 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATANet: Efficient Content-Aware Token Aggregation for Lightweight Image Super-Resolution
Mar 10, 2025Transformer-based methods have demonstrated impressive performance in low-level visual tasks such as Image Super-Resolution (SR). However, its computational complexity grows quadratically with the spatial resolution. A series of works attempt to alleviate this problem by dividing Low-Resolution images into local windows, axial stripes, or dilated windows. SR typically leverages the redundancy of images for reconstruction, and this redundancy appears not only in local regions but also in long-range regions. However, these methods limit attention computation to content-agnostic local regions, limiting directly the ability of attention to capture long-range dependency. To address these issues, we propose a lightweight Content-Aware Token Aggregation Network (CATANet). Specifically, we propose an efficient Content-Aware Token Aggregation module for aggregating long-range content-similar tokens, which shares token centers across all image tokens and updates them only during the training phase. Then we utilize intra-group self-attention to enable long-range information interaction. Moreover, we design an inter-group cross-attention to further enhance global information interaction. The experimental results show that, compared with the state-of-the-art cluster-based method SPIN, our method achieves superior performance, with a maximum PSNR improvement of 0.33dB and nearly double the inference speed.
Q-PART: Quasi-Periodic Adaptive Regression with Test-time Training for Pediatric Left Ventricular Ejection Fraction Regression
Mar 06, 2025



In this work, we address the challenge of adaptive pediatric Left Ventricular Ejection Fraction (LVEF) assessment. While Test-time Training (TTT) approaches show promise for this task, they suffer from two significant limitations. Existing TTT works are primarily designed for classification tasks rather than continuous value regression, and they lack mechanisms to handle the quasi-periodic nature of cardiac signals. To tackle these issues, we propose a novel \textbf{Q}uasi-\textbf{P}eriodic \textbf{A}daptive \textbf{R}egression with \textbf{T}est-time Training (Q-PART) framework. In the training stage, the proposed Quasi-Period Network decomposes the echocardiogram into periodic and aperiodic components within latent space by combining parameterized helix trajectories with Neural Controlled Differential Equations. During inference, our framework further employs a variance minimization strategy across image augmentations that simulate common quality issues in echocardiogram acquisition, along with differential adaptation rates for periodic and aperiodic components. Theoretical analysis is provided to demonstrate that our variance minimization objective effectively bounds the regression error under mild conditions. Furthermore, extensive experiments across three pediatric age groups demonstrate that Q-PART not only significantly outperforms existing approaches in pediatric LVEF prediction, but also exhibits strong clinical screening capability with high mAUROC scores (up to 0.9747) and maintains gender-fair performance across all metrics, validating its robustness and practical utility in pediatric echocardiography analysis.
E4: Energy-Efficient DNN Inference for Edge Video Analytics Via Early-Exit and DVFS
Mar 06, 2025



Deep neural network (DNN) models are increasingly popular in edge video analytic applications. However, the compute-intensive nature of DNN models pose challenges for energy-efficient inference on resource-constrained edge devices. Most existing solutions focus on optimizing DNN inference latency and accuracy, often overlooking energy efficiency. They also fail to account for the varying complexity of video frames, leading to sub-optimal performance in edge video analytics. In this paper, we propose an Energy-Efficient Early-Exit (E4) framework that enhances DNN inference efficiency for edge video analytics by integrating a novel early-exit mechanism with dynamic voltage and frequency scaling (DVFS) governors. It employs an attention-based cascade module to analyze video frame diversity and automatically determine optimal DNN exit points. Additionally, E4 features a just-in-time (JIT) profiler that uses coordinate descent search to co-optimize CPU and GPU clock frequencies for each layer before the DNN exit points. Extensive evaluations demonstrate that E4 outperforms current state-of-the-art methods, achieving up to 2.8x speedup and 26% average energy saving while maintaining high accuracy.
AutoLUT: LUT-Based Image Super-Resolution with Automatic Sampling and Adaptive Residual Learning
Mar 03, 2025In recent years, the increasing popularity of Hi-DPI screens has driven a rising demand for high-resolution images. However, the limited computational power of edge devices poses a challenge in deploying complex super-resolution neural networks, highlighting the need for efficient methods. While prior works have made significant progress, they have not fully exploited pixel-level information. Moreover, their reliance on fixed sampling patterns limits both accuracy and the ability to capture fine details in low-resolution images. To address these challenges, we introduce two plug-and-play modules designed to capture and leverage pixel information effectively in Look-Up Table (LUT) based super-resolution networks. Our method introduces Automatic Sampling (AutoSample), a flexible LUT sampling approach where sampling weights are automatically learned during training to adapt to pixel variations and expand the receptive field without added inference cost. We also incorporate Adaptive Residual Learning (AdaRL) to enhance inter-layer connections, enabling detailed information flow and improving the network's ability to reconstruct fine details. Our method achieves significant performance improvements on both MuLUT and SPF-LUT while maintaining similar storage sizes. Specifically, for MuLUT, we achieve a PSNR improvement of approximately +0.20 dB improvement on average across five datasets. For SPF-LUT, with more than a 50% reduction in storage space and about a 2/3 reduction in inference time, our method still maintains performance comparable to the original. The code is available at https://github.com/SuperKenVery/AutoLUT.
The Rise of Darkness: Safety-Utility Trade-Offs in Role-Playing Dialogue Agents
Feb 28, 2025Large Language Models (LLMs) have made remarkable advances in role-playing dialogue agents, demonstrating their utility in character simulations. However, it remains challenging for these agents to balance character portrayal utility with content safety because this essential character simulation often comes with the risk of generating unsafe content. To address this issue, we first conduct a systematic exploration of the safety-utility trade-off across multiple LLMs. Our analysis reveals that risk scenarios created by villain characters and user queries (referred to as risk coupling) contribute to this trade-off. Building on this, we propose a novel Adaptive Dynamic Multi-Preference (ADMP) method, which dynamically adjusts safety-utility preferences based on the degree of risk coupling and guides the model to generate responses biased toward utility or safety. We further introduce Coupling Margin Sampling (CMS) into coupling detection to enhance the model's ability to handle high-risk scenarios. Experimental results demonstrate that our approach improves safety metrics while maintaining utility.
Task-KV: Task-aware KV Cache Optimization via Semantic Differentiation of Attention Heads
Jan 25, 2025KV cache is a widely used acceleration technique for large language models (LLMs) inference. However, its memory requirement grows rapidly with input length. Previous studies have reduced the size of KV cache by either removing the same number of unimportant tokens for all attention heads or by allocating differentiated KV cache budgets for pre-identified attention heads. However, due to the importance of attention heads varies across different tasks, the pre-identified attention heads fail to adapt effectively to various downstream tasks. To address this issue, we propose Task-KV, a method that leverages the semantic differentiation of attention heads to allocate differentiated KV cache budgets across various tasks. We demonstrate that attention heads far from the semantic center (called heterogeneous heads) make an significant contribution to task outputs and semantic understanding. In contrast, other attention heads play the role of aggregating important information and focusing reasoning. Task-KV allocates full KV cache budget to heterogeneous heads to preserve comprehensive semantic information, while reserving a small number of recent tokens and attention sinks for non-heterogeneous heads. Furthermore, we innovatively introduce middle activations to preserve key contextual information aggregated from non-heterogeneous heads. To dynamically perceive semantic differences among attention heads, we design a semantic separator to distinguish heterogeneous heads from non-heterogeneous ones based on their distances from the semantic center. Experimental results on multiple benchmarks and different model architectures demonstrate that Task-KV significantly outperforms existing baseline methods.
"Stones from Other Hills can Polish Jade": Zero-shot Anomaly Image Synthesis via Cross-domain Anomaly Injection
Jan 25, 2025



Industrial image anomaly detection (IAD) is a pivotal topic with huge value. Due to anomaly's nature, real anomalies in a specific modern industrial domain (i.e. domain-specific anomalies) are usually too rare to collect, which severely hinders IAD. Thus, zero-shot anomaly synthesis (ZSAS), which synthesizes pseudo anomaly images without any domain-specific anomaly, emerges as a vital technique for IAD. However, existing solutions are either unable to synthesize authentic pseudo anomalies, or require cumbersome training. Thus, we focus on ZSAS and propose a brand-new paradigm that can realize both authentic and training-free ZSAS. It is based on a chronically-ignored fact: Although domain-specific anomalies are rare, real anomalies from other domains (i.e. cross-domain anomalies) are actually abundant and directly applicable to ZSAS. Specifically, our new ZSAS paradigm makes three-fold contributions: First, we propose a novel method named Cross-domain Anomaly Injection (CAI), which directly exploits cross-domain anomalies to enable highly authentic ZSAS in a training-free manner. Second, to supply CAI with sufficient cross-domain anomalies, we build the first domain-agnostic anomaly dataset within our best knowledge, which provides ZSAS with abundant real anomaly patterns. Third, we propose a CAI-guided Diffusion Mechanism, which further breaks the quantity limit of real anomalies and enable unlimited anomaly synthesis. Our head-to-head comparison with existing ZSAS solutions justifies our paradigm's superior performance for IAD and demonstrates it as an effective and pragmatic ZSAS solution.
Improving Video Generation with Human Feedback
Jan 23, 2025



Video generation has achieved significant advances through rectified flow techniques, but issues like unsmooth motion and misalignment between videos and prompts persist. In this work, we develop a systematic pipeline that harnesses human feedback to mitigate these problems and refine the video generation model. Specifically, we begin by constructing a large-scale human preference dataset focused on modern video generation models, incorporating pairwise annotations across multi-dimensions. We then introduce VideoReward, a multi-dimensional video reward model, and examine how annotations and various design choices impact its rewarding efficacy. From a unified reinforcement learning perspective aimed at maximizing reward with KL regularization, we introduce three alignment algorithms for flow-based models by extending those from diffusion models. These include two training-time strategies: direct preference optimization for flow (Flow-DPO) and reward weighted regression for flow (Flow-RWR), and an inference-time technique, Flow-NRG, which applies reward guidance directly to noisy videos. Experimental results indicate that VideoReward significantly outperforms existing reward models, and Flow-DPO demonstrates superior performance compared to both Flow-RWR and standard supervised fine-tuning methods. Additionally, Flow-NRG lets users assign custom weights to multiple objectives during inference, meeting personalized video quality needs. Project page: https://gongyeliu.github.io/videoalign.
MeshONet: A Generalizable and Efficient Operator Learning Method for Structured Mesh Generation
Jan 21, 2025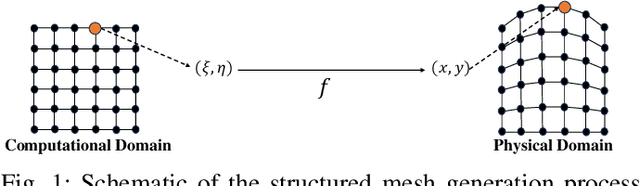
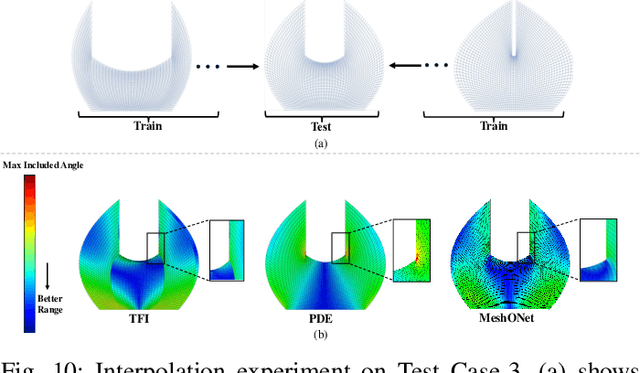

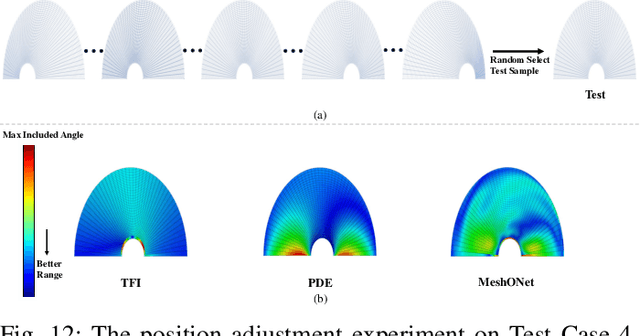
Mesh generation plays a crucial role in scientific computing. Traditional mesh generation methods, such as TFI and PDE-based methods, often struggle to achieve a balance between efficiency and mesh quality. To address this challenge, physics-informed intelligent learning methods have recently emerged, significantly improving generation efficiency while maintaining high mesh quality. However, physics-informed methods fail to generalize when applied to previously unseen geometries, as even small changes in the boundary shape necessitate burdensome retraining to adapt to new geometric variations. In this paper, we introduce MeshONet, the first generalizable intelligent learning method for structured mesh generation. The method transforms the mesh generation task into an operator learning problem with multiple input and solution functions. To effectively overcome the multivariable mapping restriction of operator learning methods, we propose a dual-branch, shared-trunk architecture to approximate the mapping between function spaces based on input-output pairs. Experimental results show that MeshONet achieves a speedup of up to four orders of magnitude in generation efficiency over traditional methods. It also enables generalization to different geometries without retraining, greatly enhancing the practicality of intelligent methods.
DAMPER: A Dual-Stage Medical Report Generation Framework with Coarse-Grained MeSH Alignment and Fine-Grained Hypergraph Matching
Dec 19, 2024



Medical report generation is crucial for clinical diagnosis and patient management, summarizing diagnoses and recommendations based on medical imaging. However, existing work often overlook the clinical pipeline involved in report writing, where physicians typically conduct an initial quick review followed by a detailed examination. Moreover, current alignment methods may lead to misaligned relationships. To address these issues, we propose DAMPER, a dual-stage framework for medical report generation that mimics the clinical pipeline of report writing in two stages. In the first stage, a MeSH-Guided Coarse-Grained Alignment (MCG) stage that aligns chest X-ray (CXR) image features with medical subject headings (MeSH) features to generate a rough keyphrase representation of the overall impression. In the second stage, a Hypergraph-Enhanced Fine-Grained Alignment (HFG) stage that constructs hypergraphs for image patches and report annotations, modeling high-order relationships within each modality and performing hypergraph matching to capture semantic correlations between image regions and textual phrases. Finally,the coarse-grained visual features, generated MeSH representations, and visual hypergraph features are fed into a report decoder to produce the final medical report. Extensive experiments on public datasets demonstrate the effectiveness of DAMPER in generating comprehensive and accurate medical reports, outperforming state-of-the-art methods across various evaluation metrics.