 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Mixture-of-Experts Models with Megatron Core
Mar 10, 2026Scaling Mixture-of-Experts (MoE) training introduces systems challenges absent in dense models. Because each token activates only a subset of experts, this sparsity allows total parameters to grow much faster than per-token computation, creating coupled constraints across memory, communication, and computation. Optimizing one dimension often shifts pressure to another, demanding co-design across the full system stack. We address these challenges for MoE training through integrated optimizations spanning memory (fine-grained recomputation, offloading, etc.), communication (optimized dispatchers, overlapping, etc.), and computation (Grouped GEMM, fusions, CUDA Graphs, etc.). The framework also provides Parallel Folding for flexible multi-dimensional parallelism, low-precision training support for FP8 and NVFP4, and efficient long-context training. On NVIDIA GB300 and GB200, it achieves 1,233/1,048 TFLOPS/GPU for DeepSeek-V3-685B and 974/919 TFLOPS/GPU for Qwen3-235B. As a performant, scalable, and production-ready open-source solution, it has been used across academia and industry for training MoE models ranging from billions to trillions of parameters on clusters scaling up to thousands of GPUs. This report explains how these techniques work, their trade-offs, and their interactions at the systems level, providing practical guidance for scaling MoE models with Megatron Core.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Matlab-based Epoch Extraction for Speaker Differentiation
Jul 26, 2024



Epoch extraction has become increasingly popular in recent years for speech analysis research because accurately detecting the location of the Epoch is crucial for analyzing speech signals. The Epoch, occurring at the instant of excitation in the vocal tract system, particularly during glottal closure, plays a significant role in differentiating speakers in multi-speaker conversations. However, the extraction of the Epoch poses a challenge due to the time-varying factors in the vocal tract system, which makes deconvolution for obtaining the original excitation location more complex. In this paper, various methods for Epoch extraction, including Zero Frequency Filtering (ZFF) and Zero Frequency Resonator (ZFR), will be discussed, and their pros and cons evaluated. In addition, the stability, accuracy, and feasibility of each method will be compared. The evaluation will involve a Matlab-based locking algorithm, and a proposed hardware implementation using Raspberry pi for speaker differentiation. The experiment includes six individuals uttering the phrase "The University of Mississippi," with one person acting as the reference or "lock" speaker. The number of epochs occurring at similar positions to the reference speaker will be counted as Delta, with larger Delta values indicating greater speaker similarity. Experimental results demonstrate that when the speaker remains the same, the average number of Delta is 7.5, while for different speakers, the average number of Delta decreases to 3, 2, 2, and 1, respectively, representing a decrease of approximately 73% in the number of epochs at similar positions compared to the reference speaker.
Localization in Reconfigurable Intelligent Surface Aided mmWave Systems: A Multiple Measurement Vector Based Channel Estimation Method
Feb 25, 2024



The sparsity of millimeter wave (mmWave) channels in the angular and temporal domains is beneficial to channel estimation, while the associated channel parameters can be utilized for localization. However, line-of-sight (LoS) blockage poses a significant challenge on the localization in mmWave systems, potentially leading to substantial positioning errors. A promising solution is to employ reconfigurable intelligent surface (RIS) to generate the virtual line-of-sight (VLoS) paths to aid localization. Consequently, wireless localization in the RIS-assisted mmWave systems has become the essential research issue. In this paper, a multiple measurement vector (MMV) model is constructed and a two-stage channel estimation based localization scheme is proposed. During the first stage, by exploiting the beamspace sparsity and employing a random RIS phase shift matrix, the channel parameters are estimated, based on which the precoder at base station and combiner at user equipment (UE) are designed. Then, in the second stage, based on the designed precoding and combining matrices, the optimal phase shift matrix for RIS is designed using the proposed modified temporally correlated multiple sparse Bayesian learning (TMSBL) algorithm. Afterwards, the channel parameters, such as angle of reflection, time-of-arrival, etc., embedding location information are estimated for finally deriving the location of UE. We demonstrate the achievable performance of the proposed algorithm and compare it with the state-of-the-art algorithms. Our studies show that the proposed localization scheme is capable of achieving centimeter level localization accuracy, when LoS path is blocked. Furthermore, the proposed algorithm has a low computational complexity and outperforms the legacy algorithms in different perspectives.
Merlin HugeCTR: GPU-accelerated Recommender System Training and Inference
Oct 17, 2022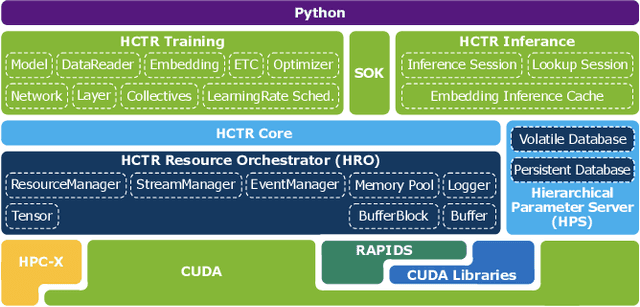
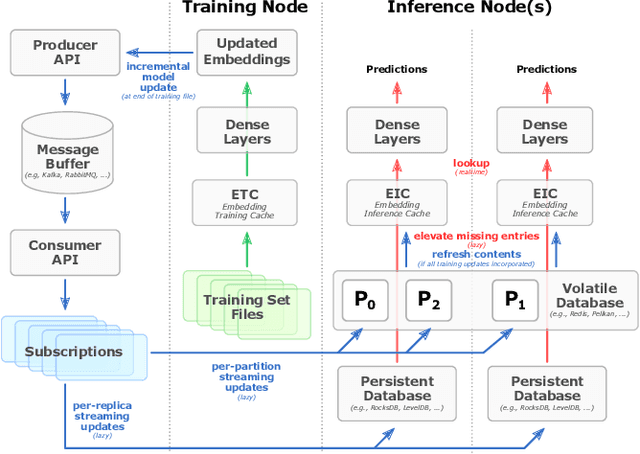
In this talk, we introduce Merlin HugeCTR. Merlin HugeCTR is an open source, GPU-accelerated integration framework for click-through rate estimation. It optimizes both training and inference, whilst enabling model training at scale with model-parallel embeddings and data-parallel neural networks. In particular, Merlin HugeCTR combines a high-performance GPU embedding cache with an hierarchical storage architecture, to realize low-latency retrieval of embeddings for online model inference tasks. In the MLPerf v1.0 DLRM model training benchmark, Merlin HugeCTR achieves a speedup of up to 24.6x on a single DGX A100 (8x A100) over PyTorch on 4x4-socket CPU nodes (4x4x28 cores). Merlin HugeCTR can also take advantage of multi-node environments to accelerate training even further. Since late 2021, Merlin HugeCTR additionally features a hierarchical parameter server (HPS) and supports deployment via the NVIDIA Triton server framework, to leverage the computational capabilities of GPUs for high-speed recommendation model inference. Using this HPS, Merlin HugeCTR users can achieve a 5~62x speedup (batch size dependent) for popular recommendation models over CPU baseline implementations, and dramatically reduce their end-to-end inference latency.
* 4 pages