 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2nd of the 5th PVUW MeViS-Audio Track: ASR-SaSaSa2VA
Apr 27, 2026Audio-based video object segmentation aims to locate and segment objects in videos conditioned on audio cues, requiring precise understanding of both appearance and motion. Recent audio-driven video segmentation methods extend MLLMs by fusing audio and visual features for end-to-end localization. Despite their promise, these approaches are computationally intensive, struggle with aligning temporal audio cues to dynamic video content, and depend on large paired audio-video datasets. To address these challenges, we present ASR-SaSaSa2VA, a resource-efficient framework for audio-guided video segmentation. The key idea is to convert audio inputs into textual motion descriptions via automatic speech recognition (ASR) models and then leverage pre-trained text-based referring video segmentation models (e.g., SaSaSa2VA) for pixel-level predictions. To further enhance robustness, we incorporate a no-target expression detection module, implemented by a fine-tuned audio-based MLLM, which filters out audio clips that do not refer to any target object. This design allows the system to exploit strong pre-trained models while effectively handling ambiguous or irrelevant audio inputs. Our approach achieves a final score of 80.7 in the 5th PVUW Challenge (MeViS-v2-Audio track), earning the second-place ranking.
OmniTabBench: Mapping the Empirical Frontiers of GBDTs, Neural Networks, and Foundation Models for Tabular Data at Scale
Apr 08, 2026While traditional tree-based ensemble methods have long dominated tabular tasks, deep neural networks and emerging foundation models have challenged this primacy, yet no consensus exists on a universally superior paradigm. Existing benchmarks typically contain fewer than 100 datasets, raising concerns about evaluation sufficiency and potential selection biases. To address these limitations, we introduce OmniTabBench, the largest tabular benchmark to date, comprising 3030 datasets spanning diverse tasks that are comprehensively collected from diverse sources and categorized by industry using large language models. We conduct an unprecedented large-scale empirical evaluation of state-of-the-art models from all model families on OmniTabBench, confirming the absence of a dominant winner. Furthermore, through a decoupled metafeature analysis, which examines individual properties such as dataset size, feature types, feature and target skewness/kurtosis, we elucidate conditions favoring specific model categories, providing clearer, more actionable guidance than prior compound-metric studies.
DeFRiS: Silo-Cooperative IoT Applications Scheduling via Decentralized Federated Reinforcement Learning
Mar 16, 2026Next-generation IoT applications increasingly span across autonomous administrative entities, necessitating silo-cooperative scheduling to leverage diverse computational resources while preserving data privacy. However, realizing efficient cooperation faces significant challenges arising from infrastructure heterogeneity, Non-IID workload shifts, and the inherent risks of adversarial environments. Existing approaches, relying predominantly on centralized coordination or independent learning, fail to address the incompatibility of state-action spaces across heterogeneous silos and lack robustness against malicious attacks. This paper proposes DeFRiS, a Decentralized Federated Reinforcement Learning framework for robust and scalable Silo-cooperative IoT application scheduling. DeFRiS integrates three synergistic innovations: (i) an action-space-agnostic policy utilizing candidate resource scoring to enable seamless knowledge transfer across heterogeneous silos; (ii) a silo-optimized local learning mechanism combining Generalized Advantage Estimation (GAE) with clipped policy updates to resolve sparse delayed reward challenges; and (iii) a Dual-Track Non-IID robust decentralized aggregation protocol leveraging gradient fingerprints for similarity-aware knowledge transfer and anomaly detection, and gradient tracking for optimization momentum. Extensive experiments on a distributed testbed with 20 heterogeneous silos and realistic IoT workloads demonstrate that DeFRiS significantly outperforms state-of-the-art baselines, reducing average response time by 6.4% and energy consumption by 7.2%, while lowering tail latency risk (CVaR$_{0.95}$) by 10.4% and achieving near-zero deadline violations. Furthermore, DeFRiS achieves over 3 times better performance retention as the system scales and over 8 times better stability in adversarial environments compared to the best-performing baseline.
AirFed: Federated Graph-Enhanced Multi-Agent Reinforcement Learning for Multi-UAV Cooperative Mobile Edge Computing
Oct 27, 2025Multiple Unmanned Aerial Vehicles (UAVs) cooperative Mobile Edge Computing (MEC) systems face critical challenges in coordinating trajectory planning, task offloading, and resource allocation while ensuring Quality of Service (QoS) under dynamic and uncertain environments. Existing approaches suffer from limited scalability, slow convergence, and inefficient knowledge sharing among UAVs, particularly when handling large-scale IoT device deployments with stringent deadline constraints. This paper proposes AirFed, a novel federated graph-enhanced multi-agent reinforcement learning framework that addresses these challenges through three key innovations. First, we design dual-layer dynamic Graph Attention Networks (GATs) that explicitly model spatial-temporal dependencies among UAVs and IoT devices, capturing both service relationships and collaborative interactions within the network topology. Second, we develop a dual-Actor single-Critic architecture that jointly optimizes continuous trajectory control and discrete task offloading decisions. Third, we propose a reputation-based decentralized federated learning mechanism with gradient-sensitive adaptive quantization, enabling efficient and robust knowledge sharing across heterogeneous UAVs. Extensive experiments demonstrate that AirFed achieves 42.9% reduction in weighted cost compared to state-of-the-art baselines, attains over 99% deadline satisfaction and 94.2% IoT device coverage rate, and reduces communication overhead by 54.5%. Scalability analysis confirms robust performance across varying UAV numbers, IoT device densities, and system scales, validating AirFed's practical applicability for large-scale UAV-MEC deployments.
SARCLIP: A Vision Language Foundation Model for Semantic Understanding and Target Recognition in SAR Imagery
Oct 26, 2025Synthetic Aperture Radar (SAR) has emerged as a crucial imaging modality due to its all-weather capabilities. While recent advancements in self-supervised learning and Masked Image Modeling (MIM) have paved the way for SAR foundation models, these approaches primarily focus on low-level visual features, often overlooking multimodal alignment and zero-shot target recognition within SAR imagery. To address this limitation, we construct SARCLIP-1M, a large-scale vision language dataset comprising over one million text-image pairs aggregated from existing datasets. We further introduce SARCLIP, the first vision language foundation model tailored for the SAR domain. Our SARCLIP model is trained using a contrastive vision language learning approach by domain transferring strategy, enabling it to bridge the gap between SAR imagery and textual descriptions. Extensive experiments on image-text retrieval and zero-shot classification tasks demonstrate the superior performance of SARCLIP in feature extraction and interpretation, significantly outperforming state-of-the-art foundation models and advancing the semantic understanding of SAR imagery. The code and datasets will be released soon.
MoRE-GNN: Multi-omics Data Integration with a Heterogeneous Graph Autoencoder
Oct 08, 2025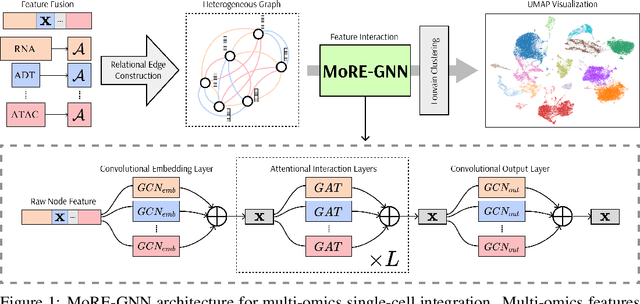

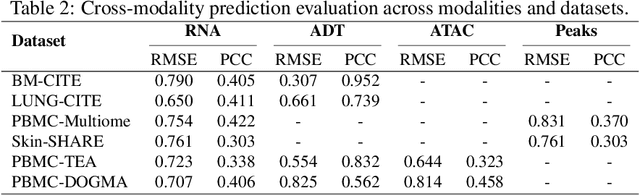
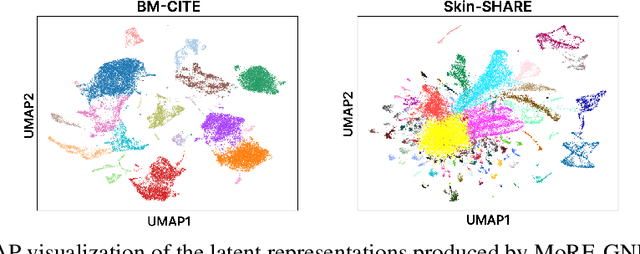
The integration of multi-omics single-cell data remains challenging due to high-dimensionality and complex inter-modality relationships. To address this, we introduce MoRE-GNN (Multi-omics Relational Edge Graph Neural Network), a heterogeneous graph autoencoder that combines graph convolution and attention mechanisms to dynamically construct relational graphs directly from data. Evaluations on six publicly available datasets demonstrate that MoRE-GNN captures biologically meaningful relationships and outperforms existing methods, particularly in settings with strong inter-modality correlations. Furthermore, the learned representations allow for accurate downstream cross-modal predictions. While performance may vary with dataset complexity, MoRE-GNN offers an adaptive, scalable and interpretable framework for advancing multi-omics integration.
MARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Topotein: Topological Deep Learning for Protein Representation Learning
Sep 04, 2025Protein representation learning (PRL) is crucial for understanding structure-function relationships, yet current sequence- and graph-based methods fail to capture the hierarchical organization inherent in protein structures. We introduce Topotein, a comprehensive framework that applies topological deep learning to PRL through the novel Protein Combinatorial Complex (PCC) and Topology-Complete Perceptron Network (TCPNet). Our PCC represents proteins at multiple hierarchical levels -- from residues to secondary structures to complete proteins -- while preserving geometric information at each level. TCPNet employs SE(3)-equivariant message passing across these hierarchical structures, enabling more effective capture of multi-scale structural patterns. Through extensive experiments on four PRL tasks, TCPNet consistently outperforms state-of-the-art geometric graph neural networks. Our approach demonstrates particular strength in tasks such as fold classification which require understanding of secondary structure arrangements, validating the importance of hierarchical topological features for protein analysis.
BioMARS: A Multi-Agent Robotic System for Autonomous Biological Experiments
Jul 02, 2025Large language models (LLMs) and vision-language models (VLMs) have the potential to transform biological research by enabling autonomous experimentation. Yet, their application remains constrained by rigid protocol design, limited adaptability to dynamic lab conditions, inadequate error handling, and high operational complexity. Here we introduce BioMARS (Biological Multi-Agent Robotic System), an intelligent platform that integrates LLMs, VLMs, and modular robotics to autonomously design, plan, and execute biological experiments. BioMARS uses a hierarchical architecture: the Biologist Agent synthesizes protocols via retrieval-augmented generation; the Technician Agent translates them into executable robotic pseudo-code; and the Inspector Agent ensures procedural integrity through multimodal perception and anomaly detection. The system autonomously conducts cell passaging and culture tasks, matching or exceeding manual performance in viability, consistency, and morphological integrity. It also supports context-aware optimization, outperforming conventional strategies in differentiating retinal pigment epithelial cells. A web interface enables real-time human-AI collaboration, while a modular backend allows scalable integration with laboratory hardware. These results highlight the feasibility of generalizable, AI-driven laboratory automation and the transformative role of language-based reasoning in biological research.
GraphAU-Pain: Graph-based Action Unit Representation for Pain Intensity Estimation
May 26, 2025Understanding pain-related facial behaviors is essential for digital healthcare in terms of effective monitoring, assisted diagnostics, and treatment planning, particularly for patients unable to communicate verbally. Existing data-driven methods of detecting pain from facial expressions are limited due to interpretability and severity quantification. To this end, we propose GraphAU-Pain, leveraging a graph-based framework to model facial Action Units (AUs) and their interrelationships for pain intensity estimation. AUs are represented as graph nodes, with co-occurrence relationships as edges, enabling a more expressive depiction of pain-related facial behaviors. By utilizing a relational graph neural network, our framework offers improved interpretability and significant performance gains. Experiments conducted on the publicly available UNBC dataset demonstrate the effectiveness of the GraphAU-Pain, achieving an F1-score of 66.21% and accuracy of 87.61% in pain intensity estimation.