 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreoStream:Enhancing Stream Guardrails via Future-Aware Reasoning and Safety-Aligned Optimization
Jun 11, 2026Stream guardrails enable token-level safety detection before full responses are generated. However, they often make overly conservative judgements and block those sensitive but safe tokens, which is known as over-refusal. Due to lack of full context, they also fail to detect implicitly harmful content from jailbreaking. To address these challenges, we propose FreoStream, a novel streaming guardrail framework. Specifically, FreoStream fine-tunes a LoRA module to perform Future-Aware Reasoning when the base guardrail detects unsafe tokens. The reasoning process follows a Future-Reason-Judge paradigm: predict the future, reason about the full context and give the final judgement. This design can effectively reduce over-refusal by incorporating the future information. Moreover, we introduce the Safety-Aligned Optimization module that extracts the safety-aligned component from the reasoning gradients to update the base guardrail model, thereby enhancing streaming safety detection. Extensive experiments on various safety benchmarks demonstrate that FreoStream achieves lower over-refusal rates and better jailbreak defense compared to existing streaming guardrails.
RECITYGEN -- Interactive and Generative Participatory Urban Design Tool with Latent Diffusion and Segment Anything
Feb 04, 2026Urban design profoundly impacts public spaces and community engagement. Traditional top-down methods often overlook public input, creating a gap in design aspirations and reality. Recent advancements in digital tools, like City Information Modelling and augmented reality, have enabled a more participatory process involving more stakeholders in urban design. Further, deep learning and latent diffusion models have lowered barriers for design generation, providing even more opportunities for participatory urban design. Combining state-of-the-art latent diffusion models with interactive semantic segmentation, we propose RECITYGEN, a novel tool that allows users to interactively create variational street view images of urban environments using text prompts. In a pilot project in Beijing, users employed RECITYGEN to suggest improvements for an ongoing Urban Regeneration project. Despite some limitations, RECITYGEN has shown significant potential in aligning with public preferences, indicating a shift towards more dynamic and inclusive urban planning methods. The source code for the project can be found at RECITYGEN GitHub.
Dynamic Graph Representation Learning via Graph Transformer Networks
Nov 19, 2021
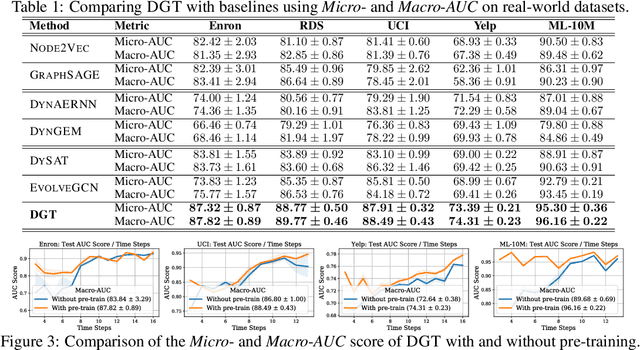
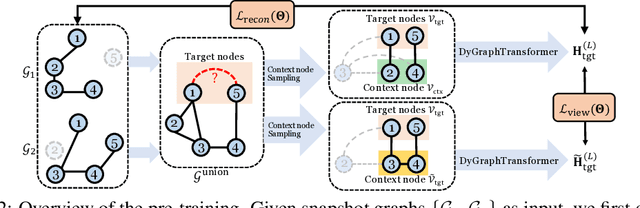
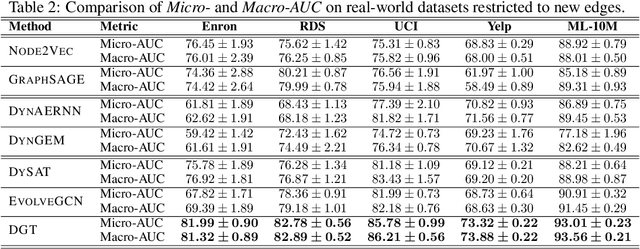
Dynamic graph representation learning is an important task with widespread applications. Previous methods on dynamic graph learning are usually sensitive to noisy graph information such as missing or spurious connections, which can yield degenerated performance and generalization. To overcome this challenge, we propose a Transformer-based dynamic graph learning method named Dynamic Graph Transformer (DGT) with spatial-temporal encoding to effectively learn graph topology and capture implicit links. To improve the generalization ability, we introduce two complementary self-supervised pre-training tasks and show that jointly optimizing the two pre-training tasks results in a smaller Bayesian error rate via an information-theoretic analysis. We also propose a temporal-union graph structure and a target-context node sampling strategy for efficient and scalable training. Extensive experiments on real-world datasets illustrate that DGT presents superior performance compared with several state-of-the-art baselines.
Beating Attackers At Their Own Games: Adversarial Example Detection Using Adversarial Gradient Directions
Dec 31, 2020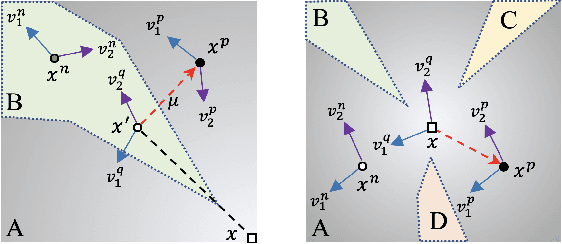

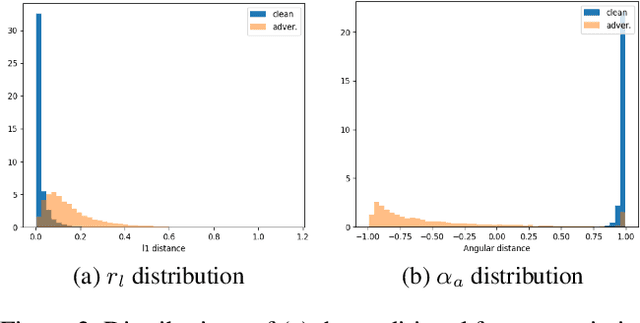

Adversarial examples are input examples that are specifically crafted to deceive machine learning classifiers. State-of-the-art adversarial example detection methods characterize an input example as adversarial either by quantifying the magnitude of feature variations under multiple perturbations or by measuring its distance from estimated benign example distribution. Instead of using such metrics, the proposed method is based on the observation that the directions of adversarial gradients when crafting (new) adversarial examples play a key role in characterizing the adversarial space. Compared to detection methods that use multiple perturbations, the proposed method is efficient as it only applies a single random perturbation on the input example. Experiments conducted on two different databases, CIFAR-10 and ImageNet, show that the proposed detection method achieves, respectively, 97.9% and 98.6% AUC-ROC (on average) on five different adversarial attacks, and outperforms multiple state-of-the-art detection methods. Results demonstrate the effectiveness of using adversarial gradient directions for adversarial example detection.
GroupIM: A Mutual Information Maximization Framework for Neural Group Recommendation
Jun 09, 2020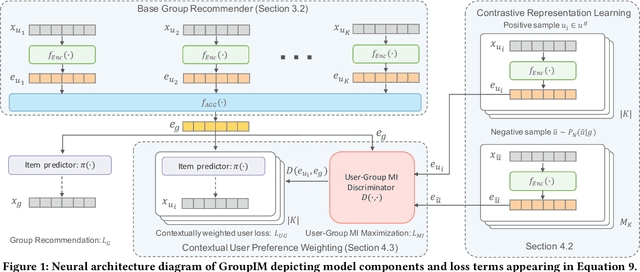
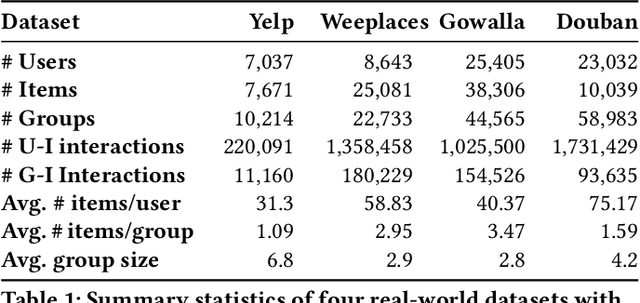
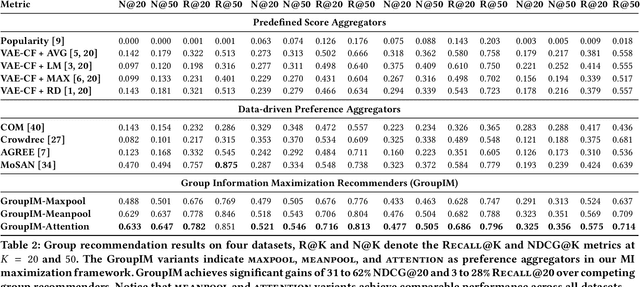
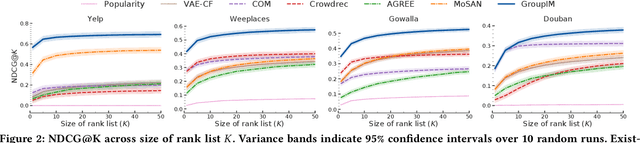
We study the problem of making item recommendations to ephemeral groups, which comprise users with limited or no historical activities together. Existing studies target persistent groups with substantial activity history, while ephemeral groups lack historical interactions. To overcome group interaction sparsity, we propose data-driven regularization strategies to exploit both the preference covariance amongst users who are in the same group, as well as the contextual relevance of users' individual preferences to each group. We make two contributions. First, we present a recommender architecture-agnostic framework GroupIM that can integrate arbitrary neural preference encoders and aggregators for ephemeral group recommendation. Second, we regularize the user-group latent space to overcome group interaction sparsity by: maximizing mutual information between representations of groups and group members; and dynamically prioritizing the preferences of highly informative members through contextual preference weighting. Our experimental results on several real-world datasets indicate significant performance improvements (31-62% relative NDCG@20) over state-of-the-art group recommendation techniques.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020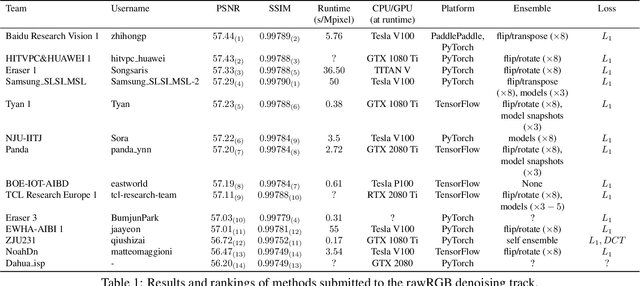
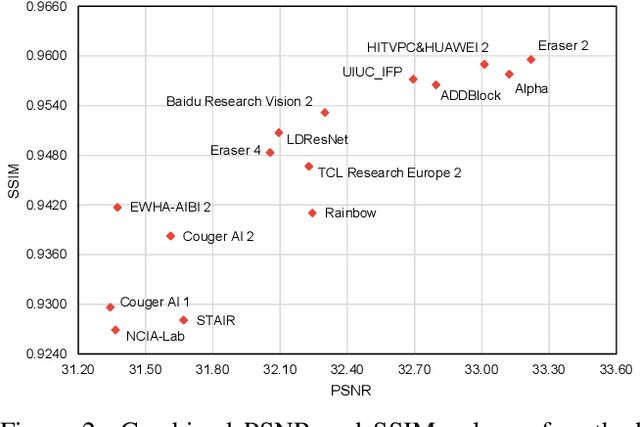
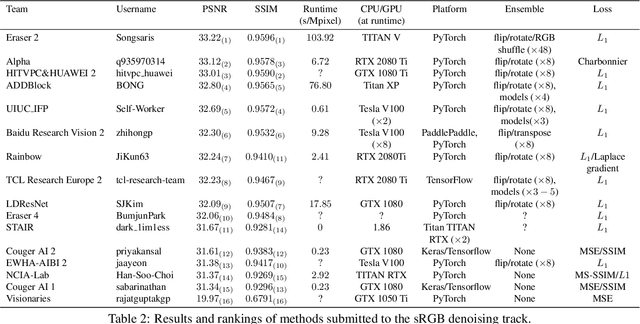
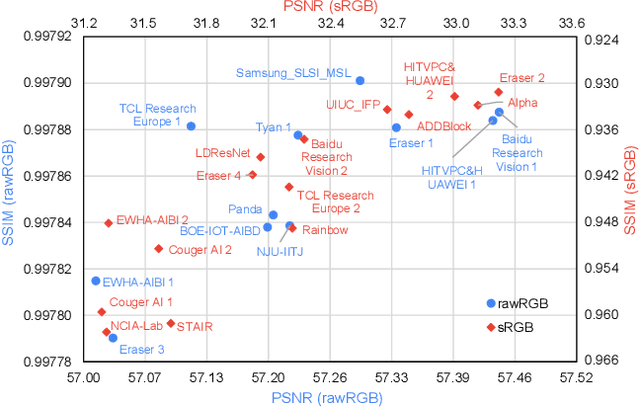
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Dynamic Graph Representation Learning via Self-Attention Networks
Dec 22, 2018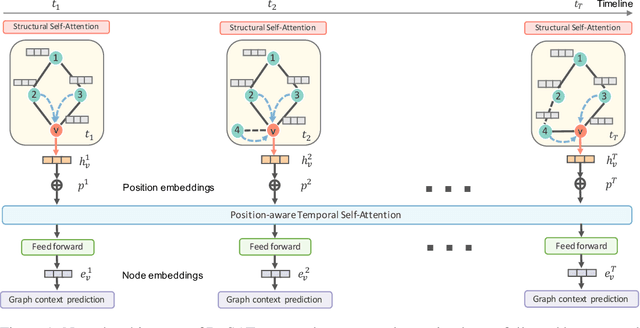
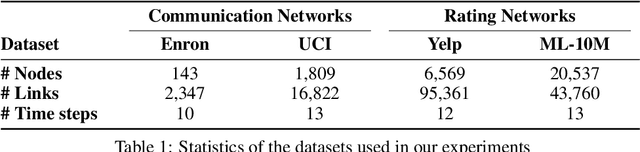
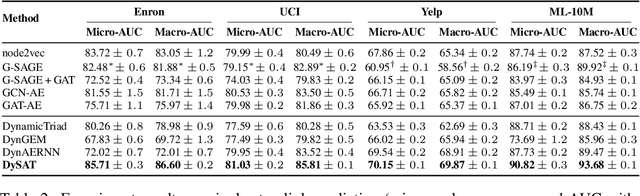

Learning latent representations of nodes in graphs is an important and ubiquitous task with widespread applications such as link prediction, node classification, and graph visualization. Previous methods on graph representation learning mainly focus on static graphs, however, many real-world graphs are dynamic and evolve over time. In this paper, we present Dynamic Self-Attention Network (DySAT), a novel neural architecture that operates on dynamic graphs and learns node representations that capture both structural properties and temporal evolutionary patterns. Specifically, DySAT computes node representations by jointly employing self-attention layers along two dimensions: structural neighborhood and temporal dynamics. We conduct link prediction experiments on two classes of graphs: communication networks and bipartite rating networks. Our experimental results show that DySAT has a significant performance gain over several different state-of-the-art graph embedding baselines.
Solving Pictorial Jigsaw Puzzle by Stigmergy-inspired Internet-based Human Collective Intelligence
Dec 11, 2018
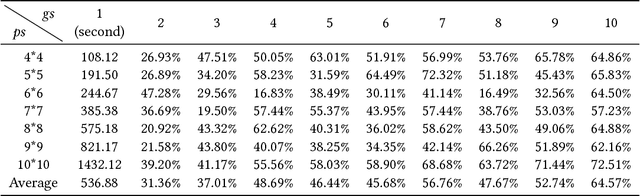
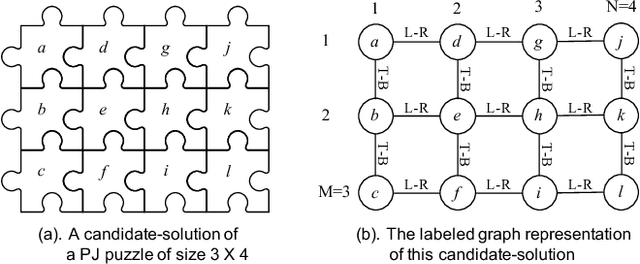
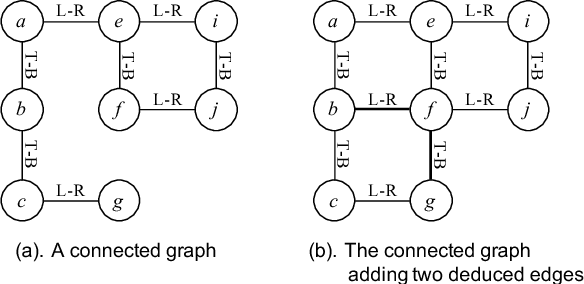
The pictorial jigsaw (PJ) puzzle is a well-known leisure game for humans. Usually, a PJ puzzle game is played by one or several human players face-to-face in the physical space. In this paper, we focus on how to solve PJ puzzles in the cyberspace by a group of physically distributed human players. We propose an approach to solving PJ puzzle by stigmergy-inspired Internet-based human collective intelligence. The core of the approach is a continuously executing loop, named the EIF loop, which consists of three activities: exploration, integration, and feedback. In exploration, each player tries to solve the PJ puzzle alone, without direct interactions with other players. At any time, the result of a player's exploration is a partial solution to the PJ puzzle, and a set of rejected neighboring relation between pieces. The results of all players' exploration are integrated in real time through integration, with the output of a continuously updated collective opinion graph (COG). And through feedback, each player is provided with personalized feedback information based on the current COG and the player's exploration result, in order to accelerate his/her puzzle-solving process. Exploratory experiments show that: (1) supported by this approach, the time to solve PJ puzzle is nearly linear to the reciprocal of the number of players, and shows better scalability to puzzle size than that of face-to-face collaboration for 10-player groups; (2) for groups with 2 to 10 players, the puzzle-solving time decreases 31.36%-64.57% on average, compared with the best single players in the experiments.