 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Coherent Narratives by Learning Dynamic and Discrete Entity States with a Contrastive Framework
Aug 08, 2022
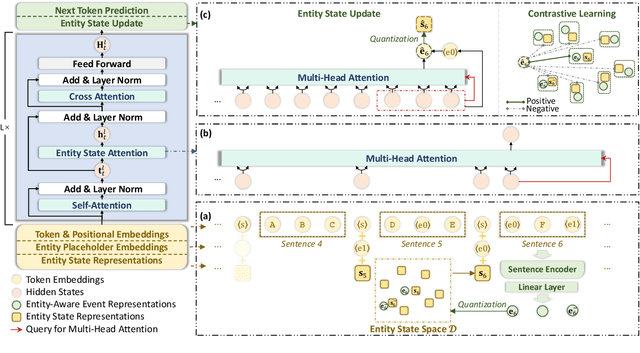
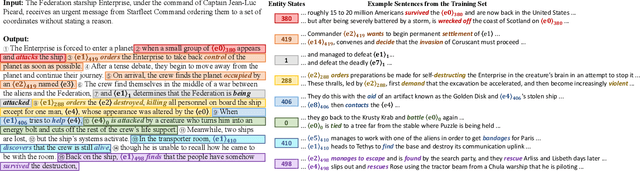
Despite advances in generating fluent texts, existing pretraining models tend to attach incoherent event sequences to involved entities when generating narratives such as stories and news. We conjecture that such issues result from representing entities as static embeddings of superficial words, while neglecting to model their ever-changing states, i.e., the information they carry, as the text unfolds. Therefore, we extend the Transformer model to dynamically conduct entity state updates and sentence realization for narrative generation. We propose a contrastive framework to learn the state representations in a discrete space, and insert additional attention layers into the decoder to better exploit these states. Experiments on two narrative datasets show that our model can generate more coherent and diverse narratives than strong baselines with the guidance of meaningful entity states.
On the Learning of Non-Autoregressive Transformers
Jun 13, 2022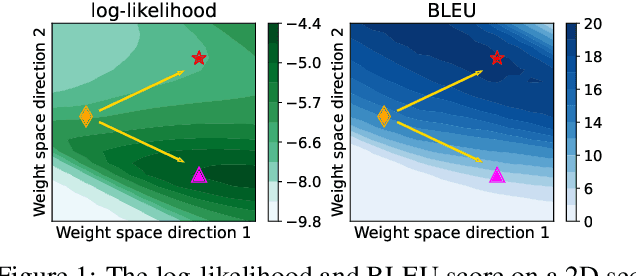
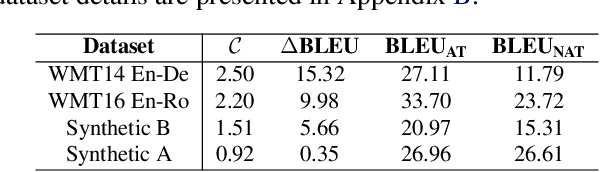
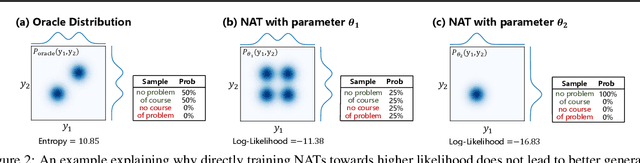
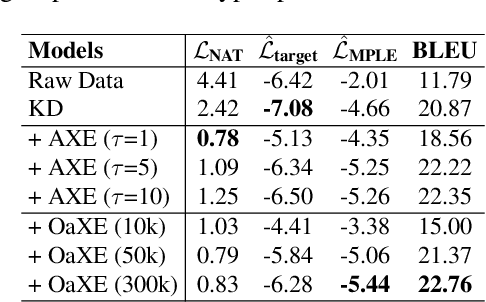
Non-autoregressive Transformer (NAT) is a family of text generation models, which aims to reduce the decoding latency by predicting the whole sentences in parallel. However, such latency reduction sacrifices the ability to capture left-to-right dependencies, thereby making NAT learning very challenging. In this paper, we present theoretical and empirical analyses to reveal the challenges of NAT learning and propose a unified perspective to understand existing successes. First, we show that simply training NAT by maximizing the likelihood can lead to an approximation of marginal distributions but drops all dependencies between tokens, where the dropped information can be measured by the dataset's conditional total correlation. Second, we formalize many previous objectives in a unified framework and show that their success can be concluded as maximizing the likelihood on a proxy distribution, leading to a reduced information loss. Empirical studies show that our perspective can explain the phenomena in NAT learning and guide the design of new training methods.
Curriculum-Based Self-Training Makes Better Few-Shot Learners for Data-to-Text Generation
Jun 06, 2022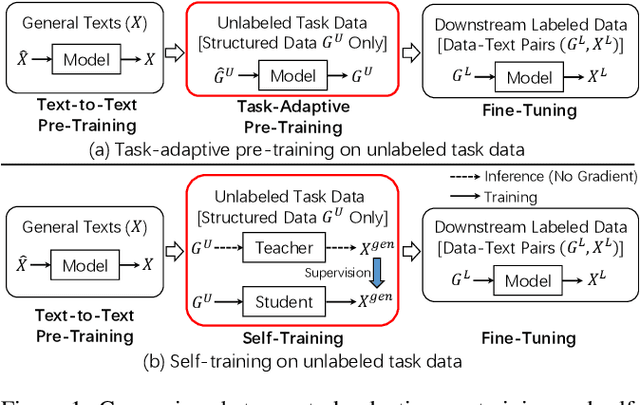


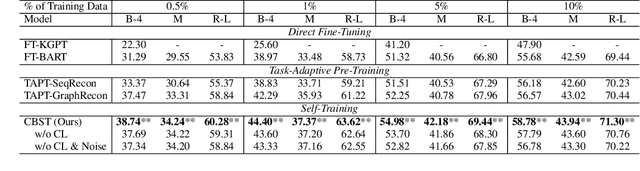
Despite the success of text-to-text pre-trained models in various natural language generation (NLG) tasks, the generation performance is largely restricted by the number of labeled data in downstream tasks, particularly in data-to-text generation tasks. Existing works mostly utilize abundant unlabeled structured data to conduct unsupervised pre-training for task adaption, which fail to model the complex relationship between source structured data and target texts. Thus, we introduce self-training as a better few-shot learner than task-adaptive pre-training, which explicitly captures this relationship via pseudo-labeled data generated by the pre-trained model. To alleviate the side-effect of low-quality pseudo-labeled data during self-training, we propose a novel method called Curriculum-Based Self-Training (CBST) to effectively leverage unlabeled data in a rearranged order determined by the difficulty of text generation. Experimental results show that our method can outperform fine-tuning and task-adaptive pre-training methods, and achieve state-of-the-art performance in the few-shot setting of data-to-text generation.
CPED: A Large-Scale Chinese Personalized and Emotional Dialogue Dataset for Conversational AI
May 29, 2022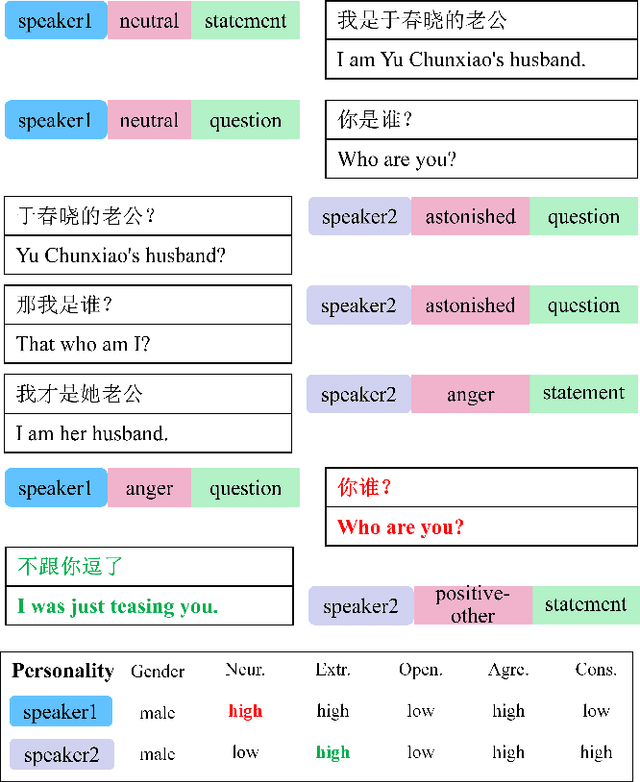

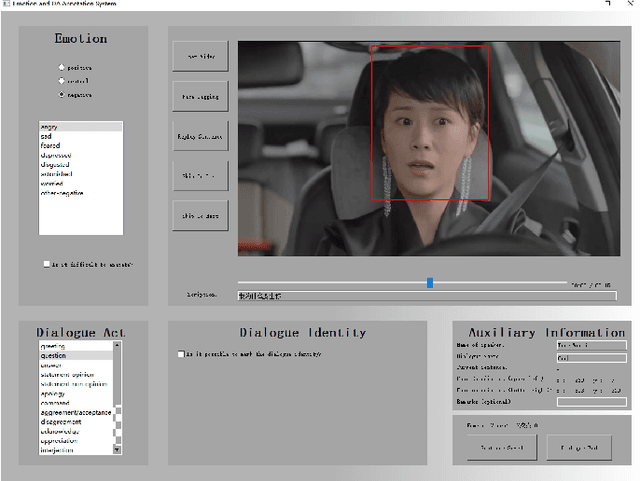
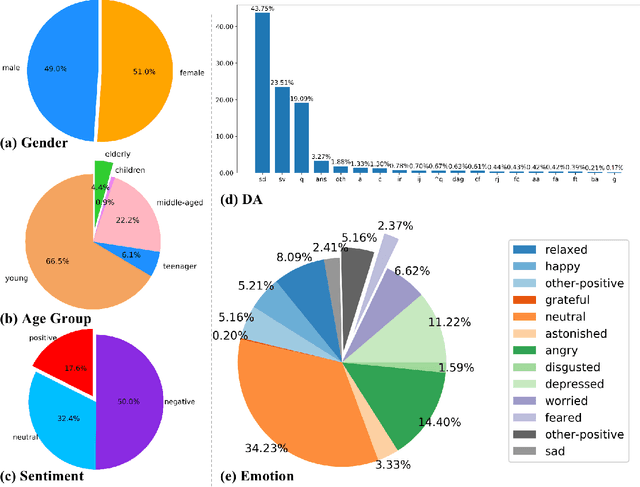
Human language expression is based on the subjective construal of the situation instead of the objective truth conditions, which means that speakers' personalities and emotions after cognitive processing have an important influence on conversation. However, most existing datasets for conversational AI ignore human personalities and emotions, or only consider part of them. It's difficult for dialogue systems to understand speakers' personalities and emotions although large-scale pre-training language models have been widely used. In order to consider both personalities and emotions in the process of conversation generation, we propose CPED, a large-scale Chinese personalized and emotional dialogue dataset, which consists of multi-source knowledge related to empathy and personal characteristic. These knowledge covers gender, Big Five personality traits, 13 emotions, 19 dialogue acts and 10 scenes. CPED contains more than 12K dialogues of 392 speakers from 40 TV shows. We release the textual dataset with audio features and video features according to the copyright claims, privacy issues, terms of service of video platforms. We provide detailed description of the CPED construction process and introduce three tasks for conversational AI, including personality recognition, emotion recognition in conversations as well as personalized and emotional conversation generation. Finally, we provide baseline systems for these tasks and consider the function of speakers' personalities and emotions on conversation. Our motivation is to propose a dataset to be widely adopted by the NLP community as a new open benchmark for conversational AI research. The full dataset is available at https://github.com/scutcyr/CPED.
Many-Class Text Classification with Matching
May 23, 2022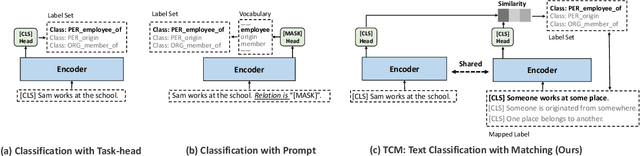
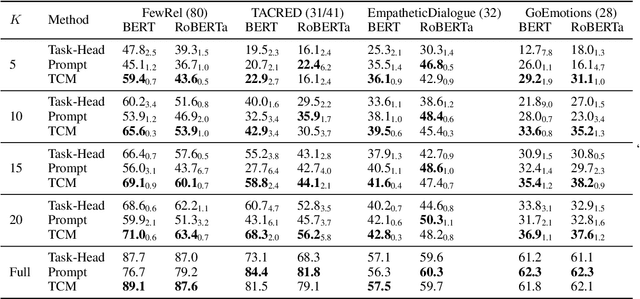
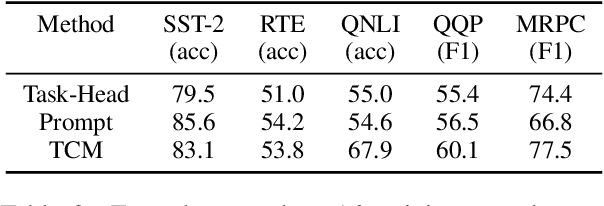
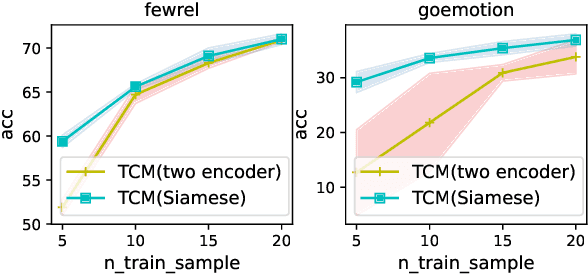
In this work, we formulate \textbf{T}ext \textbf{C}lassification as a \textbf{M}atching problem between the text and the labels, and propose a simple yet effective framework named TCM. Compared with previous text classification approaches, TCM takes advantage of the fine-grained semantic information of the classification labels, which helps distinguish each class better when the class number is large, especially in low-resource scenarios. TCM is also easy to implement and is compatible with various large pretrained language models. We evaluate TCM on 4 text classification datasets (each with 20+ labels) in both few-shot and full-data settings, and this model demonstrates significant improvements over other text classification paradigms. We also conduct extensive experiments with different variants of TCM and discuss the underlying factors of its success. Our method and analyses offer a new perspective on text classification.
Directed Acyclic Transformer for Non-Autoregressive Machine Translation
May 16, 2022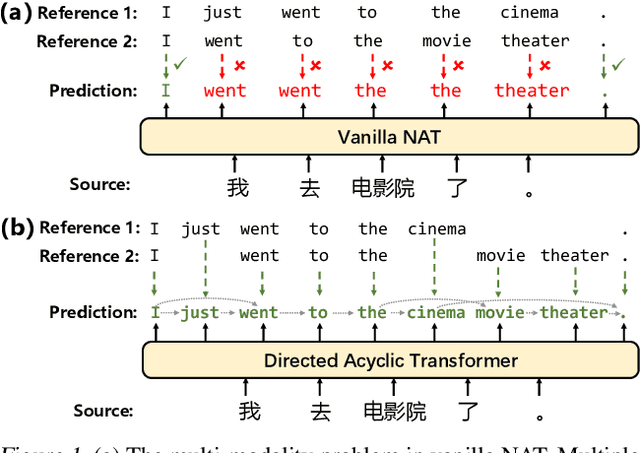
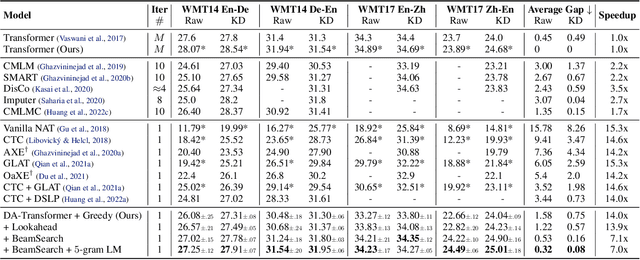
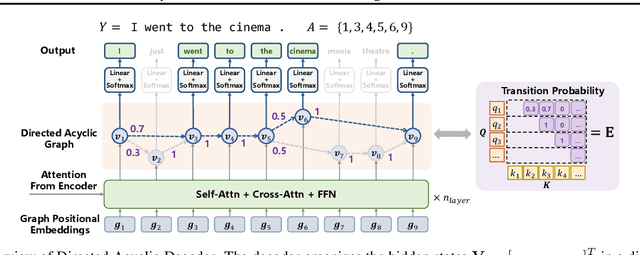
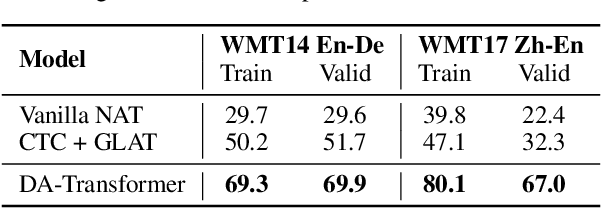
Non-autoregressive Transformers (NATs) significantly reduce the decoding latency by generating all tokens in parallel. However, such independent predictions prevent NATs from capturing the dependencies between the tokens for generating multiple possible translations. In this paper, we propose Directed Acyclic Transfomer (DA-Transformer), which represents the hidden states in a Directed Acyclic Graph (DAG), where each path of the DAG corresponds to a specific translation. The whole DAG simultaneously captures multiple translations and facilitates fast predictions in a non-autoregressive fashion. Experiments on the raw training data of WMT benchmark show that DA-Transformer substantially outperforms previous NATs by about 3 BLEU on average, which is the first NAT model that achieves competitive results with autoregressive Transformers without relying on knowledge distillation.
LaMemo: Language Modeling with Look-Ahead Memory
Apr 26, 2022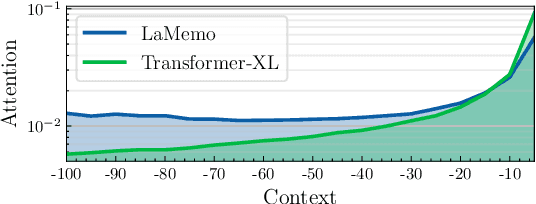

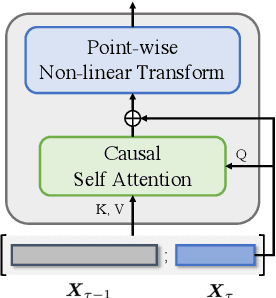
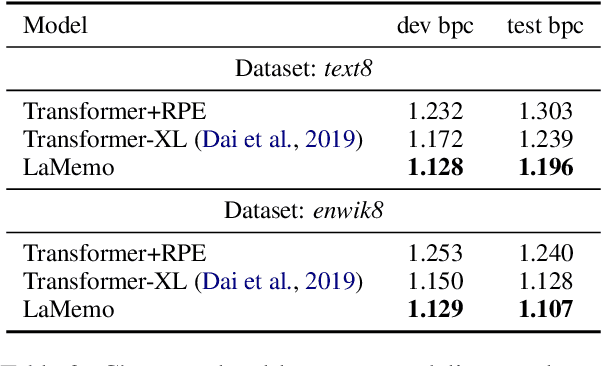
Although Transformers with fully connected self-attentions are powerful to model long-term dependencies, they are struggling to scale to long texts with thousands of words in language modeling. One of the solutions is to equip the model with a recurrence memory. However, existing approaches directly reuse hidden states from the previous segment that encodes contexts in a uni-directional way. As a result, this prohibits the memory to dynamically interact with the current context that provides up-to-date information for token prediction. To remedy this issue, we propose Look-Ahead Memory (LaMemo) that enhances the recurrence memory by incrementally attending to the right-side tokens, and interpolating with the old memory states to maintain long-term information in the history. LaMemo embraces bi-directional attention and segment recurrence with an additional computation overhead only linearly proportional to the memory length. Experiments on widely used language modeling benchmarks demonstrate its superiority over the baselines equipped with different types of memory.
Persona-Guided Planning for Controlling the Protagonist's Persona in Story Generation
Apr 22, 2022
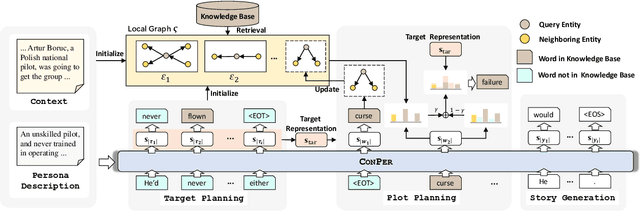
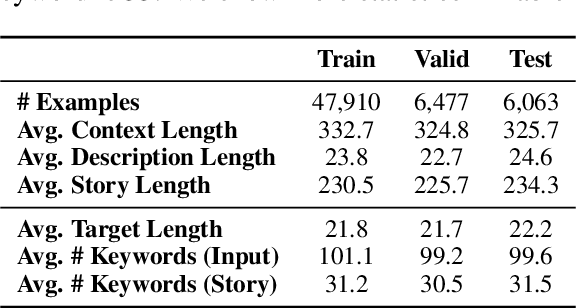
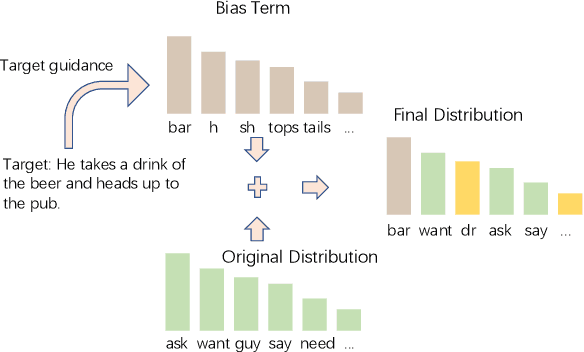
Endowing the protagonist with a specific personality is essential for writing an engaging story. In this paper, we aim to control the protagonist's persona in story generation, i.e., generating a story from a leading context and a persona description, where the protagonist should exhibit the specified personality through a coherent event sequence. Considering that personas are usually embodied implicitly and sparsely in stories, we propose a planning-based generation model named CONPER to explicitly model the relationship between personas and events. CONPER first plans events of the protagonist's behavior which are motivated by the specified persona through predicting one target sentence, then plans the plot as a sequence of keywords with the guidance of the predicted persona-related events and commonsense knowledge, and finally generates the whole story. Both automatic and manual evaluation results demonstrate that CONPER outperforms state-of-the-art baselines for generating more coherent and persona-controllable stories.
A Corpus for Understanding and Generating Moral Stories
Apr 20, 2022


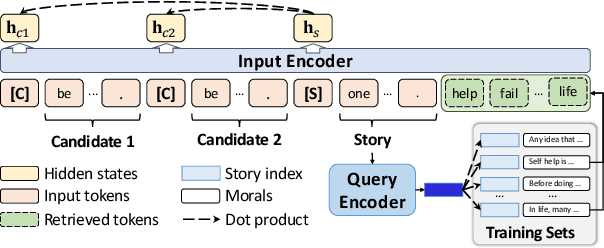
Teaching morals is one of the most important purposes of storytelling. An essential ability for understanding and writing moral stories is bridging story plots and implied morals. Its challenges mainly lie in: (1) grasping knowledge about abstract concepts in morals, (2) capturing inter-event discourse relations in stories, and (3) aligning value preferences of stories and morals concerning good or bad behavior. In this paper, we propose two understanding tasks and two generation tasks to assess these abilities of machines. We present STORAL, a new dataset of Chinese and English human-written moral stories. We show the difficulty of the proposed tasks by testing various models with automatic and manual evaluation on STORAL. Furthermore, we present a retrieval-augmented algorithm that effectively exploits related concepts or events in training sets as additional guidance to improve performance on these tasks.
Rethinking and Refining the Distinct Metric
Apr 03, 2022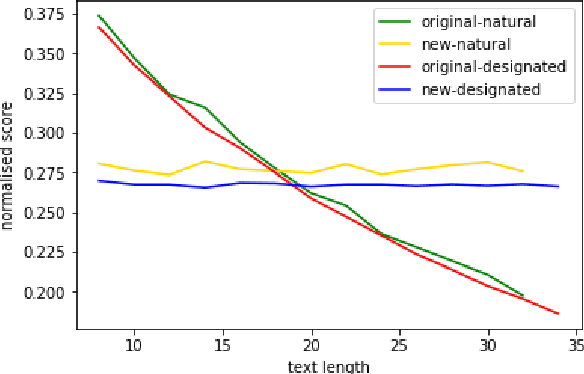
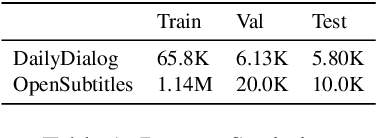

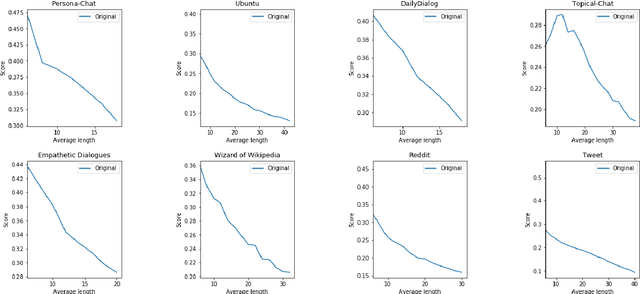
Distinct-$n$ score\cite{Li2016} is a widely used automatic metric for evaluating diversity in language generation tasks. However, we observed that the original approach for calculating distinct scores has evident biases that tend to assign higher penalties to longer sequences. We refine the calculation of distinct scores by scaling the number of distinct tokens based on their expectations. We provide both empirical and theoretical evidence to show that our method effectively removes the biases existing in the original distinct score. Our experiments show that our proposed metric, \textit{Expectation-Adjusted Distinct (EAD)}, correlates better with human judgment in evaluating response diversity. To foster future research, we provide an example implementation at \url{https://github.com/lsy641/Expectation-Adjusted-Distinct}.