 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQChunker: Learning Question-Aware Text Chunking for Domain RAG via Multi-Agent Debate
Mar 12, 2026The effectiveness upper bound of retrieval-augmented generation (RAG) is fundamentally constrained by the semantic integrity and information granularity of text chunks in its knowledge base. To address these challenges, this paper proposes QChunker, which restructures the RAG paradigm from retrieval-augmentation to understanding-retrieval-augmentation. Firstly, QChunker models the text chunking as a composite task of text segmentation and knowledge completion to ensure the logical coherence and integrity of text chunks. Drawing inspiration from Hal Gregersen's "Questions Are the Answer" theory, we design a multi-agent debate framework comprising four specialized components: a question outline generator, text segmenter, integrity reviewer, and knowledge completer. This framework operates on the principle that questions serve as catalysts for profound insights. Through this pipeline, we successfully construct a high-quality dataset of 45K entries and transfer this capability to small language models. Additionally, to handle long evaluation chains and low efficiency in existing chunking evaluation methods, which overly rely on downstream QA tasks, we introduce a novel direct evaluation metric, ChunkScore. Both theoretical and experimental validations demonstrate that ChunkScore can directly and efficiently discriminate the quality of text chunks. Furthermore, during the text segmentation phase, we utilize document outlines for multi-path sampling to generate multiple candidate chunks and select the optimal solution employing ChunkScore. Extensive experimental results across four heterogeneous domains exhibit that QChunker effectively resolves aforementioned issues by providing RAG with more logically coherent and information-rich text chunks.
A Learning-based Approach Towards Automated Tuning of SSD Configurations
Oct 17, 2021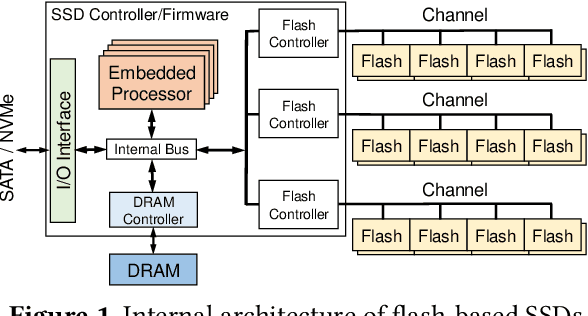

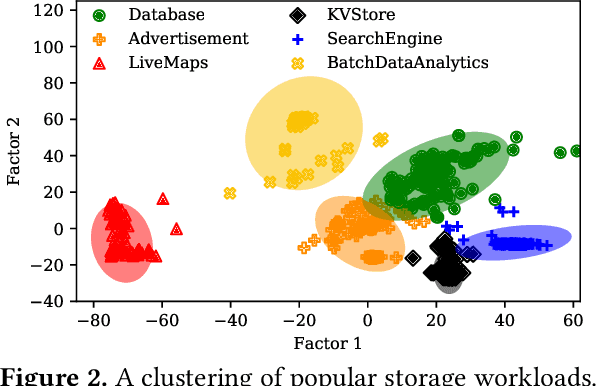
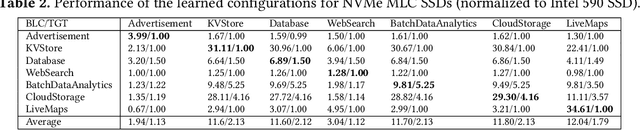
Thanks to the mature manufacturing techniques, solid-state drives (SSDs) are highly customizable for applications today, which brings opportunities to further improve their storage performance and resource utilization. However, the SSD efficiency is usually determined by many hardware parameters, making it hard for developers to manually tune them and determine the optimal SSD configurations. In this paper, we present an automated learning-based framework, named LearnedSSD, that utilizes both supervised and unsupervised machine learning (ML) techniques to drive the tuning of hardware configurations for SSDs. LearnedSSD automatically extracts the unique access patterns of a new workload using its block I/O traces, maps the workload to previously workloads for utilizing the learned experiences, and recommends an optimal SSD configuration based on the validated storage performance. LearnedSSD accelerates the development of new SSD devices by automating the hard-ware parameter configurations and reducing the manual efforts. We develop LearnedSSD with simple yet effective learning algorithms that can run efficiently on multi-core CPUs. Given a target storage workload, our evaluation shows that LearnedSSD can always deliver an optimal SSD configuration for the target workload, and this configuration will not hurt the performance of non-target workloads.
CPM: A Large-scale Generative Chinese Pre-trained Language Model
Dec 01, 2020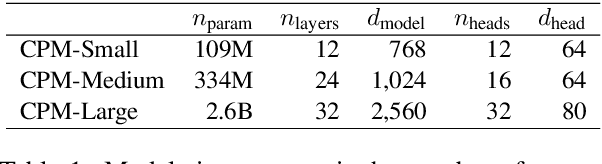

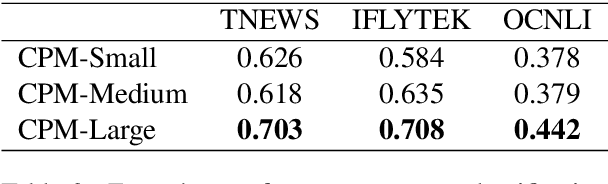
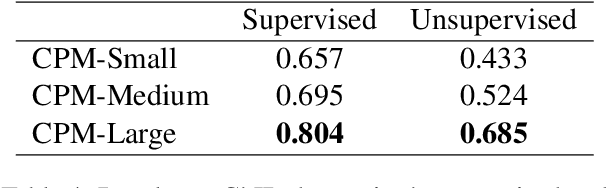
Pre-trained Language Models (PLMs) have proven to be beneficial for various downstream NLP tasks. Recently, GPT-3, with 175 billion parameters and 570GB training data, drew a lot of attention due to the capacity of few-shot (even zero-shot) learning. However, applying GPT-3 to address Chinese NLP tasks is still challenging, as the training corpus of GPT-3 is primarily English, and the parameters are not publicly available. In this technical report, we release the Chinese Pre-trained Language Model (CPM) with generative pre-training on large-scale Chinese training data. To the best of our knowledge, CPM, with 2.6 billion parameters and 100GB Chinese training data, is the largest Chinese pre-trained language model, which could facilitate several downstream Chinese NLP tasks, such as conversation, essay generation, cloze test, and language understanding. Extensive experiments demonstrate that CPM achieves strong performance on many NLP tasks in the settings of few-shot (even zero-shot) learning. The code and parameters are available at https://github.com/TsinghuaAI/CPM-Generate.