 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs are Biased Evaluators But Not Biased for Retrieval Augmented Generation
Oct 28, 2024



Recent studies have demonstrated that large language models (LLMs) exhibit significant biases in evaluation tasks, particularly in preferentially rating and favoring self-generated content. However, the extent to which this bias manifests in fact-oriented tasks, especially within retrieval-augmented generation (RAG) frameworks-where keyword extraction and factual accuracy take precedence over stylistic elements-remains unclear. Our study addresses this knowledge gap by simulating two critical phases of the RAG framework. In the first phase, we access the suitability of human-authored versus model-generated passages, emulating the pointwise reranking process. The second phase involves conducting pairwise reading comprehension tests to simulate the generation process. Contrary to previous findings indicating a self-preference in rating tasks, our results reveal no significant self-preference effect in RAG frameworks. Instead, we observe that factual accuracy significantly influences LLMs' output, even in the absence of prior knowledge. Our research contributes to the ongoing discourse on LLM biases and their implications for RAG-based system, offering insights that may inform the development of more robust and unbiased LLM systems.
FactAlign: Long-form Factuality Alignment of Large Language Models
Oct 02, 2024



Large language models have demonstrated significant potential as the next-generation information access engines. However, their reliability is hindered by issues of hallucination and generating non-factual content. This is particularly problematic in long-form responses, where assessing and ensuring factual accuracy is complex. In this paper, we address this gap by proposing FactAlign, a novel alignment framework designed to enhance the factuality of LLMs' long-form responses while maintaining their helpfulness. We introduce fKTO, a fine-grained, sentence-level alignment algorithm that extends the Kahneman-Tversky Optimization (KTO) alignment method. Leveraging recent advances in automatic factuality evaluation, FactAlign utilizes fine-grained factuality assessments to guide the alignment process. Our experiments on open-domain prompts and information-seeking questions demonstrate that FactAlign significantly improves the factual accuracy of LLM responses while also improving their helpfulness. Further analyses identify that FactAlign is capable of training LLMs to provide more information without losing factual precision, thus improving the factual F1 score. Our source code, datasets, and trained models are publicly available at https://github.com/MiuLab/FactAlign
PairDistill: Pairwise Relevance Distillation for Dense Retrieval
Oct 02, 2024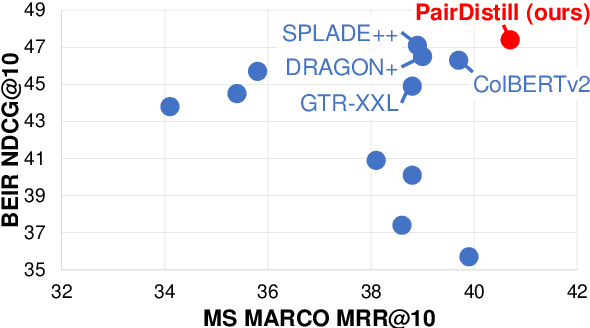
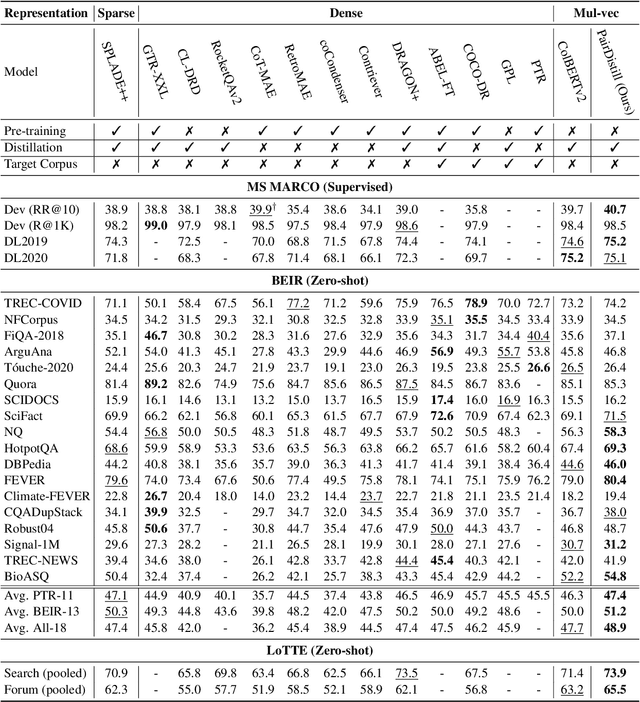
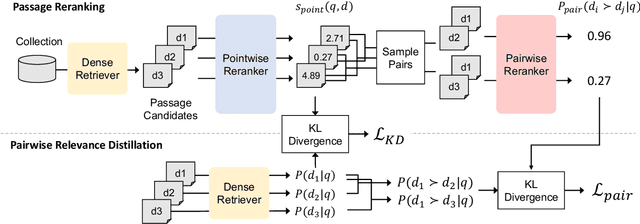
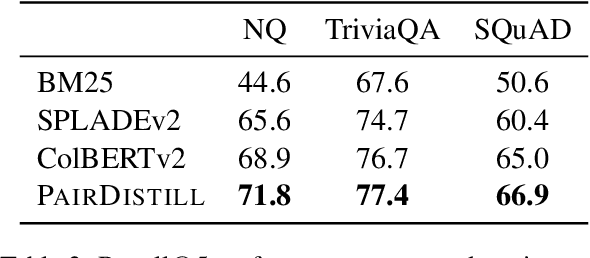
Effective information retrieval (IR) from vast datasets relies on advanced techniques to extract relevant information in response to queries. Recent advancements in dense retrieval have showcased remarkable efficacy compared to traditional sparse retrieval methods. To further enhance retrieval performance, knowledge distillation techniques, often leveraging robust cross-encoder rerankers, have been extensively explored. However, existing approaches primarily distill knowledge from pointwise rerankers, which assign absolute relevance scores to documents, thus facing challenges related to inconsistent comparisons. This paper introduces Pairwise Relevance Distillation (PairDistill) to leverage pairwise reranking, offering fine-grained distinctions between similarly relevant documents to enrich the training of dense retrieval models. Our experiments demonstrate that PairDistill outperforms existing methods, achieving new state-of-the-art results across multiple benchmarks. This highlights the potential of PairDistill in advancing dense retrieval techniques effectively. Our source code and trained models are released at https://github.com/MiuLab/PairDistill
Investigating Decoder-only Large Language Models for Speech-to-text Translation
Jul 03, 2024



Large language models (LLMs), known for their exceptional reasoning capabilities, generalizability, and fluency across diverse domains, present a promising avenue for enhancing speech-related tasks. In this paper, we focus on integrating decoder-only LLMs to the task of speech-to-text translation (S2TT). We propose a decoder-only architecture that enables the LLM to directly consume the encoded speech representation and generate the text translation. Additionally, we investigate the effects of different parameter-efficient fine-tuning techniques and task formulation. Our model achieves state-of-the-art performance on CoVoST 2 and FLEURS among models trained without proprietary data. We also conduct analyses to validate the design choices of our proposed model and bring insights to the integration of LLMs to S2TT.
A Survey of Generative Information Retrieval
Jun 04, 2024Generative Retrieval (GR) is an emerging paradigm in information retrieval that leverages generative models to directly map queries to relevant document identifiers (DocIDs) without the need for traditional query processing or document reranking. This survey provides a comprehensive overview of GR, highlighting key developments, indexing and retrieval strategies, and challenges. We discuss various document identifier strategies, including numerical and string-based identifiers, and explore different document representation methods. Our primary contribution lies in outlining future research directions that could profoundly impact the field: improving the quality of query generation, exploring learnable document identifiers, enhancing scalability, and integrating GR with multi-task learning frameworks. By examining state-of-the-art GR techniques and their applications, this survey aims to provide a foundational understanding of GR and inspire further innovations in this transformative approach to information retrieval. We also make the complementary materials such as paper collection publicly available at https://github.com/MiuLab/GenIR-Survey/
Two Tales of Persona in LLMs: A Survey of Role-Playing and Personalization
Jun 03, 2024



Recently, methods investigating how to adapt large language models (LLMs) for specific scenarios have gained great attention. Particularly, the concept of \textit{persona}, originally adopted in dialogue literature, has re-surged as a promising avenue. However, the growing research on persona is relatively disorganized, lacking a systematic overview. To close the gap, we present a comprehensive survey to categorize the current state of the field. We identify two lines of research, namely (1) LLM Role-Playing, where personas are assigned to LLMs, and (2) LLM Personalization, where LLMs take care of user personas. To the best of our knowledge, we present the first survey tailored for LLM role-playing and LLM personalization under the unified view of persona, including taxonomy, current challenges, and potential directions. To foster future endeavors, we actively maintain a paper collection available to the community: https://github.com/MiuLab/PersonaLLM-Survey
Editing the Mind of Giants: An In-Depth Exploration of Pitfalls of Knowledge Editing in Large Language Models
Jun 03, 2024Knowledge editing is a rising technique for efficiently updating factual knowledge in Large Language Models (LLMs) with minimal alteration of parameters. However, recent studies have identified concerning side effects, such as knowledge distortion and the deterioration of general abilities, that have emerged after editing. This survey presents a comprehensive study of these side effects, providing a unified view of the challenges associated with knowledge editing in LLMs. We discuss related works and summarize potential research directions to overcome these limitations. Our work highlights the limitations of current knowledge editing methods, emphasizing the need for deeper understanding of inner knowledge structures of LLMs and improved knowledge editing methods. To foster future research, we have released the complementary materials such as paper collection publicly at https://github.com/MiuLab/EditLLM-Survey
InstUPR : Instruction-based Unsupervised Passage Reranking with Large Language Models
Mar 25, 2024This paper introduces InstUPR, an unsupervised passage reranking method based on large language models (LLMs). Different from existing approaches that rely on extensive training with query-document pairs or retrieval-specific instructions, our method leverages the instruction-following capabilities of instruction-tuned LLMs for passage reranking without any additional fine-tuning. To achieve this, we introduce a soft score aggregation technique and employ pairwise reranking for unsupervised passage reranking. Experiments on the BEIR benchmark demonstrate that InstUPR outperforms unsupervised baselines as well as an instruction-tuned reranker, highlighting its effectiveness and superiority. Source code to reproduce all experiments is open-sourced at https://github.com/MiuLab/InstUPR
Unsupervised Multilingual Dense Retrieval via Generative Pseudo Labeling
Mar 06, 2024Dense retrieval methods have demonstrated promising performance in multilingual information retrieval, where queries and documents can be in different languages. However, dense retrievers typically require a substantial amount of paired data, which poses even greater challenges in multilingual scenarios. This paper introduces UMR, an Unsupervised Multilingual dense Retriever trained without any paired data. Our approach leverages the sequence likelihood estimation capabilities of multilingual language models to acquire pseudo labels for training dense retrievers. We propose a two-stage framework which iteratively improves the performance of multilingual dense retrievers. Experimental results on two benchmark datasets show that UMR outperforms supervised baselines, showcasing the potential of training multilingual retrievers without paired data, thereby enhancing their practicality. Our source code, data, and models are publicly available at https://github.com/MiuLab/UMR
CONVERSER: Few-Shot Conversational Dense Retrieval with Synthetic Data Generation
Sep 13, 2023Conversational search provides a natural interface for information retrieval (IR). Recent approaches have demonstrated promising results in applying dense retrieval to conversational IR. However, training dense retrievers requires large amounts of in-domain paired data. This hinders the development of conversational dense retrievers, as abundant in-domain conversations are expensive to collect. In this paper, we propose CONVERSER, a framework for training conversational dense retrievers with at most 6 examples of in-domain dialogues. Specifically, we utilize the in-context learning capability of large language models to generate conversational queries given a passage in the retrieval corpus. Experimental results on conversational retrieval benchmarks OR-QuAC and TREC CAsT 19 show that the proposed CONVERSER achieves comparable performance to fully-supervised models, demonstrating the effectiveness of our proposed framework in few-shot conversational dense retrieval. All source code and generated datasets are available at https://github.com/MiuLab/CONVERSER