 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Generative Model for Image Inpainting with Local Binary Pattern Learning and Spatial Attention
Sep 02, 2020


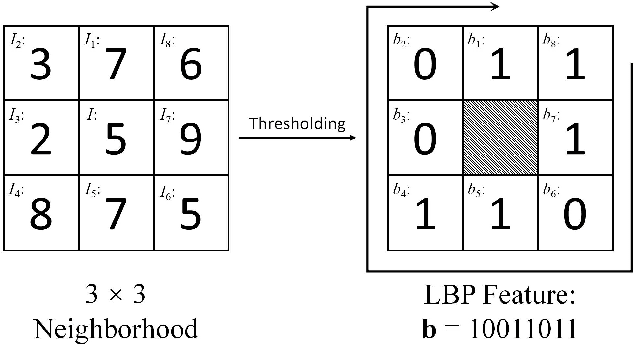
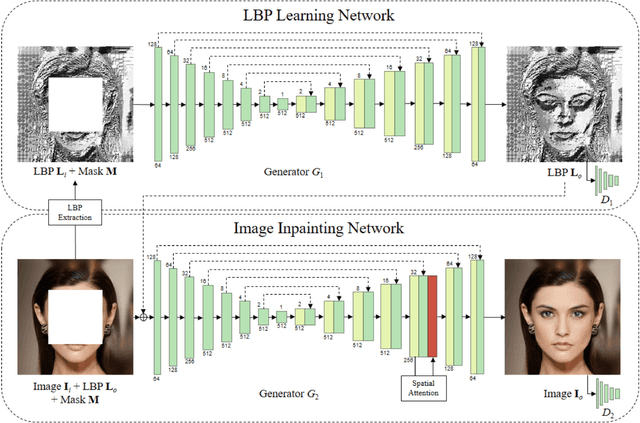
Deep learning (DL) has demonstrated its powerful capabilities in the field of image inpainting. The DL-based image inpainting approaches can produce visually plausible results, but often generate various unpleasant artifacts, especially in the boundary and highly textured regions. To tackle this challenge, in this work, we propose a new end-to-end, two-stage (coarse-to-fine) generative model through combining a local binary pattern (LBP) learning network with an actual inpainting network. Specifically, the first LBP learning network using U-Net architecture is designed to accurately predict the structural information of the missing region, which subsequently guides the second image inpainting network for better filling the missing pixels. Furthermore, an improved spatial attention mechanism is integrated in the image inpainting network, by considering the consistency not only between the known region with the generated one, but also within the generated region itself. Extensive experiments on public datasets including CelebA-HQ, Places and Paris StreetView demonstrate that our model generates better inpainting results than the state-of-the-art competing algorithms, both quantitatively and qualitatively. The source code and trained models will be made available at https://github.com/HighwayWu/ImageInpainting.
Conditional Image Generation and Manipulation for User-Specified Content
May 11, 2020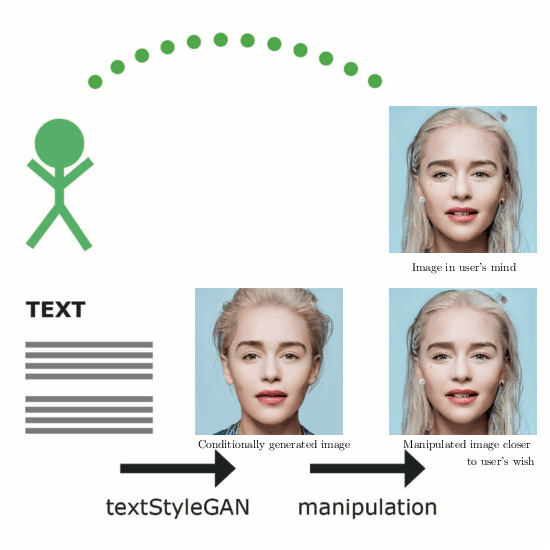
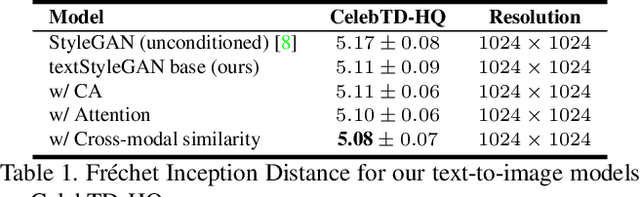
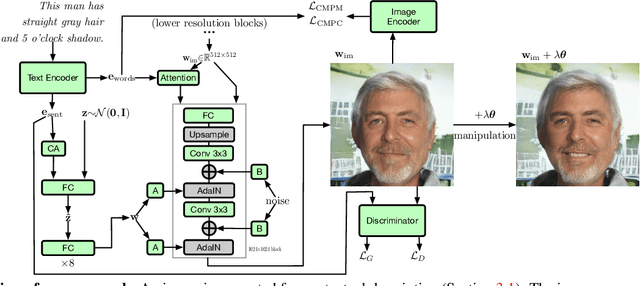
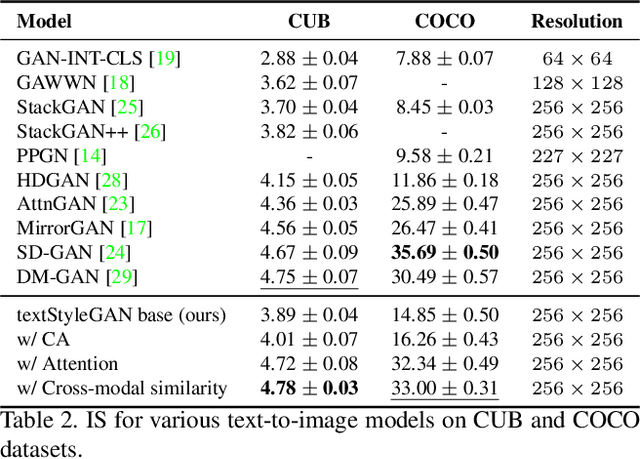
In recent years, Generative Adversarial Networks (GANs) have improved steadily towards generating increasingly impressive real-world images. It is useful to steer the image generation process for purposes such as content creation. This can be done by conditioning the model on additional information. However, when conditioning on additional information, there still exists a large set of images that agree with a particular conditioning. This makes it unlikely that the generated image is exactly as envisioned by a user, which is problematic for practical content creation scenarios such as generating facial composites or stock photos. To solve this problem, we propose a single pipeline for text-to-image generation and manipulation. In the first part of our pipeline we introduce textStyleGAN, a model that is conditioned on text. In the second part of our pipeline we make use of the pre-trained weights of textStyleGAN to perform semantic facial image manipulation. The approach works by finding semantic directions in latent space. We show that this method can be used to manipulate facial images for a wide range of attributes. Finally, we introduce the CelebTD-HQ dataset, an extension to CelebA-HQ, consisting of faces and corresponding textual descriptions.
MRI Recovery with A Self-calibrated Denoiser
Oct 18, 2021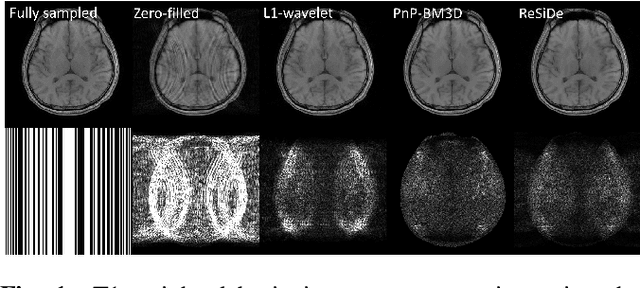
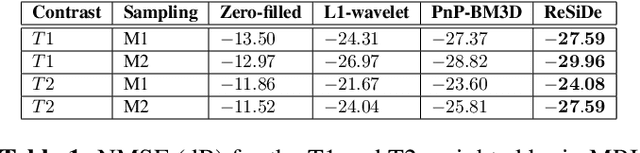
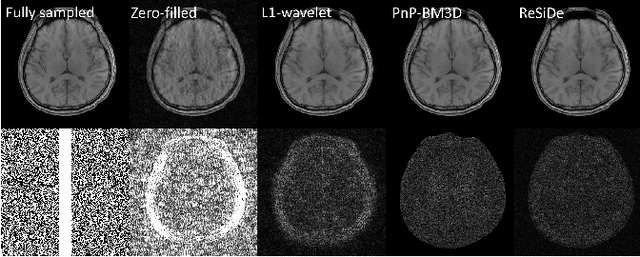
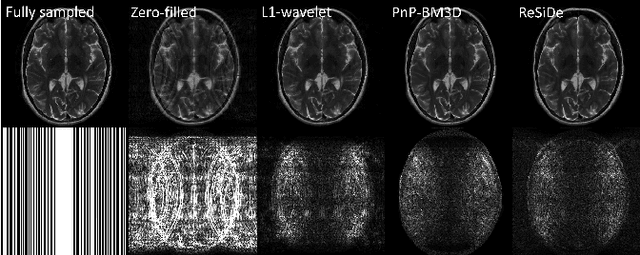
Plug-and-play (PnP) methods that employ application-specific denoisers have been proposed to solve inverse problems, including MRI reconstruction. However, training application-specific denoisers is not feasible for many applications due to the lack of training data. In this work, we propose a PnP-inspired recovery method that does not require data beyond the single, incomplete set of measurements. The proposed method, called recovery with a self-calibrated denoiser (ReSiDe), trains the denoiser from the patches of the image being recovered. The denoiser training and a call to the denoising subroutine are performed in each iteration of a PnP algorithm, leading to a progressive refinement of the reconstructed image. For validation, we compare ReSiDe with a compressed sensing-based method and a PnP method with BM3D denoising using single-coil MRI brain data.
edge-SR: Super-Resolution For The Masses
Aug 23, 2021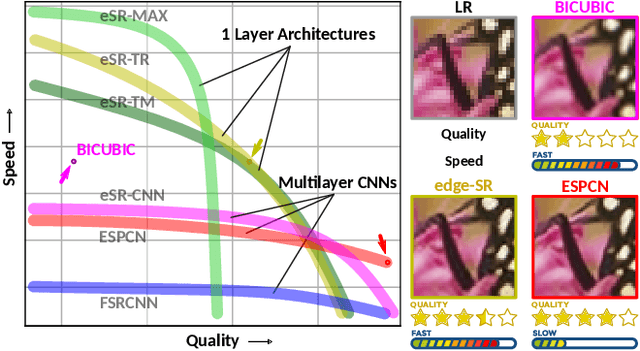

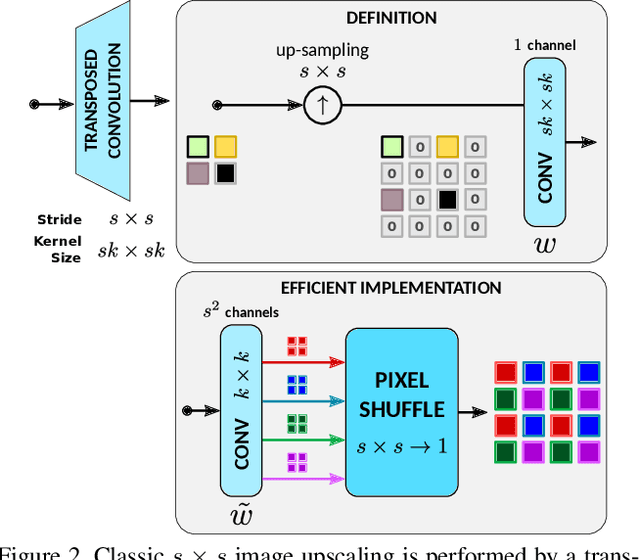
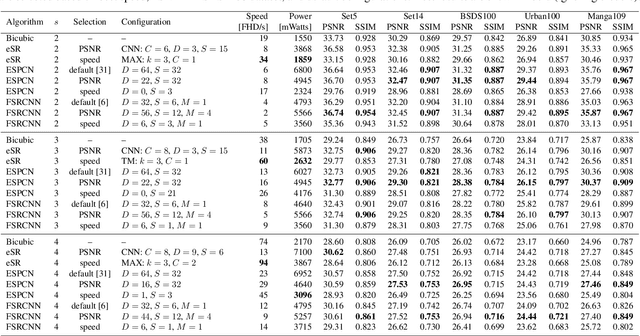
Classic image scaling (e.g. bicubic) can be seen as one convolutional layer and a single upscaling filter. Its implementation is ubiquitous in all display devices and image processing software. In the last decade deep learning systems have been introduced for the task of image super-resolution (SR), using several convolutional layers and numerous filters. These methods have taken over the benchmarks of image quality for upscaling tasks. Would it be possible to replace classic upscalers with deep learning architectures on edge devices such as display panels, tablets, laptop computers, etc.? On one hand, the current trend in Edge-AI chips shows a promising future in this direction, with rapid development of hardware that can run deep-learning tasks efficiently. On the other hand, in image SR only few architectures have pushed the limit to extreme small sizes that can actually run on edge devices at real-time. We explore possible solutions to this problem with the aim to fill the gap between classic upscalers and small deep learning configurations. As a transition from classic to deep-learning upscaling we propose edge-SR (eSR), a set of one-layer architectures that use interpretable mechanisms to upscale images. Certainly, a one-layer architecture cannot reach the quality of deep learning systems. Nevertheless, we find that for high speed requirements, eSR becomes better at trading-off image quality and runtime performance. Filling the gap between classic and deep-learning architectures for image upscaling is critical for massive adoption of this technology. It is equally important to have an interpretable system that can reveal the inner strategies to solve this problem and guide us to future improvements and better understanding of larger networks.
Graph Neural Networks for Cross-Camera Data Association
Jan 17, 2022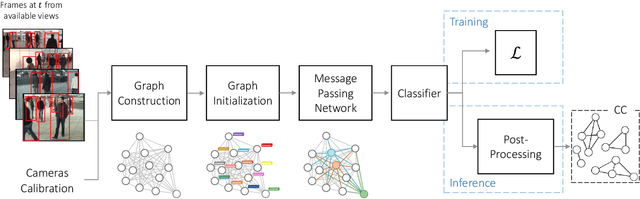
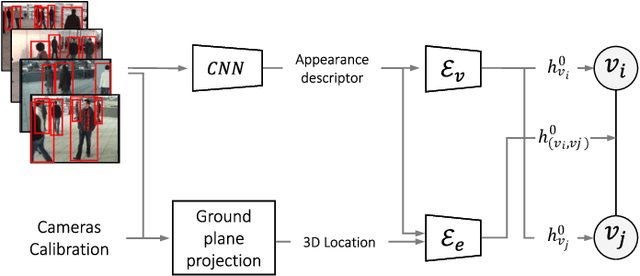
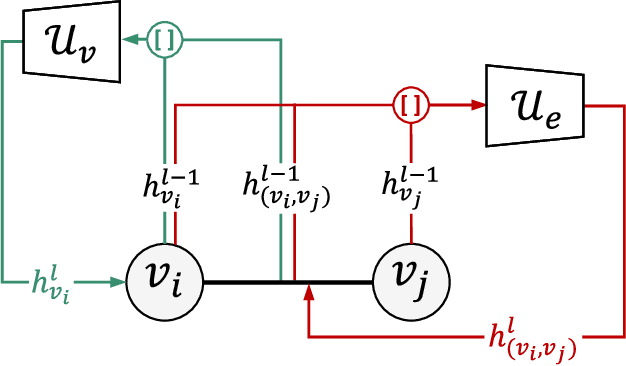
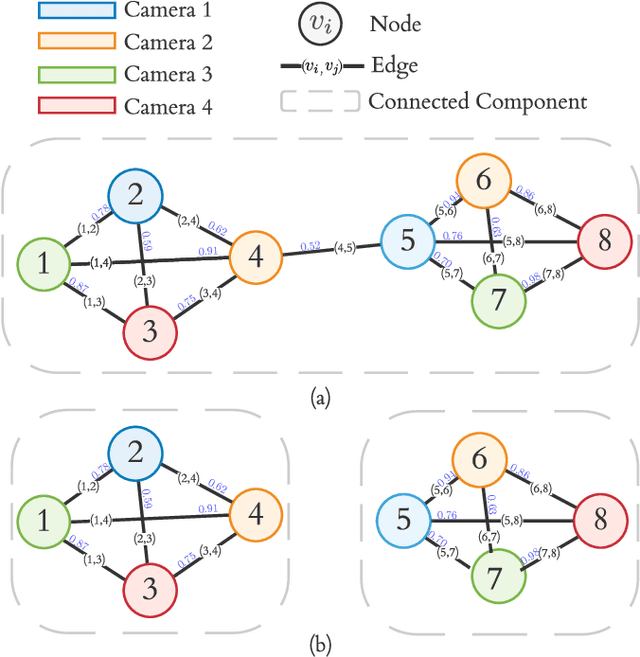
Cross-camera image data association is essential for many multi-camera computer vision tasks, such as multi-camera pedestrian detection, multi-camera multi-target tracking, 3D pose estimation, etc. This association task is typically stated as a bipartite graph matching problem and often solved by applying minimum-cost flow techniques, which may be computationally inefficient with large data. Furthermore, cameras are usually treated by pairs, obtaining local solutions, rather than finding a global solution at once. Other key issue is that of the affinity measurement: the widespread usage of non-learnable pre-defined distances, such as the Euclidean and Cosine ones. This paper proposes an efficient approach for cross-cameras data-association focused on a global solution, instead of processing cameras by pairs. To avoid the usage of fixed distances, we leverage the connectivity of Graph Neural Networks, previously unused in this scope, using a Message Passing Network to jointly learn features and similarity. We validate the proposal for pedestrian multi-view association, showing results over the EPFL multi-camera pedestrian dataset. Our approach considerably outperforms the literature data association techniques, without requiring to be trained in the same scenario in which it is tested. Our code is available at \url{http://www-vpu.eps.uam.es/publications/gnn_cca}.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020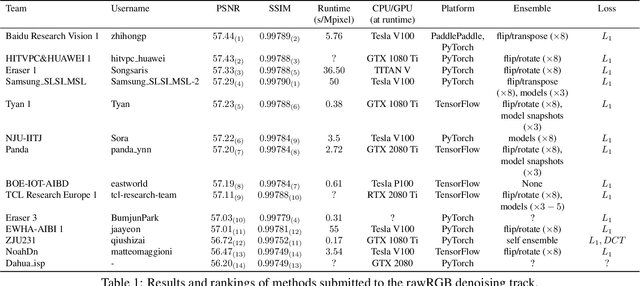
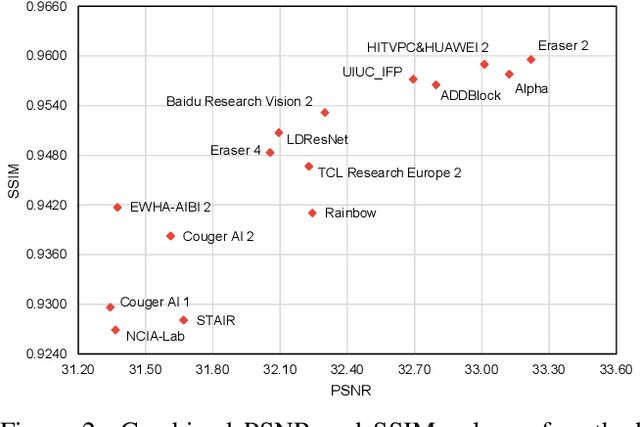
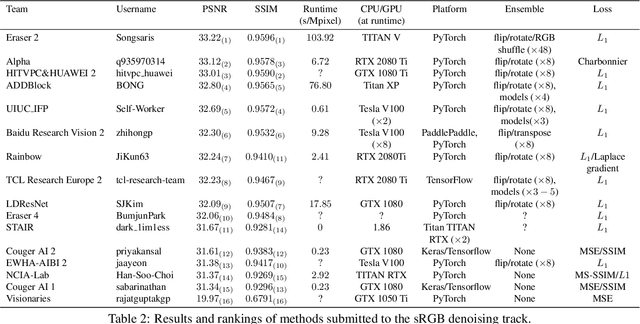
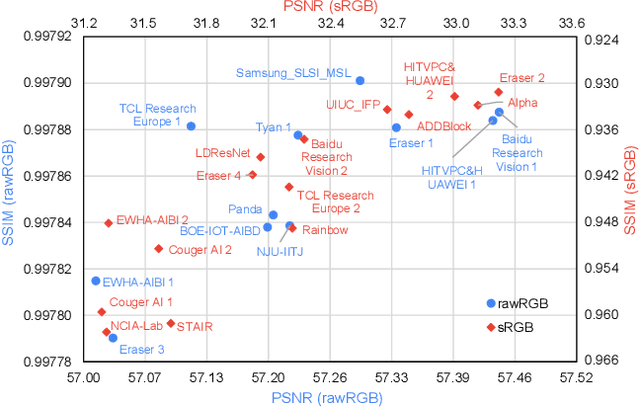
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
RGB Image Classification with Quantum Convolutional Ansaetze
Jul 23, 2021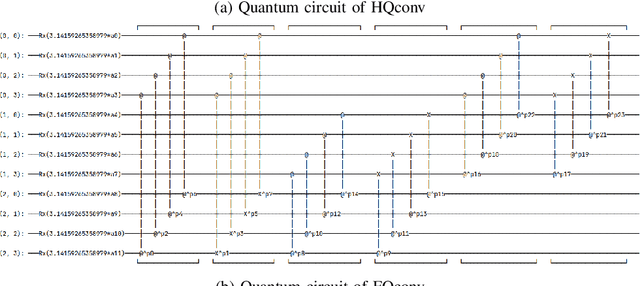
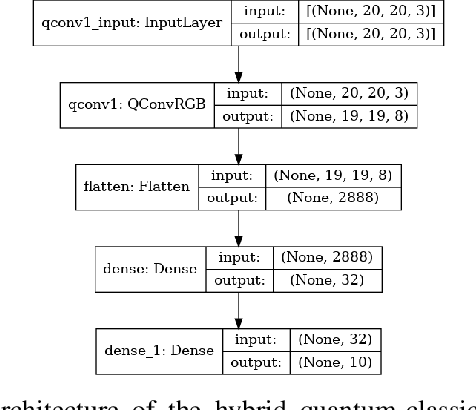
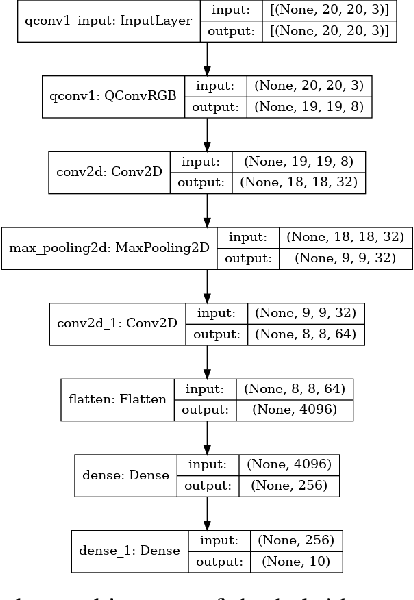
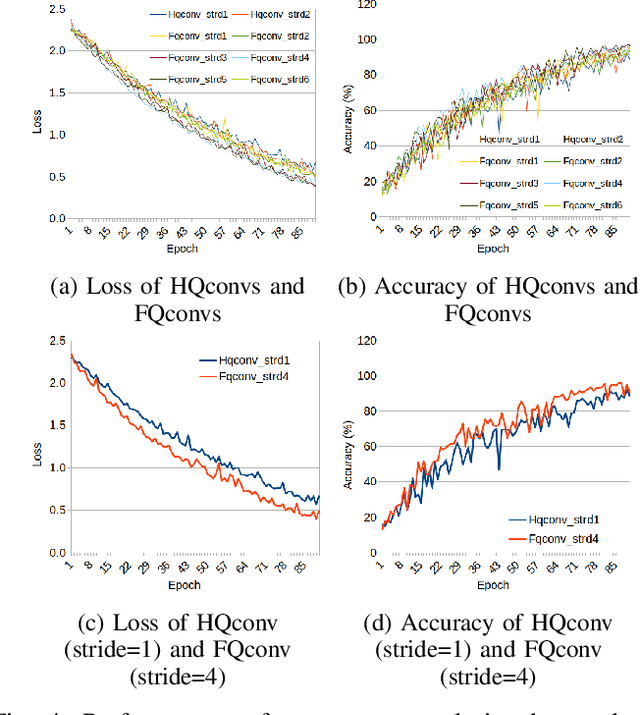
With the rapid growth of qubit numbers and coherence times in quantum hardware technology, implementing shallow neural networks on the so-called Noisy Intermediate-Scale Quantum (NISQ) devices has attracted a lot of interest. Many quantum (convolutional) circuit ansaetze are proposed for grayscale images classification tasks with promising empirical results. However, when applying these ansaetze on RGB images, the intra-channel information that is useful for vision tasks is not extracted effectively. In this paper, we propose two types of quantum circuit ansaetze to simulate convolution operations on RGB images, which differ in the way how inter-channel and intra-channel information are extracted. To the best of our knowledge, this is the first work of a quantum convolutional circuit to deal with RGB images effectively, with a higher test accuracy compared to the purely classical CNNs. We also investigate the relationship between the size of quantum circuit ansatz and the learnability of the hybrid quantum-classical convolutional neural network. Through experiments based on CIFAR-10 and MNIST datasets, we demonstrate that a larger size of the quantum circuit ansatz improves predictive performance in multiclass classification tasks, providing useful insights for near term quantum algorithm developments.
Parallel Rectangle Flip Attack: A Query-based Black-box Attack against Object Detection
Jan 22, 2022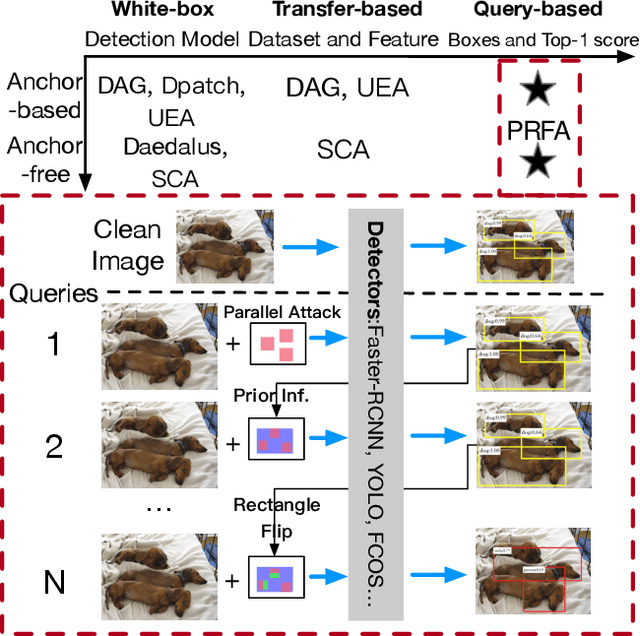


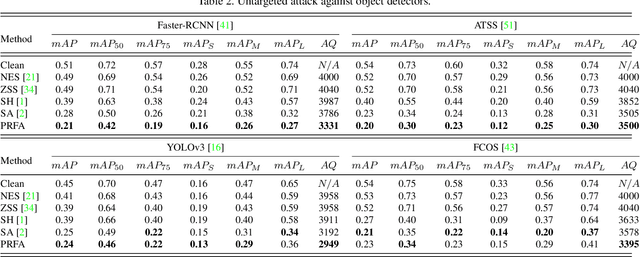
Object detection has been widely used in many safety-critical tasks, such as autonomous driving. However, its vulnerability to adversarial examples has not been sufficiently studied, especially under the practical scenario of black-box attacks, where the attacker can only access the query feedback of predicted bounding-boxes and top-1 scores returned by the attacked model. Compared with black-box attack to image classification, there are two main challenges in black-box attack to detection. Firstly, even if one bounding-box is successfully attacked, another sub-optimal bounding-box may be detected near the attacked bounding-box. Secondly, there are multiple bounding-boxes, leading to very high attack cost. To address these challenges, we propose a Parallel Rectangle Flip Attack (PRFA) via random search. We explain the difference between our method with other attacks in Fig.~\ref{fig1}. Specifically, we generate perturbations in each rectangle patch to avoid sub-optimal detection near the attacked region. Besides, utilizing the observation that adversarial perturbations mainly locate around objects' contours and critical points under white-box attacks, the search space of attacked rectangles is reduced to improve the attack efficiency. Moreover, we develop a parallel mechanism of attacking multiple rectangles simultaneously to further accelerate the attack process. Extensive experiments demonstrate that our method can effectively and efficiently attack various popular object detectors, including anchor-based and anchor-free, and generate transferable adversarial examples.
Monocular Road Planar Parallax Estimation
Nov 22, 2021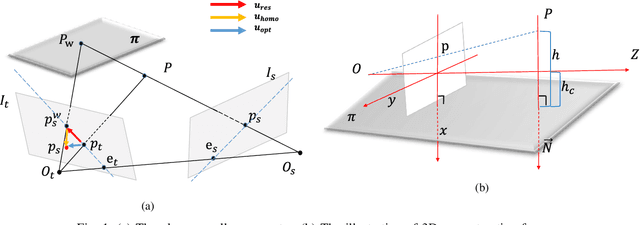
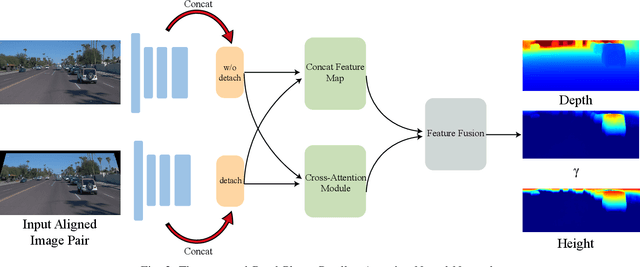
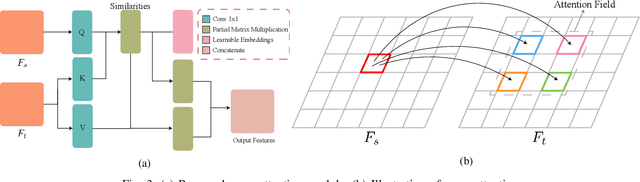

Estimating the 3D structure of the drivable surface and surrounding environment is a crucial task for assisted and autonomous driving. It is commonly solved either by using expensive 3D sensors such as LiDAR or directly predicting the depth of points via deep learning. Instead of following existing methodologies, we propose Road Planar Parallax Attention Network (RPANet), a new deep neural network for 3D sensing from monocular image sequences based on planar parallax, which takes full advantage of the commonly seen road plane geometry in driving scenes. RPANet takes a pair of images aligned by the homography of the road plane as input and outputs a $\gamma$ map for 3D reconstruction. Beyond estimating the depth or height, the $\gamma$ map has a potential to construct a two-dimensional transformation between two consecutive frames while can be easily derived to depth or height. By warping the consecutive frames using the road plane as a reference, the 3D structure can be estimated from the planar parallax and the residual image displacements. Furthermore, to make the network better perceive the displacements caused by planar parallax, we introduce a novel cross-attention module. We sample data from the Waymo Open Dataset and construct data related to planar parallax. Comprehensive experiments are conducted on the sampled dataset to demonstrate the 3D reconstruction accuracy of our approach in challenging scenarios.
Spectral Bias in Practice: The Role of Function Frequency in Generalization
Oct 06, 2021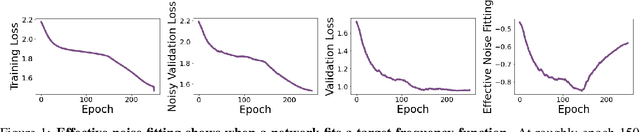
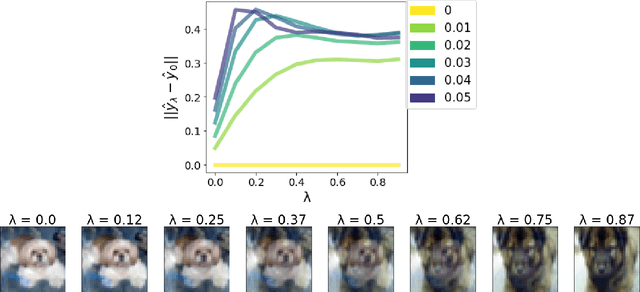
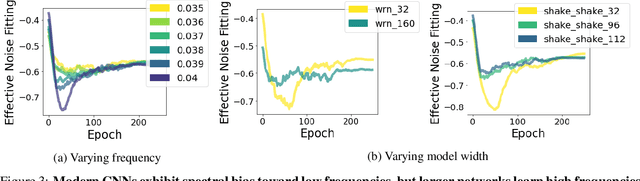
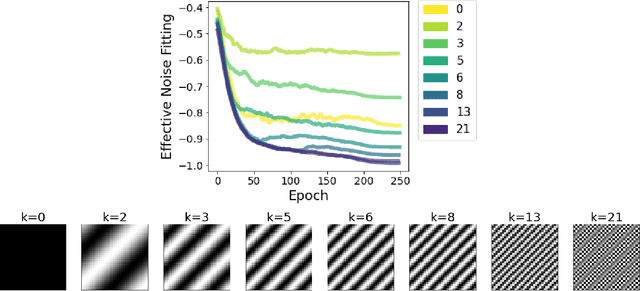
Despite their ability to represent highly expressive functions, deep learning models trained with SGD seem to find simple, constrained solutions that generalize surprisingly well. Spectral bias - the tendency of neural networks to prioritize learning low frequency functions - is one possible explanation for this phenomenon, but so far spectral bias has only been observed in theoretical models and simplified experiments. In this work, we propose methodologies for measuring spectral bias in modern image classification networks. We find that these networks indeed exhibit spectral bias, and that networks that generalize well strike a balance between having enough complexity(i.e. high frequencies) to fit the data while being simple enough to avoid overfitting. For example, we experimentally show that larger models learn high frequencies faster than smaller ones, but many forms of regularization, both explicit and implicit, amplify spectral bias and delay the learning of high frequencies. We also explore the connections between function frequency and image frequency and find that spectral bias is sensitive to the low frequencies prevalent in natural images. Our work enables measuring and ultimately controlling the spectral behavior of neural networks used for image classification, and is a step towards understanding why deep models generalize well