 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoPECraft: Training-Free Motion Transfer with Trajectory-Guided RoPE Optimization on Diffusion Transformers
May 19, 2025



We propose RoPECraft, a training-free video motion transfer method for diffusion transformers that operates solely by modifying their rotary positional embeddings (RoPE). We first extract dense optical flow from a reference video, and utilize the resulting motion offsets to warp the complex-exponential tensors of RoPE, effectively encoding motion into the generation process. These embeddings are then further optimized during denoising time steps via trajectory alignment between the predicted and target velocities using a flow-matching objective. To keep the output faithful to the text prompt and prevent duplicate generations, we incorporate a regularization term based on the phase components of the reference video's Fourier transform, projecting the phase angles onto a smooth manifold to suppress high-frequency artifacts. Experiments on benchmarks reveal that RoPECraft outperforms all recently published methods, both qualitatively and quantitatively.
Identity Preserving 3D Head Stylization with Multiview Score Distillation
Nov 20, 2024



3D head stylization transforms realistic facial features into artistic representations, enhancing user engagement across gaming and virtual reality applications. While 3D-aware generators have made significant advancements, many 3D stylization methods primarily provide near-frontal views and struggle to preserve the unique identities of original subjects, often resulting in outputs that lack diversity and individuality. This paper addresses these challenges by leveraging the PanoHead model, synthesizing images from a comprehensive 360-degree perspective. We propose a novel framework that employs negative log-likelihood distillation (LD) to enhance identity preservation and improve stylization quality. By integrating multi-view grid score and mirror gradients within the 3D GAN architecture and introducing a score rank weighing technique, our approach achieves substantial qualitative and quantitative improvements. Our findings not only advance the state of 3D head stylization but also provide valuable insights into effective distillation processes between diffusion models and GANs, focusing on the critical issue of identity preservation. Please visit the https://three-bee.github.io/head_stylization for more visuals.
Dual Encoder GAN Inversion for High-Fidelity 3D Head Reconstruction from Single Images
Sep 30, 2024



3D GAN inversion aims to project a single image into the latent space of a 3D Generative Adversarial Network (GAN), thereby achieving 3D geometry reconstruction. While there exist encoders that achieve good results in 3D GAN inversion, they are predominantly built on EG3D, which specializes in synthesizing near-frontal views and is limiting in synthesizing comprehensive 3D scenes from diverse viewpoints. In contrast to existing approaches, we propose a novel framework built on PanoHead, which excels in synthesizing images from a 360-degree perspective. To achieve realistic 3D modeling of the input image, we introduce a dual encoder system tailored for high-fidelity reconstruction and realistic generation from different viewpoints. Accompanying this, we propose a stitching framework on the triplane domain to get the best predictions from both. To achieve seamless stitching, both encoders must output consistent results despite being specialized for different tasks. For this reason, we carefully train these encoders using specialized losses, including an adversarial loss based on our novel occlusion-aware triplane discriminator. Experiments reveal that our approach surpasses the existing encoder training methods qualitatively and quantitatively. Please visit the project page: https://berkegokmen1.github.io/dual-enc-3d-gan-inv.
Bayesian Conditioned Diffusion Models for Inverse Problems
Jun 14, 2024



Diffusion models have recently been shown to excel in many image reconstruction tasks that involve inverse problems based on a forward measurement operator. A common framework uses task-agnostic unconditional models that are later post-conditioned for reconstruction, an approach that typically suffers from suboptimal task performance. While task-specific conditional models have also been proposed, current methods heuristically inject measured data as a naive input channel that elicits sampling inaccuracies. Here, we address the optimal conditioning of diffusion models for solving challenging inverse problems that arise during image reconstruction. Specifically, we propose a novel Bayesian conditioning technique for diffusion models, BCDM, based on score-functions associated with the conditional distribution of desired images given measured data. We rigorously derive the theory to express and train the conditional score-function. Finally, we show state-of-the-art performance in image dealiasing, deblurring, super-resolution, and inpainting with the proposed technique.
Reference-Based 3D-Aware Image Editing with Triplane
Apr 04, 2024



Generative Adversarial Networks (GANs) have emerged as powerful tools not only for high-quality image generation but also for real image editing through manipulation of their interpretable latent spaces. Recent advancements in GANs include the development of 3D-aware models such as EG3D, characterized by efficient triplane-based architectures enabling the reconstruction of 3D geometry from single images. However, scant attention has been devoted to providing an integrated framework for high-quality reference-based 3D-aware image editing within this domain. This study addresses this gap by exploring and demonstrating the effectiveness of EG3D's triplane space for achieving advanced reference-based edits, presenting a unique perspective on 3D-aware image editing through our novel pipeline. Our approach integrates the encoding of triplane features, spatial disentanglement and automatic localization of features in the triplane domain, and fusion learning for desired image editing. Moreover, our framework demonstrates versatility across domains, extending its effectiveness to animal face edits and partial stylization of cartoon portraits. The method shows significant improvements over relevant 3D-aware latent editing and 2D reference-based editing methods, both qualitatively and quantitatively. Project page: https://three-bee.github.io/triplane_edit
Towards Clip-Free Quantized Super-Resolution Networks: How to Tame Representative Images
Aug 22, 2023Super-resolution (SR) networks have been investigated for a while, with their mobile and lightweight versions gaining noticeable popularity recently. Quantization, the procedure of decreasing the precision of network parameters (mostly FP32 to INT8), is also utilized in SR networks for establishing mobile compatibility. This study focuses on a very important but mostly overlooked post-training quantization (PTQ) step: representative dataset (RD), which adjusts the quantization range for PTQ. We propose a novel pipeline (clip-free quantization pipeline, CFQP) backed up with extensive experimental justifications to cleverly augment RD images by only using outputs of the FP32 model. Using the proposed pipeline for RD, we can successfully eliminate unwanted clipped activation layers, which nearly all mobile SR methods utilize to make the model more robust to PTQ in return for a large overhead in runtime. Removing clipped activations with our method significantly benefits overall increased stability, decreased inference runtime up to 54% on some SR models, better visual quality results compared to INT8 clipped models - and outperforms even some FP32 non-quantized models, both in runtime and visual quality, without the need for retraining with clipped activation.
Diverse Inpainting and Editing with GAN Inversion
Jul 27, 2023



Recent inversion methods have shown that real images can be inverted into StyleGAN's latent space and numerous edits can be achieved on those images thanks to the semantically rich feature representations of well-trained GAN models. However, extensive research has also shown that image inversion is challenging due to the trade-off between high-fidelity reconstruction and editability. In this paper, we tackle an even more difficult task, inverting erased images into GAN's latent space for realistic inpaintings and editings. Furthermore, by augmenting inverted latent codes with different latent samples, we achieve diverse inpaintings. Specifically, we propose to learn an encoder and mixing network to combine encoded features from erased images with StyleGAN's mapped features from random samples. To encourage the mixing network to utilize both inputs, we train the networks with generated data via a novel set-up. We also utilize higher-rate features to prevent color inconsistencies between the inpainted and unerased parts. We run extensive experiments and compare our method with state-of-the-art inversion and inpainting methods. Qualitative metrics and visual comparisons show significant improvements.
Bicubic++: Slim, Slimmer, Slimmest -- Designing an Industry-Grade Super-Resolution Network
May 03, 2023



We propose a real-time and lightweight single-image super-resolution (SR) network named Bicubic++. Despite using spatial dimensions of the input image across the whole network, Bicubic++ first learns quick reversible downgraded and lower resolution features of the image in order to decrease the number of computations. We also construct a training pipeline, where we apply an end-to-end global structured pruning of convolutional layers without using metrics like magnitude and gradient norms, and focus on optimizing the pruned network's PSNR on the validation set. Furthermore, we have experimentally shown that the bias terms take considerable amount of the runtime while increasing PSNR marginally, hence we have also applied bias removal to the convolutional layers. Our method adds ~1dB on Bicubic upscaling PSNR for all tested SR datasets and runs with ~1.17ms on RTX3090 and ~2.9ms on RTX3070, for 720p inputs and 4K outputs, both in FP16 precision. Bicubic++ won NTIRE 2023 RTSR Track 2 x3 SR competition and is the fastest among all competitive methods. Being almost as fast as the standard Bicubic upsampling method, we believe that Bicubic++ can set a new industry standard.
Efficient and Accurate Quantized Image Super-Resolution on Mobile NPUs, Mobile AI & AIM 2022 challenge: Report
Nov 07, 2022



Image super-resolution is a common task on mobile and IoT devices, where one often needs to upscale and enhance low-resolution images and video frames. While numerous solutions have been proposed for this problem in the past, they are usually not compatible with low-power mobile NPUs having many computational and memory constraints. In this Mobile AI challenge, we address this problem and propose the participants to design an efficient quantized image super-resolution solution that can demonstrate a real-time performance on mobile NPUs. The participants were provided with the DIV2K dataset and trained INT8 models to do a high-quality 3X image upscaling. The runtime of all models was evaluated on the Synaptics VS680 Smart Home board with a dedicated edge NPU capable of accelerating quantized neural networks. All proposed solutions are fully compatible with the above NPU, demonstrating an up to 60 FPS rate when reconstructing Full HD resolution images. A detailed description of all models developed in the challenge is provided in this paper.
XCAT -- Lightweight Quantized Single Image Super-Resolution using Heterogeneous Group Convolutions and Cross Concatenation
Aug 31, 2022
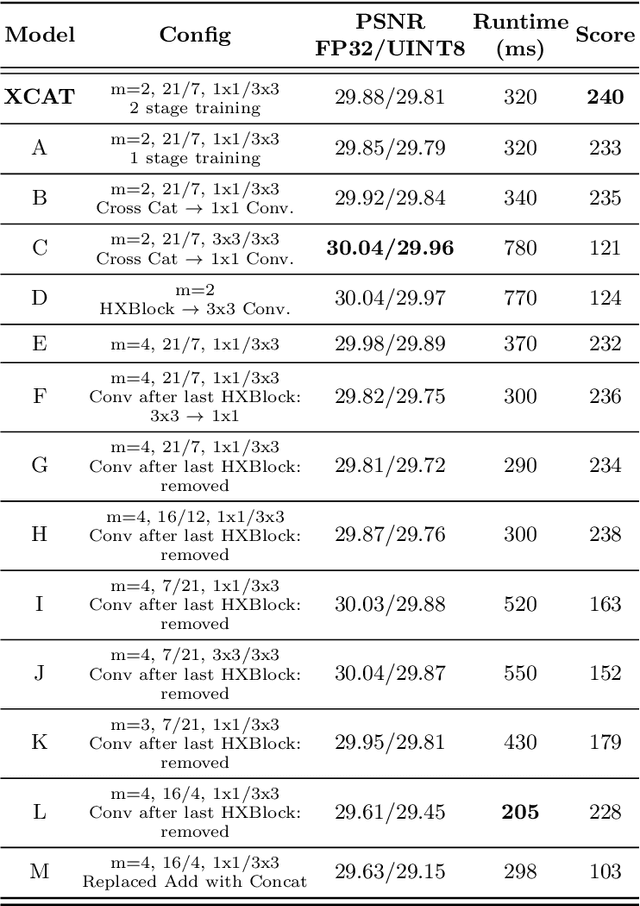
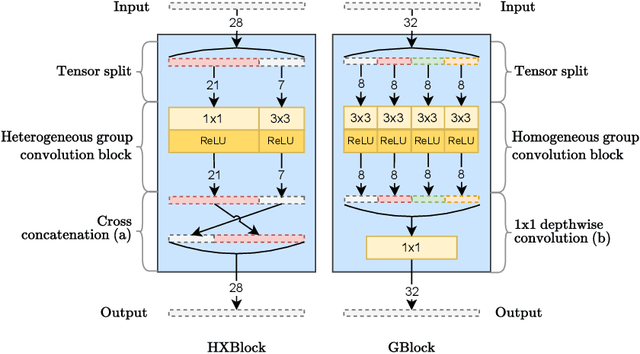
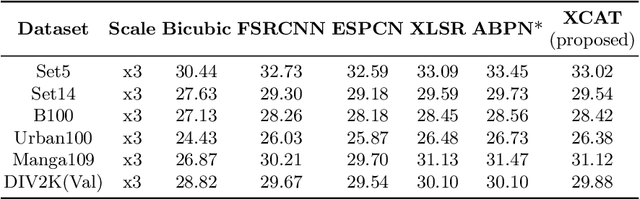
We propose a lightweight, single image super-resolution network for mobile devices, named XCAT. XCAT introduces Heterogeneous Group Convolution Blocks with Cross Concatenations (HXBlock). The heterogeneous split of the input channels to the group convolution blocks reduces the number of operations, and cross concatenation allows for information flow between the intermediate input tensors of cascaded HXBlocks. Cross concatenations inside HXBlocks can also avoid using more expensive operations like 1x1 convolutions. To further prev ent expensive tensor copy operations, XCAT utilizes non-trainable convolution kernels to apply up sampling operations. Designed with integer quantization in mind, XCAT also utilizes several techniques on training, like intensity-based data augmentation. Integer quantized XCAT operates in real time on Mali-G71 MP2 GPU with 320ms, and on Synaptics Dolphin NPU with 30ms (NCHW) and 8.8ms (NHWC), suitable for real-time applications.