 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling Security, Privacy, and Ethical Concerns of ChatGPT
Jul 26, 2023



This paper delves into the realm of ChatGPT, an AI-powered chatbot that utilizes topic modeling and reinforcement learning to generate natural responses. Although ChatGPT holds immense promise across various industries, such as customer service, education, mental health treatment, personal productivity, and content creation, it is essential to address its security, privacy, and ethical implications. By exploring the upgrade path from GPT-1 to GPT-4, discussing the model's features, limitations, and potential applications, this study aims to shed light on the potential risks of integrating ChatGPT into our daily lives. Focusing on security, privacy, and ethics issues, we highlight the challenges these concerns pose for widespread adoption. Finally, we analyze the open problems in these areas, calling for concerted efforts to ensure the development of secure and ethically sound large language models.
Robust One-shot Segmentation of Brain Tissues via Image-aligned Style Transformation
Nov 30, 2022



One-shot segmentation of brain tissues is typically a dual-model iterative learning: a registration model (reg-model) warps a carefully-labeled atlas onto unlabeled images to initialize their pseudo masks for training a segmentation model (seg-model); the seg-model revises the pseudo masks to enhance the reg-model for a better warping in the next iteration. However, there is a key weakness in such dual-model iteration that the spatial misalignment inevitably caused by the reg-model could misguide the seg-model, which makes it converge on an inferior segmentation performance eventually. In this paper, we propose a novel image-aligned style transformation to reinforce the dual-model iterative learning for robust one-shot segmentation of brain tissues. Specifically, we first utilize the reg-model to warp the atlas onto an unlabeled image, and then employ the Fourier-based amplitude exchange with perturbation to transplant the style of the unlabeled image into the aligned atlas. This allows the subsequent seg-model to learn on the aligned and style-transferred copies of the atlas instead of unlabeled images, which naturally guarantees the correct spatial correspondence of an image-mask training pair, without sacrificing the diversity of intensity patterns carried by the unlabeled images. Furthermore, we introduce a feature-aware content consistency in addition to the image-level similarity to constrain the reg-model for a promising initialization, which avoids the collapse of image-aligned style transformation in the first iteration. Experimental results on two public datasets demonstrate 1) a competitive segmentation performance of our method compared to the fully-supervised method, and 2) a superior performance over other state-of-the-art with an increase of average Dice by up to 4.67%. The source code is available at: https://github.com/JinxLv/One-shot-segmentation-via-IST.
Power Efficient Video Super-Resolution on Mobile NPUs with Deep Learning, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Video super-resolution is one of the most popular tasks on mobile devices, being widely used for an automatic improvement of low-bitrate and low-resolution video streams. While numerous solutions have been proposed for this problem, they are usually quite computationally demanding, demonstrating low FPS rates and power efficiency on mobile devices. In this Mobile AI challenge, we address this problem and propose the participants to design an end-to-end real-time video super-resolution solution for mobile NPUs optimized for low energy consumption. The participants were provided with the REDS training dataset containing video sequences for a 4X video upscaling task. The runtime and power efficiency of all models was evaluated on the powerful MediaTek Dimensity 9000 platform with a dedicated AI processing unit capable of accelerating floating-point and quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 500 FPS rate and 0.2 [Watt / 30 FPS] power consumption. A detailed description of all models developed in the challenge is provided in this paper.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
Boundary Effect-Aware Visual Tracking for UAV with Online Enhanced Background Learning and Multi-Frame Consensus Verification
Aug 10, 2019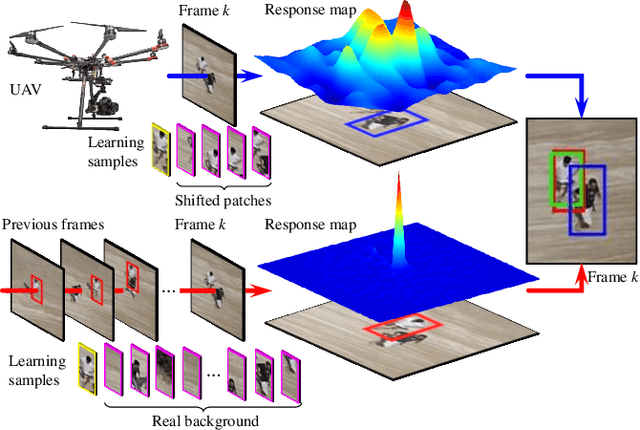
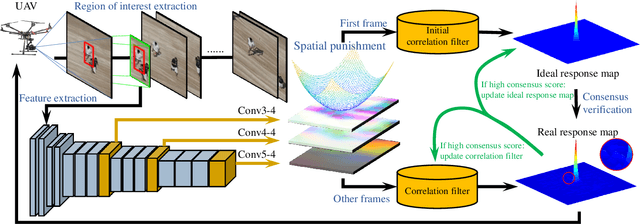
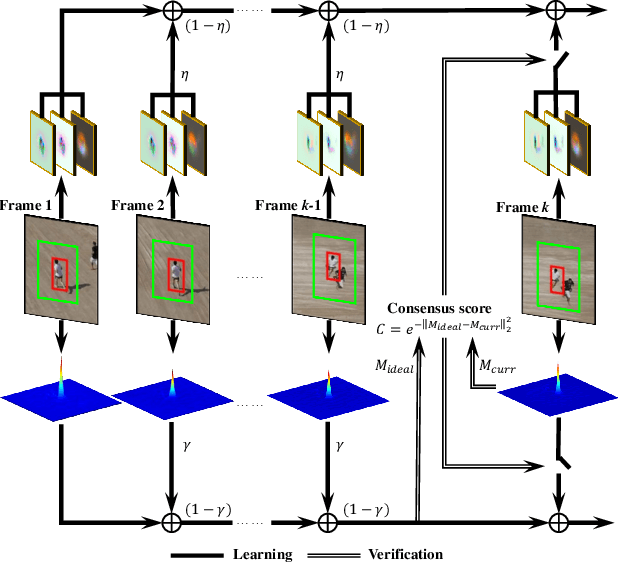
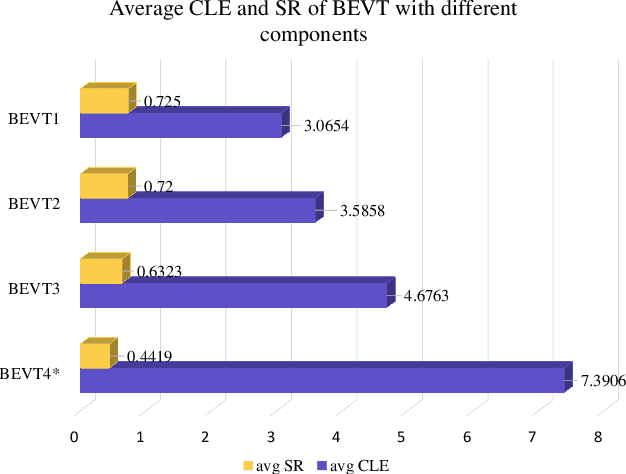
Due to implicitly introduced periodic shifting of limited searching area, visual object tracking using correlation filters often has to confront undesired boundary effect. As boundary effect severely degrade the quality of object model, it has made it a challenging task for unmanned aerial vehicles (UAV) to perform robust and accurate object following. Traditional hand-crafted features are also not precise and robust enough to describe the object in the viewing point of UAV. In this work, a novel tracker with online enhanced background learning is specifically proposed to tackle boundary effects. Real background samples are densely extracted to learn as well as update correlation filters. Spatial penalization is introduced to offset the noise introduced by exceedingly more background information so that a more accurate appearance model can be established. Meanwhile, convolutional features are extracted to provide a more comprehensive representation of the object. In order to mitigate changes of objects' appearances, multi-frame technique is applied to learn an ideal response map and verify the generated one in each frame. Exhaustive experiments were conducted on 100 challenging UAV image sequences and the proposed tracker has achieved state-of-the-art performance.