 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolar-VLM: Multimodal Vision-Language Models for Augmented Solar Power Forecasting
Apr 05, 2026Photovoltaic (PV) power forecasting plays a critical role in power system dispatch and market participation. Because PV generation is highly sensitive to weather conditions and cloud motion, accurate forecasting requires effective modeling of complex spatiotemporal dependencies across multiple information sources. Although recent studies have advanced AI-based forecasting methods, most fail to fuse temporal observations, satellite imagery, and textual weather information in a unified framework. This paper proposes Solar-VLM, a large-language-model-driven framework for multimodal PV power forecasting. First, modality-specific encoders are developed to extract complementary features from heterogeneous inputs. The time-series encoder adopts a patch-based design to capture temporal patterns from multivariate observations at each site. The visual encoder, built upon a Qwen-based vision backbone, extracts cloud-cover information from satellite images. The text encoder distills historical weather characteristics from textual descriptions. Second, to capture spatial dependencies across geographically distributed PV stations, a cross-site feature fusion mechanism is introduced. Specifically, a Graph Learner models inter-station correlations through a graph attention network constructed over a K-nearest-neighbor (KNN) graph, while a cross-site attention module further facilitates adaptive information exchange among sites. Finally, experiments conducted on data from eight PV stations in a northern province of China demonstrate the effectiveness of the proposed framework. Our proposed model is publicly available at https://github.com/rhp413/Solar-VLM.
Overview of the Ninth Dialog System Technology Challenge: DSTC9
Nov 12, 2020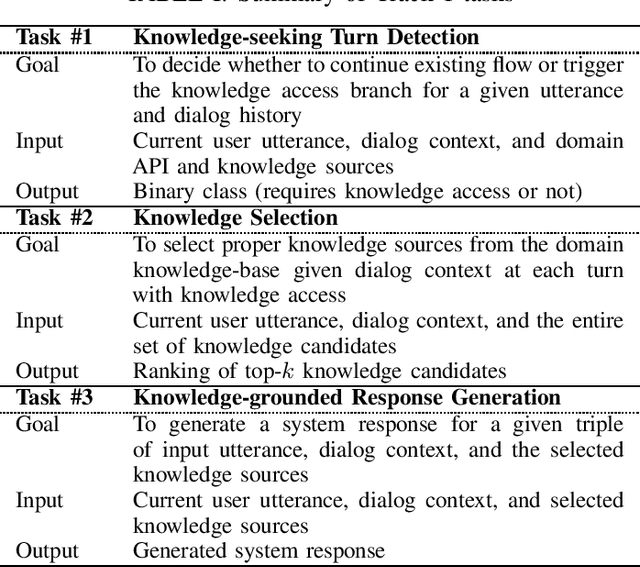
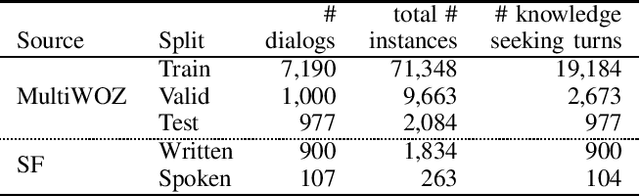

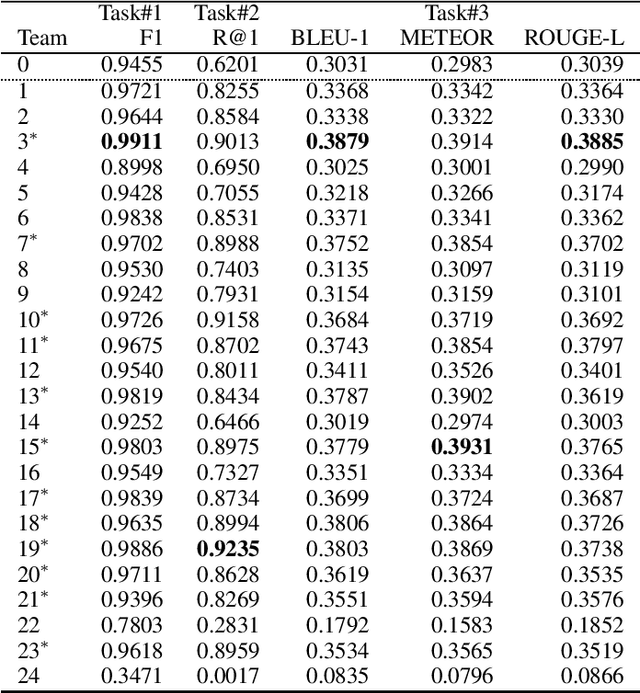
This paper introduces the Ninth Dialog System Technology Challenge (DSTC-9). This edition of the DSTC focuses on applying end-to-end dialog technologies for four distinct tasks in dialog systems, namely, 1. Task-oriented dialog Modeling with unstructured knowledge access, 2. Multi-domain task-oriented dialog, 3. Interactive evaluation of dialog, and 4. Situated interactive multi-modal dialog. This paper describes the task definition, provided datasets, baselines and evaluation set-up for each track. We also summarize the results of the submitted systems to highlight the overall trends of the state-of-the-art technologies for the tasks.
Multi-Agent Task-Oriented Dialog Policy Learning with Role-Aware Reward Decomposition
Apr 23, 2020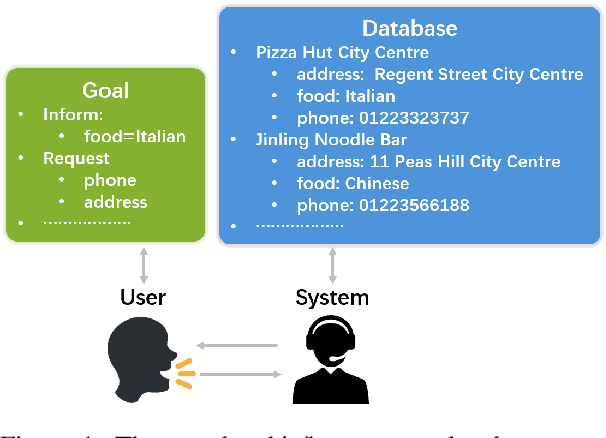
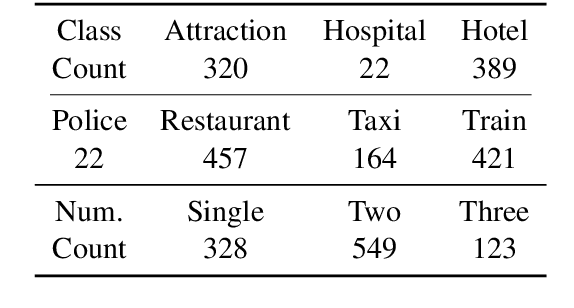
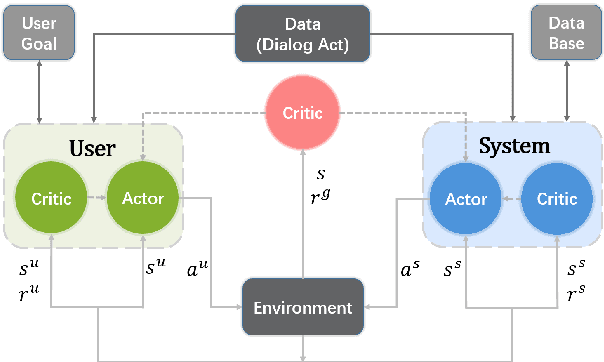
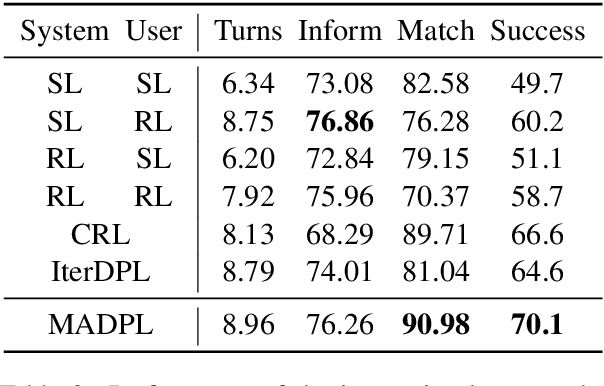
Many studies have applied reinforcement learning to train a dialog policy and show great promise these years. One common approach is to employ a user simulator to obtain a large number of simulated user experiences for reinforcement learning algorithms. However, modeling a realistic user simulator is challenging. A rule-based simulator requires heavy domain expertise for complex tasks, and a data-driven simulator requires considerable data and it is even unclear how to evaluate a simulator. To avoid explicitly building a user simulator beforehand, we propose Multi-Agent Dialog Policy Learning, which regards both the system and the user as the dialog agents. Two agents interact with each other and are jointly learned simultaneously. The method uses the actor-critic framework to facilitate pretraining and improve scalability. We also propose Hybrid Value Network for the role-aware reward decomposition to integrate role-specific domain knowledge of each agent in the task-oriented dialog. Results show that our method can successfully build a system policy and a user policy simultaneously, and two agents can achieve a high task success rate through conversational interaction.