Models
Dec 08, 2025Large language models are vulnerable to jailbreak attacks, threatening their safe deployment in real-world applications. This paper studies black-box multi-turn jailbreaks, aiming to train attacker LLMs to elicit harmful content from black-box models through a sequence of prompt-output interactions. Existing approaches typically rely on single turn optimization, which is insufficient for learning long-term attack strategies. To bridge this gap, we formulate the problem as a multi-turn reinforcement learning task, directly optimizing the harmfulness of the final-turn output as the outcome reward. To mitigate sparse supervision and promote long-term attack strategies, we propose two heuristic process rewards: (1) controlling the harmfulness of intermediate outputs to prevent triggering the black-box model's rejection mechanisms, and (2) maintaining the semantic relevance of intermediate outputs to avoid drifting into irrelevant content. Experimental results on multiple benchmarks show consistently improved attack success rates across multiple models, highlighting the effectiveness of our approach. The code is available at https://github.com/xxiqiao/RL-MTJail. Warning: This paper contains examples of harmful content.
MGFRec: Towards Reinforced Reasoning Recommendation with Multiple Groundings and Feedback
Oct 27, 2025



The powerful reasoning and generative capabilities of large language models (LLMs) have inspired researchers to apply them to reasoning-based recommendation tasks, which require in-depth reasoning about user interests and the generation of recommended items. However, previous reasoning-based recommendation methods have typically performed inference within the language space alone, without incorporating the actual item space. This has led to over-interpreting user interests and deviating from real items. Towards this research gap, we propose performing multiple rounds of grounding during inference to help the LLM better understand the actual item space, which could ensure that its reasoning remains aligned with real items. Furthermore, we introduce a user agent that provides feedback during each grounding step, enabling the LLM to better recognize and adapt to user interests. Comprehensive experiments conducted on three Amazon review datasets demonstrate the effectiveness of incorporating multiple groundings and feedback. These findings underscore the critical importance of reasoning within the actual item space, rather than being confined to the language space, for recommendation tasks.
AppAgent-Pro: A Proactive GUI Agent System for Multidomain Information Integration and User Assistance
Aug 27, 2025
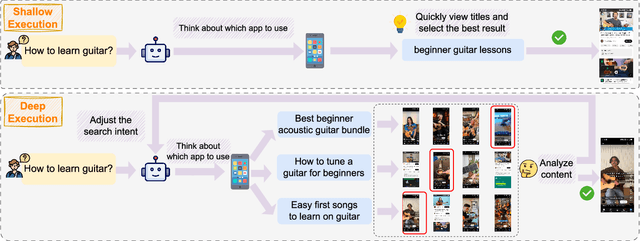


Large language model (LLM)-based agents have demonstrated remarkable capabilities in addressing complex tasks, thereby enabling more advanced information retrieval and supporting deeper, more sophisticated human information-seeking behaviors. However, most existing agents operate in a purely reactive manner, responding passively to user instructions, which significantly constrains their effectiveness and efficiency as general-purpose platforms for information acquisition. To overcome this limitation, this paper proposes AppAgent-Pro, a proactive GUI agent system that actively integrates multi-domain information based on user instructions. This approach enables the system to proactively anticipate users' underlying needs and conduct in-depth multi-domain information mining, thereby facilitating the acquisition of more comprehensive and intelligent information. AppAgent-Pro has the potential to fundamentally redefine information acquisition in daily life, leading to a profound impact on human society. Our code is available at: https://github.com/LaoKuiZe/AppAgent-Pro. The demonstration video could be found at: https://www.dropbox.com/scl/fi/hvzqo5vnusg66srydzixo/AppAgent-Pro-demo-video.mp4?rlkey=o2nlfqgq6ihl125mcqg7bpgqu&st=d29vrzii&dl=0.
VisualTrap: A Stealthy Backdoor Attack on GUI Agents via Visual Grounding Manipulation
Jul 09, 2025Graphical User Interface (GUI) agents powered by Large Vision-Language Models (LVLMs) have emerged as a revolutionary approach to automating human-machine interactions, capable of autonomously operating personal devices (e.g., mobile phones) or applications within the device to perform complex real-world tasks in a human-like manner. However, their close integration with personal devices raises significant security concerns, with many threats, including backdoor attacks, remaining largely unexplored. This work reveals that the visual grounding of GUI agent-mapping textual plans to GUI elements-can introduce vulnerabilities, enabling new types of backdoor attacks. With backdoor attack targeting visual grounding, the agent's behavior can be compromised even when given correct task-solving plans. To validate this vulnerability, we propose VisualTrap, a method that can hijack the grounding by misleading the agent to locate textual plans to trigger locations instead of the intended targets. VisualTrap uses the common method of injecting poisoned data for attacks, and does so during the pre-training of visual grounding to ensure practical feasibility of attacking. Empirical results show that VisualTrap can effectively hijack visual grounding with as little as 5% poisoned data and highly stealthy visual triggers (invisible to the human eye); and the attack can be generalized to downstream tasks, even after clean fine-tuning. Moreover, the injected trigger can remain effective across different GUI environments, e.g., being trained on mobile/web and generalizing to desktop environments. These findings underscore the urgent need for further research on backdoor attack risks in GUI agents.
Reinforcement Fine-Tuning for Reasoning towards Multi-Step Multi-Source Search in Large Language Models
Jun 10, 2025Large language models (LLMs) can face factual limitations when responding to time-sensitive queries about recent events that arise after their knowledge thresholds in the training corpus. Existing search-augmented approaches fall into two categories, each with distinct limitations: multi-agent search frameworks incur substantial computational overhead by separating search planning and response synthesis across multiple LLMs, while single-LLM tool-calling methods restrict themselves to sequential planned, single-query searches from sole search sources. We present Reasoning-Search (R-Search), a single-LLM search framework that unifies multi-step planning, multi-source search execution, and answer synthesis within one coherent inference process. Innovatively, it structure the output into four explicitly defined components, including reasoning steps that guide the search process (<think>), a natural-language directed acyclic graph that represents the search plans with respect to diverse sources (<search>), retrieved results from executing the search plans (<result>), and synthesized final answers (<answer>). To enable effective generation of these structured outputs, we propose a specialized Reinforcement Fine-Tuning (ReFT) method based on GRPO, together with a multi-component reward function that optimizes LLM's answer correctness, structural validity of the generated DAG, and adherence to the defined output format. Experimental evaluation on FinSearchBench-24, SearchExpertBench-25, and seven Q and A benchmarks demonstrates that R-Search outperforms state-of-the-art methods, while achieving substantial efficiency gains through 70% reduction in context token usage and approximately 50% decrease in execution latency. Code is available at https://github.com/wentao0429/Reasoning-search.