 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Clip-Free Quantized Super-Resolution Networks: How to Tame Representative Images
Aug 22, 2023Super-resolution (SR) networks have been investigated for a while, with their mobile and lightweight versions gaining noticeable popularity recently. Quantization, the procedure of decreasing the precision of network parameters (mostly FP32 to INT8), is also utilized in SR networks for establishing mobile compatibility. This study focuses on a very important but mostly overlooked post-training quantization (PTQ) step: representative dataset (RD), which adjusts the quantization range for PTQ. We propose a novel pipeline (clip-free quantization pipeline, CFQP) backed up with extensive experimental justifications to cleverly augment RD images by only using outputs of the FP32 model. Using the proposed pipeline for RD, we can successfully eliminate unwanted clipped activation layers, which nearly all mobile SR methods utilize to make the model more robust to PTQ in return for a large overhead in runtime. Removing clipped activations with our method significantly benefits overall increased stability, decreased inference runtime up to 54% on some SR models, better visual quality results compared to INT8 clipped models - and outperforms even some FP32 non-quantized models, both in runtime and visual quality, without the need for retraining with clipped activation.
Bicubic++: Slim, Slimmer, Slimmest -- Designing an Industry-Grade Super-Resolution Network
May 03, 2023



We propose a real-time and lightweight single-image super-resolution (SR) network named Bicubic++. Despite using spatial dimensions of the input image across the whole network, Bicubic++ first learns quick reversible downgraded and lower resolution features of the image in order to decrease the number of computations. We also construct a training pipeline, where we apply an end-to-end global structured pruning of convolutional layers without using metrics like magnitude and gradient norms, and focus on optimizing the pruned network's PSNR on the validation set. Furthermore, we have experimentally shown that the bias terms take considerable amount of the runtime while increasing PSNR marginally, hence we have also applied bias removal to the convolutional layers. Our method adds ~1dB on Bicubic upscaling PSNR for all tested SR datasets and runs with ~1.17ms on RTX3090 and ~2.9ms on RTX3070, for 720p inputs and 4K outputs, both in FP16 precision. Bicubic++ won NTIRE 2023 RTSR Track 2 x3 SR competition and is the fastest among all competitive methods. Being almost as fast as the standard Bicubic upsampling method, we believe that Bicubic++ can set a new industry standard.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
XCAT -- Lightweight Quantized Single Image Super-Resolution using Heterogeneous Group Convolutions and Cross Concatenation
Aug 31, 2022
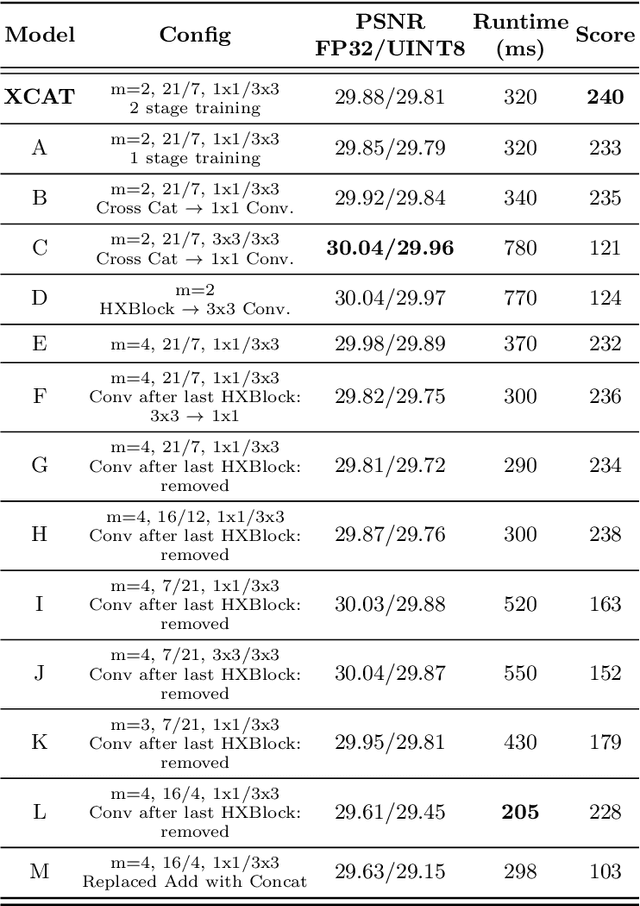
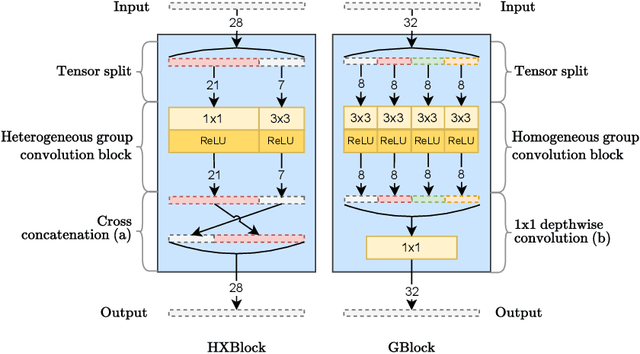
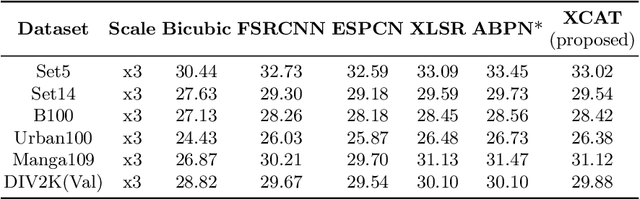
We propose a lightweight, single image super-resolution network for mobile devices, named XCAT. XCAT introduces Heterogeneous Group Convolution Blocks with Cross Concatenations (HXBlock). The heterogeneous split of the input channels to the group convolution blocks reduces the number of operations, and cross concatenation allows for information flow between the intermediate input tensors of cascaded HXBlocks. Cross concatenations inside HXBlocks can also avoid using more expensive operations like 1x1 convolutions. To further prev ent expensive tensor copy operations, XCAT utilizes non-trainable convolution kernels to apply up sampling operations. Designed with integer quantization in mind, XCAT also utilizes several techniques on training, like intensity-based data augmentation. Integer quantized XCAT operates in real time on Mali-G71 MP2 GPU with 320ms, and on Synaptics Dolphin NPU with 30ms (NCHW) and 8.8ms (NHWC), suitable for real-time applications.
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022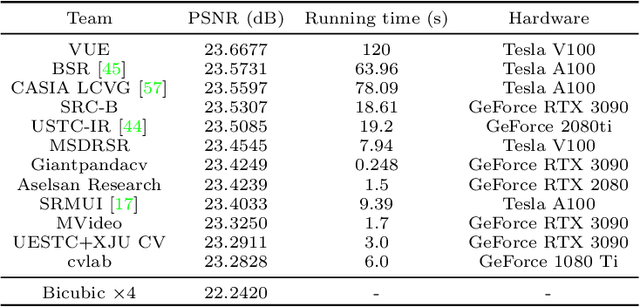
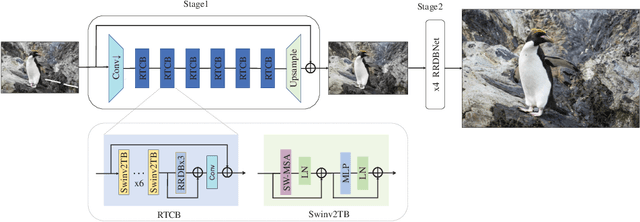

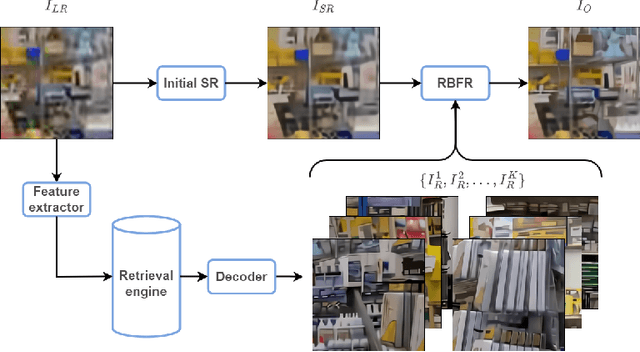
This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.
Efficient Multi-Purpose Cross-Attention Based Image Alignment Block for Edge Devices
Jun 01, 2022

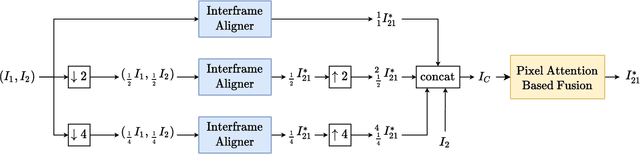
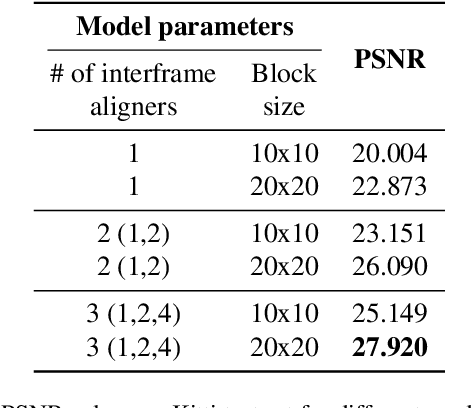
Image alignment, also known as image registration, is a critical block used in many computer vision problems. One of the key factors in alignment is efficiency, as inefficient aligners can cause significant overhead to the overall problem. In the literature, there are some blocks that appear to do the alignment operation, although most do not focus on efficiency. Therefore, an image alignment block which can both work in time and/or space and can work on edge devices would be beneficial for almost all networks dealing with multiple images. Given its wide usage and importance, we propose an efficient, cross-attention-based, multi-purpose image alignment block (XABA) suitable to work within edge devices. Using cross-attention, we exploit the relationships between features extracted from images. To make cross-attention feasible for real-time image alignment problems and handle large motions, we provide a pyramidal block based cross-attention scheme. This also captures local relationships besides reducing memory requirements and number of operations. Efficient XABA models achieve real-time requirements of running above 20 FPS performance on NVIDIA Jetson Xavier with 30W power consumption compared to other powerful computers. Used as a sub-block in a larger network, XABA also improves multi-image super-resolution network performance in comparison to other alignment methods.
IMDeception: Grouped Information Distilling Super-Resolution Network
Apr 25, 2022
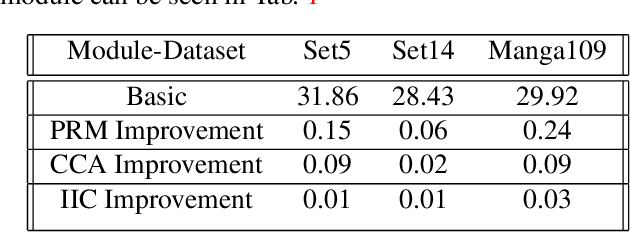
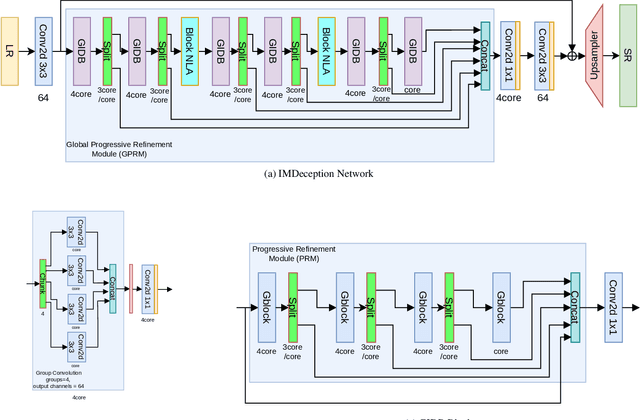
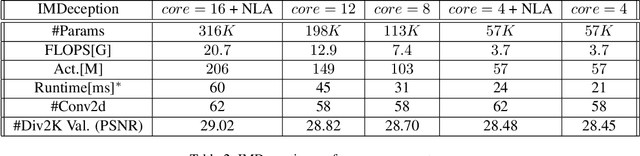
Single-Image-Super-Resolution (SISR) is a classical computer vision problem that has benefited from the recent advancements in deep learning methods, especially the advancements of convolutional neural networks (CNN). Although state-of-the-art methods improve the performance of SISR on several datasets, direct application of these networks for practical use is still an issue due to heavy computational load. For this purpose, recently, researchers have focused on more efficient and high-performing network structures. Information multi-distilling network (IMDN) is one of the highly efficient SISR networks with high performance and low computational load. IMDN achieves this efficiency with various mechanisms such as Intermediate Information Collection (IIC), working in a global setting, Progressive Refinement Module (PRM), and Contrast Aware Channel Attention (CCA), employed in a local setting. These mechanisms, however, do not equally contribute to the efficiency and performance of IMDN. In this work, we propose the Global Progressive Refinement Module (GPRM) as a less parameter-demanding alternative to the IIC module for feature aggregation. To further decrease the number of parameters and floating point operations persecond (FLOPS), we also propose Grouped Information Distilling Blocks (GIDB). Using the proposed structures, we design an efficient SISR network called IMDeception. Experiments reveal that the proposed network performs on par with state-of-the-art models despite having a limited number of parameters and FLOPS. Furthermore, using grouped convolutions as a building block of GIDB increases room for further optimization during deployment. To show its potential, the proposed model was deployed on NVIDIA Jetson Xavier AGX and it has been shown that it can run in real-time on this edge device
Extremely Lightweight Quantization Robust Real-Time Single-Image Super Resolution for Mobile Devices
May 21, 2021
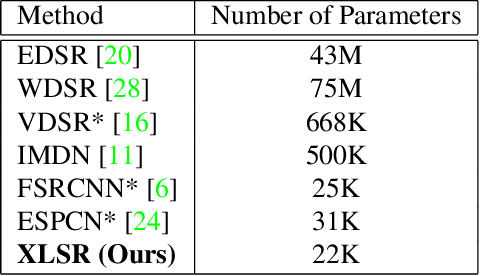
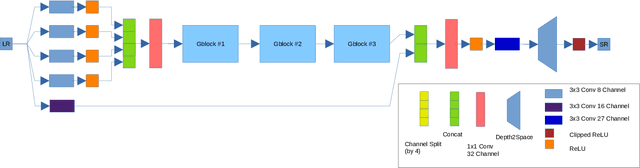

Single-Image Super Resolution (SISR) is a classical computer vision problem and it has been studied for over decades. With the recent success of deep learning methods, recent work on SISR focuses solutions with deep learning methodologies and achieves state-of-the-art results. However most of the state-of-the-art SISR methods contain millions of parameters and layers, which limits their practical applications. In this paper, we propose a hardware (Synaptics Dolphin NPU) limitation aware, extremely lightweight quantization robust real-time super resolution network (XLSR). The proposed model's building block is inspired from root modules for Image classification. We successfully applied root modules to SISR problem, further more to make the model uint8 quantization robust we used Clipped ReLU at the last layer of the network and achieved great balance between reconstruction quality and runtime. Furthermore, although the proposed network contains 30x fewer parameters than VDSR its performance surpasses it on Div2K validation set. The network proved itself by winning Mobile AI 2021 Real-Time Single Image Super Resolution Challenge.
Real-Time Quantized Image Super-Resolution on Mobile NPUs, Mobile AI 2021 Challenge: Report
May 17, 2021
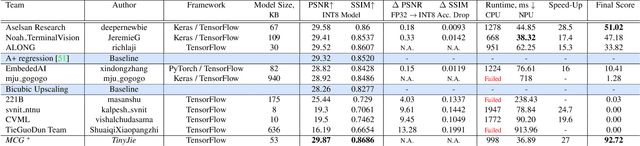
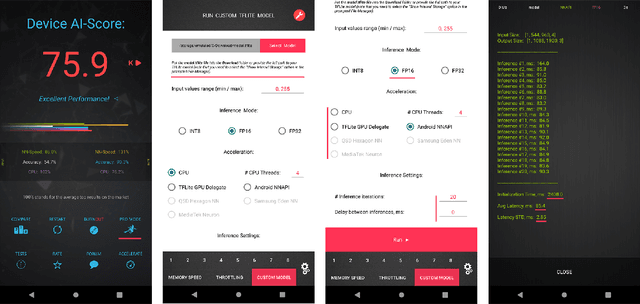
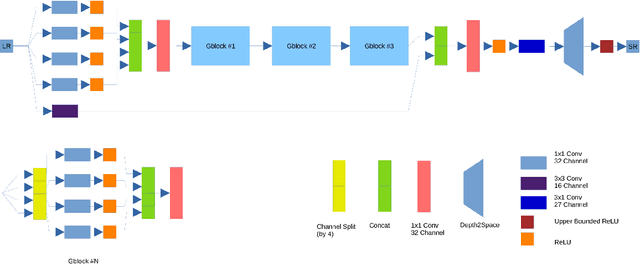
Image super-resolution is one of the most popular computer vision problems with many important applications to mobile devices. While many solutions have been proposed for this task, they are usually not optimized even for common smartphone AI hardware, not to mention more constrained smart TV platforms that are often supporting INT8 inference only. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based image super-resolution solutions that can demonstrate a real-time performance on mobile or edge NPUs. For this, the participants were provided with the DIV2K dataset and trained quantized models to do an efficient 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated NPU capable of accelerating quantized neural networks. The proposed solutions are fully compatible with all major mobile AI accelerators and are capable of reconstructing Full HD images under 40-60 ms while achieving high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.