 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Framework for Multimodal Named Entity Recognition with Multi-level Alignments
May 15, 2023



Mining structured knowledge from tweets using named entity recognition (NER) can be beneficial for many downstream applications such as recommendation and intention under standing. With tweet posts tending to be multimodal, multimodal named entity recognition (MNER) has attracted more attention. In this paper, we propose a novel approach, which can dynamically align the image and text sequence and achieve the multi-level cross-modal learning to augment textual word representation for MNER improvement. To be specific, our framework can be split into three main stages: the first stage focuses on intra-modality representation learning to derive the implicit global and local knowledge of each modality, the second evaluates the relevance between the text and its accompanying image and integrates different grained visual information based on the relevance, the third enforces semantic refinement via iterative cross-modal interactions and co-attention. We conduct experiments on two open datasets, and the results and detailed analysis demonstrate the advantage of our model.
Improving the Modality Representation with Multi-View Contrastive Learning for Multimodal Sentiment Analysis
Oct 28, 2022


Modality representation learning is an important problem for multimodal sentiment analysis (MSA), since the highly distinguishable representations can contribute to improving the analysis effect. Previous works of MSA have usually focused on multimodal fusion strategies, and the deep study of modal representation learning was given less attention. Recently, contrastive learning has been confirmed effective at endowing the learned representation with stronger discriminate ability. Inspired by this, we explore the improvement approaches of modality representation with contrastive learning in this study. To this end, we devise a three-stages framework with multi-view contrastive learning to refine representations for the specific objectives. At the first stage, for the improvement of unimodal representations, we employ the supervised contrastive learning to pull samples within the same class together while the other samples are pushed apart. At the second stage, a self-supervised contrastive learning is designed for the improvement of the distilled unimodal representations after cross-modal interaction. At last, we leverage again the supervised contrastive learning to enhance the fused multimodal representation. After all the contrast trainings, we next achieve the classification task based on frozen representations. We conduct experiments on three open datasets, and results show the advance of our model.
CEntRE: A paragraph-level Chinese dataset for Relation Extraction among Enterprises
Oct 19, 2022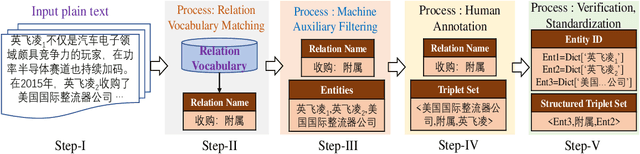

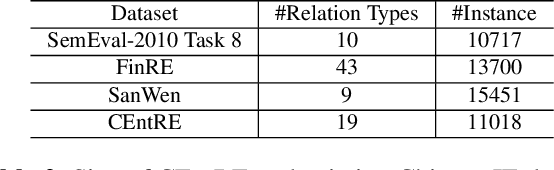

Enterprise relation extraction aims to detect pairs of enterprise entities and identify the business relations between them from unstructured or semi-structured text data, and it is crucial for several real-world applications such as risk analysis, rating research and supply chain security. However, previous work mainly focuses on getting attribute information about enterprises like personnel and corporate business, and pays little attention to enterprise relation extraction. To encourage further progress in the research, we introduce the CEntRE, a new dataset constructed from publicly available business news data with careful human annotation and intelligent data processing. Extensive experiments on CEntRE with six excellent models demonstrate the challenges of our proposed dataset.
Multi-features based Semantic Augmentation Networks for Named Entity Recognition in Threat Intelligence
Jul 01, 2022

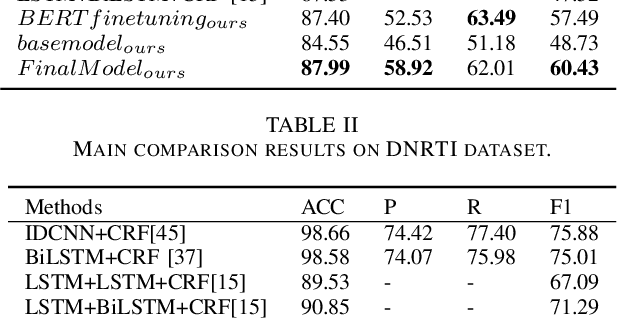

Extracting cybersecurity entities such as attackers and vulnerabilities from unstructured network texts is an important part of security analysis. However, the sparsity of intelligence data resulted from the higher frequency variations and the randomness of cybersecurity entity names makes it difficult for current methods to perform well in extracting security-related concepts and entities. To this end, we propose a semantic augmentation method which incorporates different linguistic features to enrich the representation of input tokens to detect and classify the cybersecurity names over unstructured text. In particular, we encode and aggregate the constituent feature, morphological feature and part of speech feature for each input token to improve the robustness of the method. More than that, a token gets augmented semantic information from its most similar K words in cybersecurity domain corpus where an attentive module is leveraged to weigh differences of the words, and from contextual clues based on a large-scale general field corpus. We have conducted experiments on the cybersecurity datasets DNRTI and MalwareTextDB, and the results demonstrate the effectiveness of the proposed method.
Threat Detection for General Social Engineering Attack Using Machine Learning Techniques
Mar 17, 2022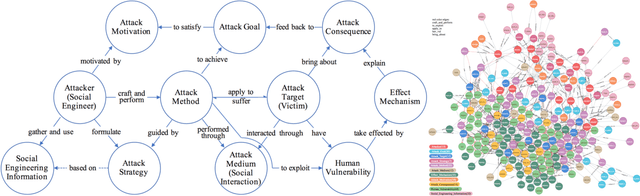
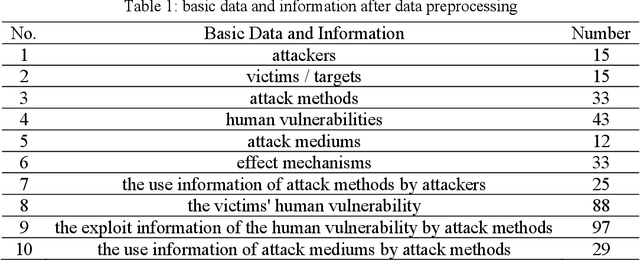


This paper explores the threat detection for general Social Engineering (SE) attack using Machine Learning (ML) techniques, rather than focusing on or limited to a specific SE attack type, e.g. email phishing. Firstly, this paper processes and obtains more SE threat data from the previous Knowledge Graph (KG), and then extracts different threat features and generates new datasets corresponding with three different feature combinations. Finally, 9 types of ML models are created and trained using the three datasets, respectively, and their performance are compared and analyzed with 27 threat detectors and 270 times of experiments. The experimental results and analyses show that: 1) the ML techniques are feasible in detecting general SE attacks and some ML models are quite effective; ML-based SE threat detection is complementary with KG-based approaches; 2) the generated datasets are usable and the SE domain ontology proposed in previous work can dissect SE attacks and deliver the SE threat features, allowing it to be used as a data model for future research. Besides, more conclusions and analyses about the characteristics of different ML detectors and the datasets are discussed.