 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuvion VL: A Multimodal Foundation Model for Adversarial Content and AI Safety
Jun 23, 2026General-purpose models often struggle to reliably identify and understand real-world multimodal risks, largely due to the inherent multimodal adversarial nature of content and AI safety. We present Yuvion VL, a family of multimodal large language models purpose-built for content and AI safety, with both instruction-tuned and reasoning-oriented variants. Yuvion VL addresses this gap by treating safety as an inherently adversarial and multimodal problem and designing the entire pipeline around adversarial robustness. For data construction, we develop an automated pipeline integrating adversarial-aware data synthesis with multi-stage quality control, producing large-scale, high-quality multimodal samples augmented with domain knowledge and reasoning annotations. For training, we adopt a three-stage pipeline that includes continued pretraining for risk-concept cross-modal alignment, instruct post-training for production-grade safety tasks, and reasoning post-training for enhanced interpretability and performance in complex tasks. We further introduce Confuse-then-Contrast Fine-Tuning, a contrastive framework that mines model-specific confusions and constructs multi-image contrastive groups to enforce explicit discrimination of fine-grained visual-semantic elements, enabling the model to distinguish between visually similar cases with different safety implications in adversarial safety tasks. To support rigorous evaluation, we further introduce Yuvion VL RiskEval (YVRE), a collection of benchmarks covering diverse open and internal evaluations, with a focus on content and AI safety, adversarial robustness, and real-world capability requirements. Experiments show that Yuvion VL-32B achieves industry-leading safety performance, surpassing comparably sized open-source models and best closed-source commercial models, while maintaining comparable general capabilities.
Exact Dual Geometry of SOC-ICNN Value Functions
May 06, 2026Input Convex Neural Networks (ICNNs) are commonly used in a two-stage manner: one first trains a convex network and then minimizes it over its input in a downstream inference problem. Recent second-order-cone ICNNs (SOC-ICNNs) enrich ReLU-based ICNNs with quadratic and conic modules and admit an exact representation as value functions of second-order cone programs (SOCPs). This value-function structure enables an explicit convex-analytic treatment of SOC-ICNN inference. In this paper, we study the exact first-order and local second-order geometry of SOC-ICNNs from the dual viewpoint. We show that supporting slopes, subdifferentials, directional derivatives, and local Hessians can be recovered directly from optimal dual variables. These results provide the geometric primitives for white-box SOC-ICNN inference, going beyond black-box automatic differentiation. Numerical experiments validate the exact multiplier readout, the local Hessian formula, and the set-valued behavior at structurally degenerate inputs. We also provide a step-by-step tutorial showing how the readout mechanism instantiates a complete white-box inference loop. The code is available at https://anonymous.4open.science/r/SOC-ICNN-Theory-BEFC/.
Budget-aware Auto Optimizer Configurator
May 06, 2026Optimizer states occupy massive GPU memory in large-scale model training. However, gradients in different network blocks exhibit distinct behaviors, such as varying directional stability and scale anisotropy, implying that expensive optimizer states are not universally necessary and using a global optimizer is often memory-inefficient. We propose the Budget-Aware Optimizer Configurator (BAOC) to reduce memory cost by assigning suitable optimizer configurations to individual blocks under given budgets. Specifically, BAOC samples gradient streams to derive statistical metrics that quantify the potential performance risk of applying cheaper configurations (e.g., low precision or removing momentum). It then solves a constrained allocation problem to minimize total risk under memory and time budgets, selecting a budget-feasible configuration for each block. Experiments across vision, language, and diffusion workloads demonstrate that BAOC maintains training quality while significantly reducing the memory usage of optimizer states. The code is available at https://anonymous.4open.science/r/BAOC-45C6.
JailWAM: Jailbreaking World Action Models in Robot Control
Apr 07, 2026The World Action Model (WAM) can jointly predict future world states and actions, exhibiting stronger physical manipulation capabilities compared with traditional models. Such powerful physical interaction ability is a double-edged sword: if safety is ignored, it will directly threaten personal safety, property security and environmental safety. However, existing research pays extremely limited attention to the critical security gap: the vulnerability of WAM to jailbreak attacks. To fill this gap, we define the Three-Level Safety Classification Framework to systematically quantify the safety of robotic arm motions. Furthermore, we propose JailWAM, the first dedicated jailbreak attack and evaluation framework for WAM, which consists of three core components: (1) Visual-Trajectory Mapping, which unifies heterogeneous action spaces into visual trajectory representations and enables cross-architectural unified evaluation; (2) Risk Discriminator, which serves as a high-recall screening tool that optimizes the efficiency-accuracy trade-off when identifying destructive behaviors in visual trajectories; (3) Dual-Path Verification Strategy, which first conducts rapid coarse screening via a single-image-based video-action generation module, and then performs efficient and comprehensive verification through full closed-loop physical simulation. In addition, we construct JailWAM-Bench, a benchmark for comprehensively evaluating the safety alignment performance of WAM under jailbreak attacks. Experiments in RoboTwin simulation environment demonstrate that the proposed framework efficiently exposes physical vulnerabilities, achieving an 84.2% attack success rate on the state-of-the-art LingBot-VA. Meanwhile, robust defense mechanisms can be constructed based on JailWAM, providing an effective technical solution for designing safe and reliable robot control systems.
Phase-Interface Instance Segmentation as a Visual Sensor for Laboratory Process Monitoring
Mar 11, 2026Reliable visual monitoring of chemical experiments remains challenging in transparent glassware, where weak phase boundaries and optical artifacts degrade conventional segmentation. We formulate laboratory phenomena as the time evolution of phase interfaces and introduce the Chemical Transparent Glasses dataset 2.0 (CTG 2.0), a vessel-aware benchmark with 3,668 images, 23 glassware categories, and five multiphase interface types for phase-interface instance segmentation. Building on YOLO11m-seg, we propose LGA-RCM-YOLO, which combines Local-Global Attention (LGA) for robust semantic representation and a Rectangular Self-Calibration Module (RCM) for boundary refinement of thin, elongated interfaces. On CTG 2.0, the proposed model achieves 84.4% AP@0.5 and 58.43% AP@0.5-0.95, improving over the YOLO11m baseline by 6.42 and 8.75 AP points, respectively, while maintaining near real-time inference (13.67 FPS, RTX 3060). An auxiliary color-attribute head further labels liquid instances as colored or colorless with 98.71% precision and 98.32% recall. Finally, we demonstrate continuous process monitoring in separatory-funnel phase separation and crystallization, showing that phase-interface instance segmentation can serve as a practical visual sensor for laboratory automation.
HOCA-Bench: Beyond Semantic Perception to Predictive World Modeling via Hegelian Ontological-Causal Anomalies
Feb 23, 2026Video-LLMs have improved steadily on semantic perception, but they still fall short on predictive world modeling, which is central to physically grounded intelligence. We introduce HOCA-Bench, a benchmark that frames physical anomalies through a Hegelian lens. HOCA-Bench separates anomalies into two types: ontological anomalies, where an entity violates its own definition or persistence, and causal anomalies, where interactions violate physical relations. Using state-of-the-art generative video models as adversarial simulators, we build a testbed of 1,439 videos (3,470 QA pairs). Evaluations on 17 Video-LLMs show a clear cognitive lag: models often identify static ontological violations (e.g., shape mutations) but struggle with causal mechanisms (e.g., gravity or friction), with performance dropping by more than 20% on causal tasks. System-2 "Thinking" modes improve reasoning, but they do not close the gap, suggesting that current architectures recognize visual patterns more readily than they apply basic physical laws.
OPBO: Order-Preserving Bayesian Optimization
Dec 22, 2025Bayesian optimization is an effective method for solving expensive black-box optimization problems. Most existing methods use Gaussian processes (GP) as the surrogate model for approximating the black-box objective function, it is well-known that it can fail in high-dimensional space (e.g., dimension over 500). We argue that the reliance of GP on precise numerical fitting is fundamentally ill-suited in high-dimensional space, where it leads to prohibitive computational complexity. In order to address this, we propose a simple order-preserving Bayesian optimization (OPBO) method, where the surrogate model preserves the order, instead of the value, of the black-box objective function. Then we can use a simple but effective OP neural network (NN) to replace GP as the surrogate model. Moreover, instead of searching for the best solution from the acquisition model, we select good-enough solutions in the ordinal set to reduce computational cost. The experimental results show that for high-dimensional (over 500) black-box optimization problems, the proposed OPBO significantly outperforms traditional BO methods based on regression NN and GP. The source code is available at https://github.com/pengwei222/OPBO.
Learning Hierarchical Procedural Memory for LLM Agents through Bayesian Selection and Contrastive Refinement
Dec 22, 2025We present MACLA, a framework that decouples reasoning from learning by maintaining a frozen large language model while performing all adaptation in an external hierarchical procedural memory. MACLA extracts reusable procedures from trajectories, tracks reliability via Bayesian posteriors, selects actions through expected-utility scoring, and refines procedures by contrasting successes and failures. Across four benchmarks (ALFWorld, WebShop, TravelPlanner, InterCodeSQL), MACLA achieves 78.1 percent average performance, outperforming all baselines. On ALFWorld unseen tasks, MACLA reaches 90.3 percent with 3.1 percent positive generalization. The system constructs memory in 56 seconds, 2800 times faster than the state-of-the-art LLM parameter-training baseline, compressing 2851 trajectories into 187 procedures. Experimental results demonstrate that structured external memory with Bayesian selection and contrastive refinement enables sample-efficient, interpretable, and continually improving agents without LLM parameter updates.
Are Vision Language Models Cross-Cultural Theory of Mind Reasoners?
Dec 19, 2025



Theory of Mind (ToM) -- the ability to attribute beliefs, desires, and emotions to others -- is fundamental for human social intelligence, yet remains a major challenge for artificial agents. Existing Vision-Language Models (VLMs) are increasingly applied in socially grounded tasks, but their capacity for cross-cultural ToM reasoning is largely unexplored. In this work, we introduce CulturalToM-VQA, a new evaluation benchmark containing 5095 questions designed to probe ToM reasoning across diverse cultural contexts through visual question answering. The dataset captures culturally grounded cues such as rituals, attire, gestures, and interpersonal dynamics, enabling systematic evaluation of ToM reasoning beyond Western-centric benchmarks. Our dataset is built through a VLM-assisted human-in-the-loop pipeline, where human experts first curate culturally rich images across traditions, rituals, and social interactions; a VLM then assist in generating structured ToM-focused scene descriptions, which are refined into question-answer pairs spanning a taxonomy of six ToM tasks and four graded complexity levels. The resulting dataset covers diverse theory of mind facets such as mental state attribution, false belief reasoning, non-literal communication, social norm violations, perspective coordination, and multi-agent reasoning.
TAO-Net: Two-stage Adaptive OOD Classification Network for Fine-grained Encrypted Traffic Classification
Dec 11, 2025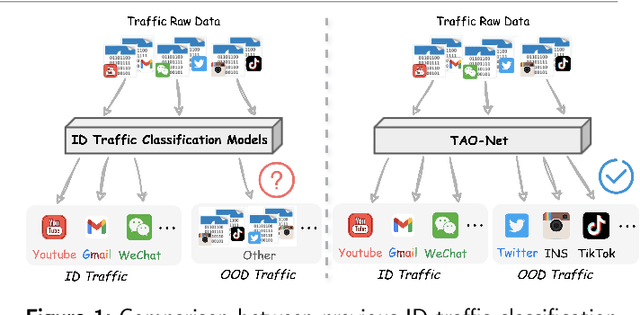

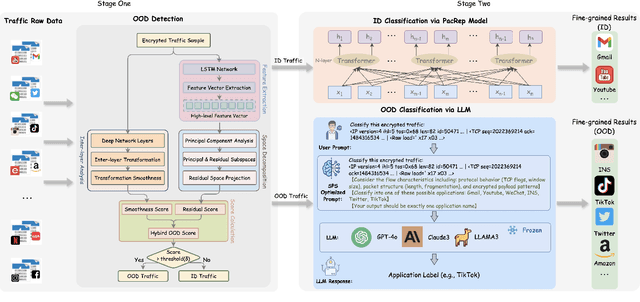
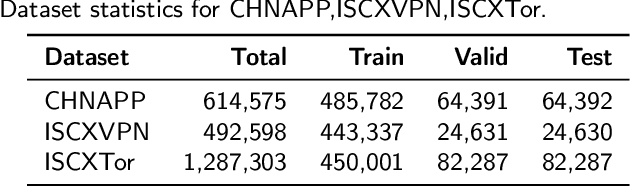
Encrypted traffic classification aims to identify applications or services by analyzing network traffic data. One of the critical challenges is the continuous emergence of new applications, which generates Out-of-Distribution (OOD) traffic patterns that deviate from known categories and are not well represented by predefined models. Current approaches rely on predefined categories, which limits their effectiveness in handling unknown traffic types. Although some methods mitigate this limitation by simply classifying unknown traffic into a single "Other" category, they fail to make a fine-grained classification. In this paper, we propose a Two-stage Adaptive OOD classification Network (TAO-Net) that achieves accurate classification for both In-Distribution (ID) and OOD encrypted traffic. The method incorporates an innovative two-stage design: the first stage employs a hybrid OOD detection mechanism that integrates transformer-based inter-layer transformation smoothness and feature analysis to effectively distinguish between ID and OOD traffic, while the second stage leverages large language models with a novel semantic-enhanced prompt strategy to transform OOD traffic classification into a generation task, enabling flexible fine-grained classification without relying on predefined labels. Experiments on three datasets demonstrate that TAO-Net achieves 96.81-97.70% macro-precision and 96.77-97.68% macro-F1, outperforming previous methods that only reach 44.73-86.30% macro-precision, particularly in identifying emerging network applications.