 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC3EF: A Joint Self-Correlation and Cross-Correspondence Estimation Framework for Visible and Thermal Image Registration
Apr 17, 2025Multispectral imaging plays a critical role in a range of intelligent transportation applications, including advanced driver assistance systems (ADAS), traffic monitoring, and night vision. However, accurate visible and thermal (RGB-T) image registration poses a significant challenge due to the considerable modality differences. In this paper, we present a novel joint Self-Correlation and Cross-Correspondence Estimation Framework (SC3EF), leveraging both local representative features and global contextual cues to effectively generate RGB-T correspondences. For this purpose, we design a convolution-transformer-based pipeline to extract local representative features and encode global correlations of intra-modality for inter-modality correspondence estimation between unaligned visible and thermal images. After merging the local and global correspondence estimation results, we further employ a hierarchical optical flow estimation decoder to progressively refine the estimated dense correspondence maps. Extensive experiments demonstrate the effectiveness of our proposed method, outperforming the current state-of-the-art (SOTA) methods on representative RGB-T datasets. Furthermore, it also shows competitive generalization capabilities across challenging scenarios, including large parallax, severe occlusions, adverse weather, and other cross-modal datasets (e.g., RGB-N and RGB-D).
Real-Time Super-Resolution System of 4K-Video Based on Deep Learning
Jul 14, 2021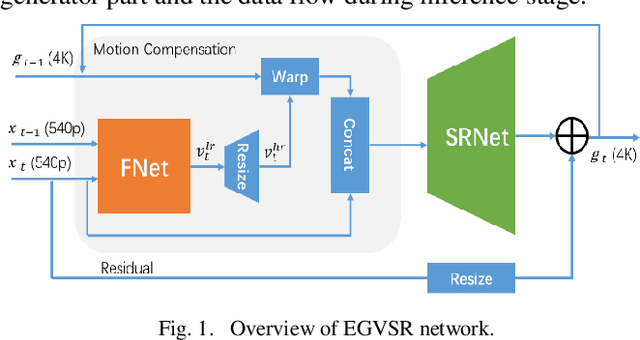
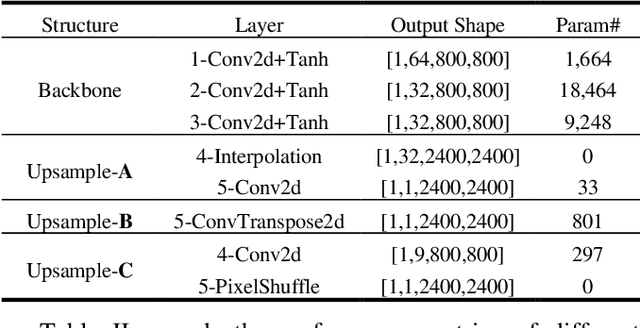
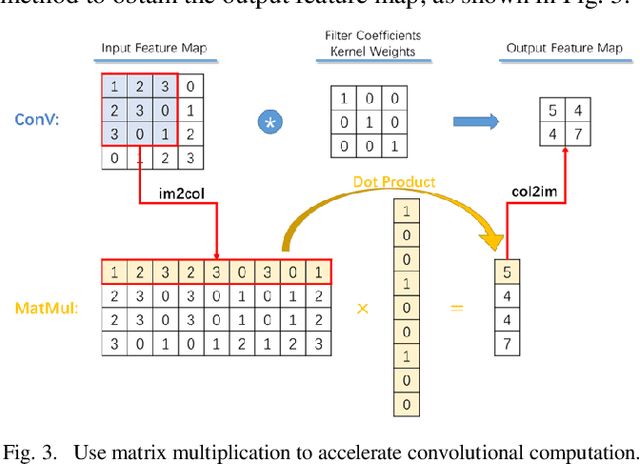

Video super-resolution (VSR) technology excels in reconstructing low-quality video, avoiding unpleasant blur effect caused by interpolation-based algorithms. However, vast computation complexity and memory occupation hampers the edge of deplorability and the runtime inference in real-life applications, especially for large-scale VSR task. This paper explores the possibility of real-time VSR system and designs an efficient and generic VSR network, termed EGVSR. The proposed EGVSR is based on spatio-temporal adversarial learning for temporal coherence. In order to pursue faster VSR processing ability up to 4K resolution, this paper tries to choose lightweight network structure and efficient upsampling method to reduce the computation required by EGVSR network under the guarantee of high visual quality. Besides, we implement the batch normalization computation fusion, convolutional acceleration algorithm and other neural network acceleration techniques on the actual hardware platform to optimize the inference process of EGVSR network. Finally, our EGVSR achieves the real-time processing capacity of 4K@29.61FPS. Compared with TecoGAN, the most advanced VSR network at present, we achieve 85.04% reduction of computation density and 7.92x performance speedups. In terms of visual quality, the proposed EGVSR tops the list of most metrics (such as LPIPS, tOF, tLP, etc.) on the public test dataset Vid4 and surpasses other state-of-the-art methods in overall performance score. The source code of this project can be found on https://github.com/Thmen/EGVSR.
Uncertainty-Aware Unsupervised Domain Adaptation in Object Detection
Feb 27, 2021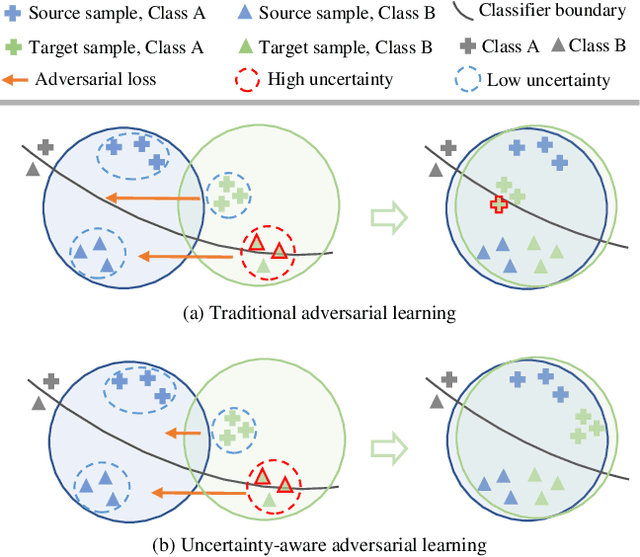
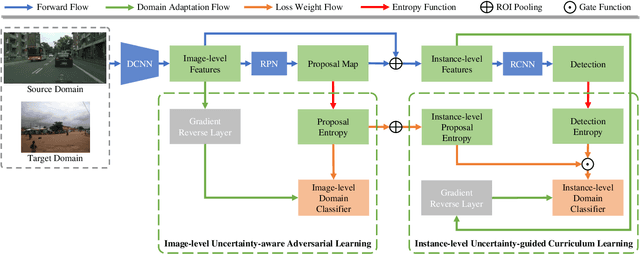

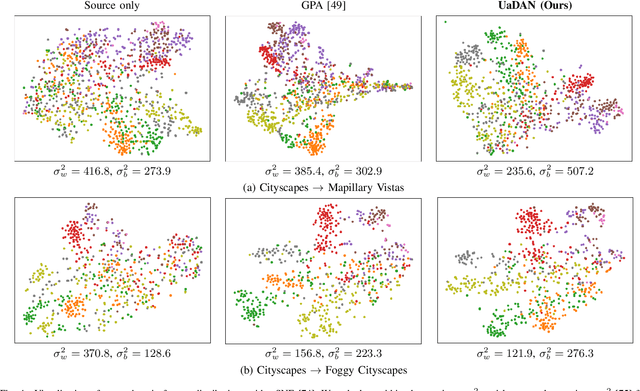
Unsupervised domain adaptive object detection aims to adapt detectors from a labelled source domain to an unlabelled target domain. Most existing works take a two-stage strategy that first generates region proposals and then detects objects of interest, where adversarial learning is widely adopted to mitigate the inter-domain discrepancy in both stages. However, adversarial learning may impair the alignment of well-aligned samples as it merely aligns the global distributions across domains. To address this issue, we design an uncertainty-aware domain adaptation network (UaDAN) that introduces conditional adversarial learning to align well-aligned and poorly-aligned samples separately in different manners. Specifically, we design an uncertainty metric that assesses the alignment of each sample and adjusts the strength of adversarial learning for well-aligned and poorly-aligned samples adaptively. In addition, we exploit the uncertainty metric to achieve curriculum learning that first performs easier image-level alignment and then more difficult instance-level alignment progressively. Extensive experiments over four challenging domain adaptive object detection datasets show that UaDAN achieves superior performance as compared with state-of-the-art methods.
Learning Inter- and Intra-frame Representations for Non-Lambertian Photometric Stereo
Dec 30, 2020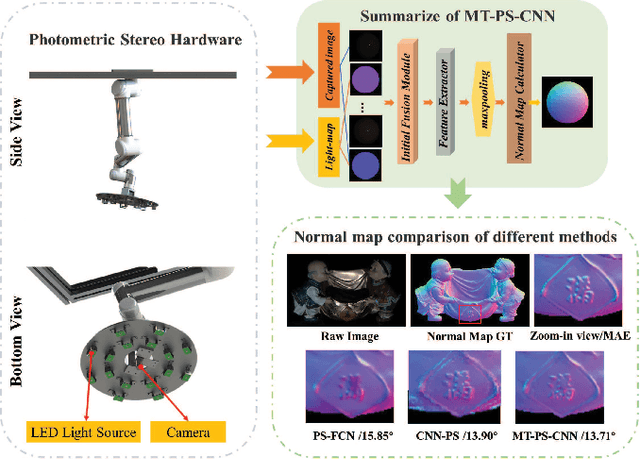

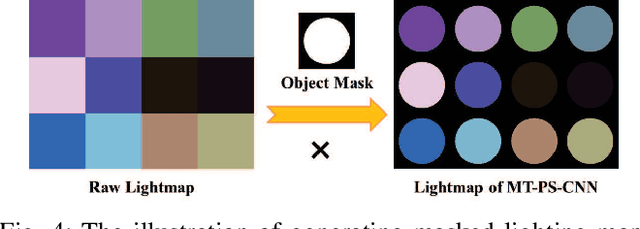
In this paper, we build a two-stage Convolutional Neural Network (CNN) architecture to construct inter- and intra-frame representations based on an arbitrary number of images captured under different light directions, performing accurate normal estimation of non-Lambertian objects. We experimentally investigate numerous network design alternatives for identifying the optimal scheme to deploy inter-frame and intra-frame feature extraction modules for the photometric stereo problem. Moreover, we propose to utilize the easily obtained object mask for eliminating adverse interference from invalid background regions in intra-frame spatial convolutions, thus effectively improve the accuracy of normal estimation for surfaces made of dark materials or with cast shadows. Experimental results demonstrate that proposed masked two-stage photometric stereo CNN model (MT-PS-CNN) performs favorably against state-of-the-art photometric stereo techniques in terms of both accuracy and efficiency. In addition, the proposed method is capable of predicting accurate and rich surface normal details for non-Lambertian objects of complex geometry and performs stably given inputs captured in both sparse and dense lighting distributions.
LGENet: Local and Global Encoder Network for Semantic Segmentation of Airborne Laser Scanning Point Clouds
Dec 18, 2020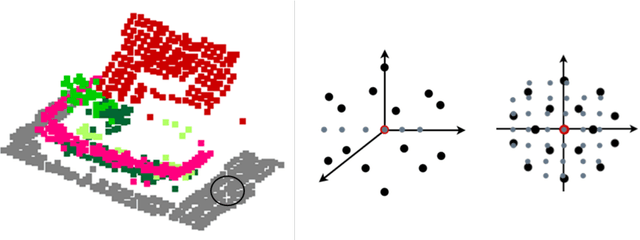

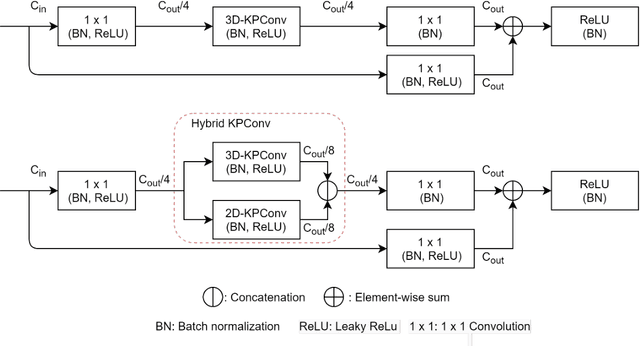
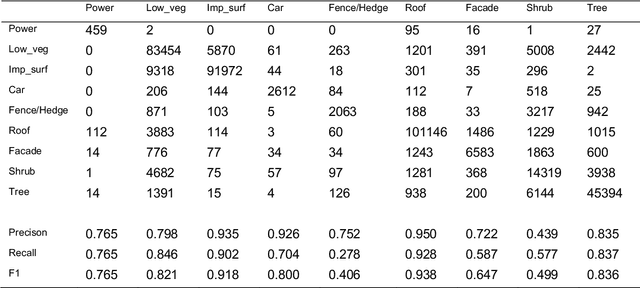
Interpretation of Airborne Laser Scanning (ALS) point clouds is a critical procedure for producing various geo-information products like 3D city models, digital terrain models and land use maps. In this paper, we present a local and global encoder network (LGENet) for semantic segmentation of ALS point clouds. Adapting the KPConv network, we first extract features by both 2D and 3D point convolutions to allow the network to learn more representative local geometry. Then global encoders are used in the network to exploit contextual information at the object and point level. We design a segment-based Edge Conditioned Convolution to encode the global context between segments. We apply a spatial-channel attention module at the end of the network, which not only captures the global interdependencies between points but also models interactions between channels. We evaluate our method on two ALS datasets namely, the ISPRS benchmark dataset and DCF2019 dataset. For the ISPRS benchmark dataset, our model achieves state-of-the-art results with an overall accuracy of 0.845 and an average F1 score of 0.737. With regards to the DFC2019 dataset, our proposed network achieves an overall accuracy of 0.984 and an average F1 score of 0.834.
Boosting Image Super-Resolution Via Fusion of Complementary Information Captured by Multi-Modal Sensors
Dec 07, 2020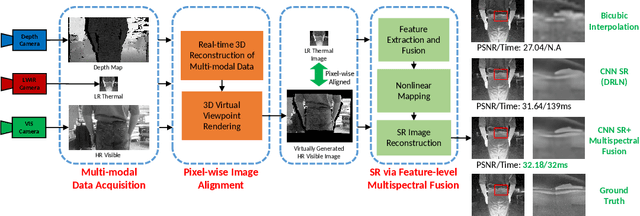

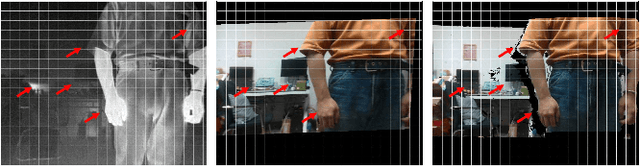
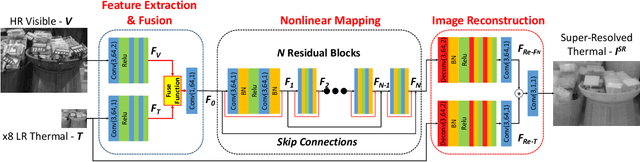
Image Super-Resolution (SR) provides a promising technique to enhance the image quality of low-resolution optical sensors, facilitating better-performing target detection and autonomous navigation in a wide range of robotics applications. It is noted that the state-of-the-art SR methods are typically trained and tested using single-channel inputs, neglecting the fact that the cost of capturing high-resolution images in different spectral domains varies significantly. In this paper, we attempt to leverage complementary information from a low-cost channel (visible/depth) to boost image quality of an expensive channel (thermal) using fewer parameters. To this end, we first present an effective method to virtually generate pixel-wise aligned visible and thermal images based on real-time 3D reconstruction of multi-modal data captured at various viewpoints. Then, we design a feature-level multispectral fusion residual network model to perform high-accuracy SR of thermal images by adaptively integrating co-occurrence features presented in multispectral images. Experimental results demonstrate that this new approach can effectively alleviate the ill-posed inverse problem of image SR by taking into account complementary information from an additional low-cost channel, significantly outperforming state-of-the-art SR approaches in terms of both accuracy and efficiency.
Few-Shot Defect Segmentation Leveraging Abundant Normal Training Samples Through Normal Background Regularization and Crop-and-Paste Operation
Jul 18, 2020
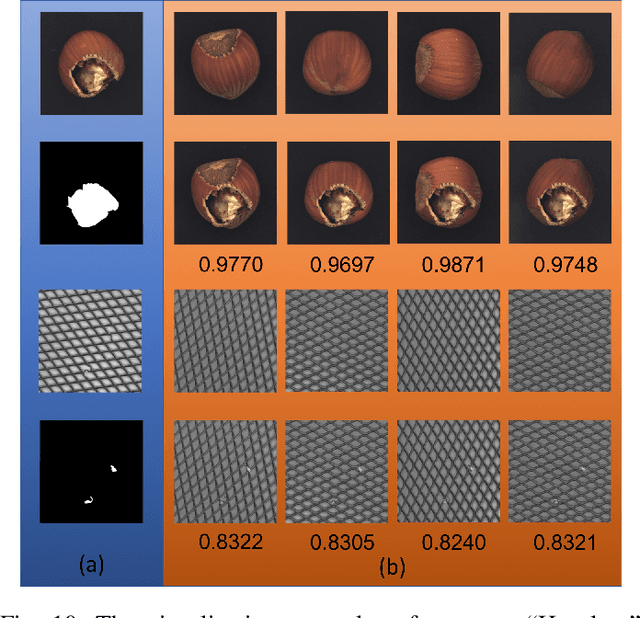
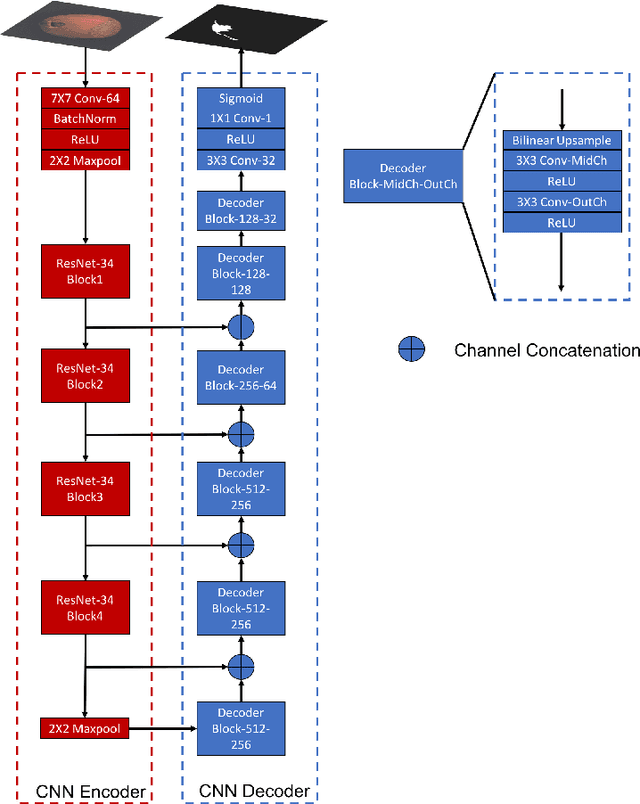
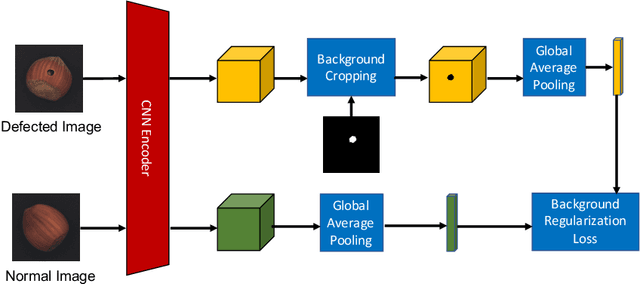
In industrial product quality assessment, it is essential to determine whether a product is defect-free and further analyze the severity of anomality. To this end, accurate defect segmentation on images of products provides an important functionality. In industrial inspection tasks, it is common to capture abundant defect-free image samples but very limited anomalous ones. Therefore, it is critical to develop automatic and accurate defect segmentation systems using only a small number of annotated anomalous training images. This paper tackles the challenging few-shot defect segmentation task with sufficient normal (defect-free) training images but very few anomalous ones. We present two effective regularization techniques via incorporating abundant defect-free images into the training of a UNet-like encoder-decoder defect segmentation network. We first propose a Normal Background Regularization (NBR) loss which is jointly minimized with the segmentation loss, enhancing the encoder network to produce distinctive representations for normal regions. Secondly, we crop/paste defective regions to the randomly selected normal images for data augmentation and propose a weighted binary cross-entropy loss to enhance the training by emphasizing more realistic crop-and-pasted augmented images based on feature-level similarity comparison. Both techniques are implemented on an encoder-decoder segmentation network backboned by ResNet-34 for few-shot defect segmentation. Extensive experiments are conducted on the recently released MVTec Anomaly Detection dataset with high-resolution industrial images. Under both 1-shot and 5-shot defect segmentation settings, the proposed method significantly outperforms several benchmarking methods.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020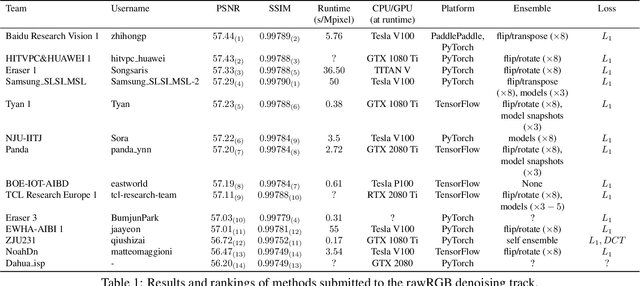
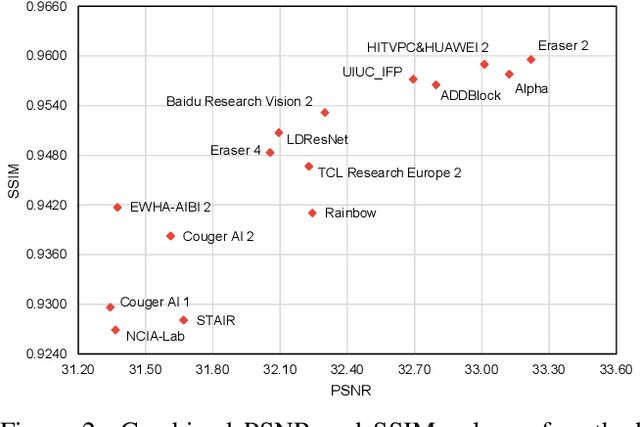
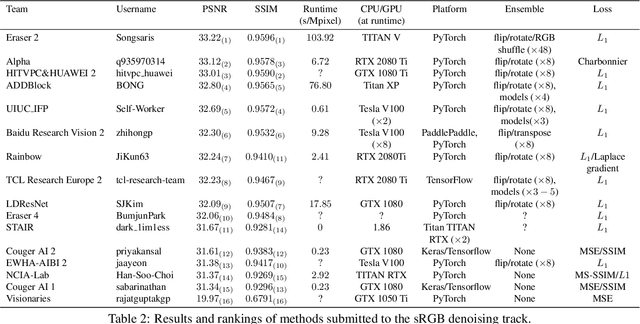
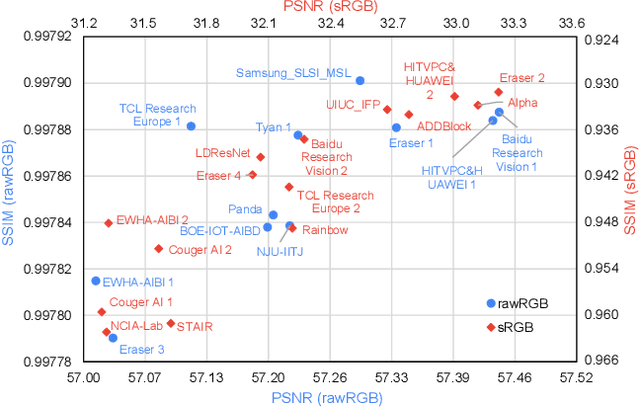
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Deep Neural Network for Fast and Accurate Single Image Super-Resolution via Channel-Attention-based Fusion of Orientation-aware Features
Dec 09, 2019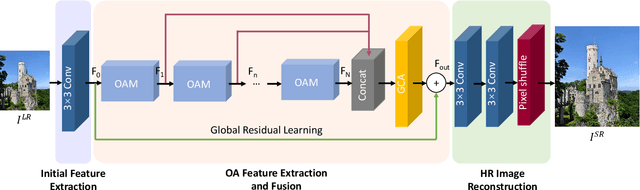


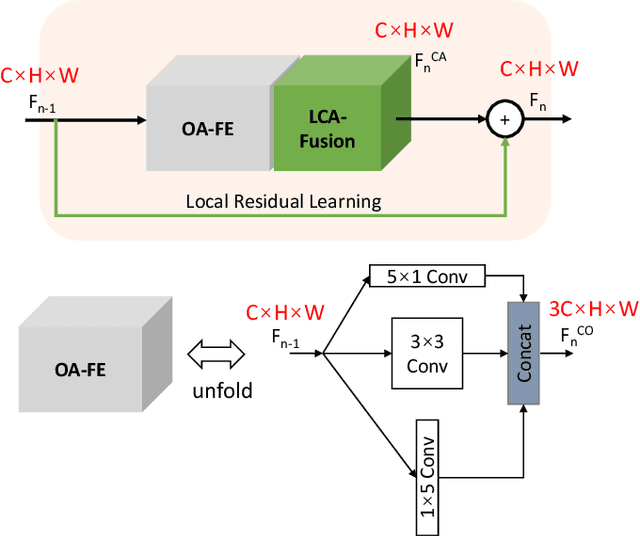
Recently, Convolutional Neural Networks (CNNs) have been successfully adopted to solve the ill-posed single image super-resolution (SISR) problem. A commonly used strategy to boost the performance of CNN-based SISR models is deploying very deep networks, which inevitably incurs many obvious drawbacks (e.g., a large number of network parameters, heavy computational loads, and difficult model training). In this paper, we aim to build more accurate and faster SISR models via developing better-performing feature extraction and fusion techniques. Firstly, we proposed a novel Orientation-Aware feature extraction and fusion Module (OAM), which contains a mixture of 1D and 2D convolutional kernels (i.e., 5 x 1, 1 x 5, and 3 x 3) for extracting orientation-aware features. Secondly, we adopt the channel attention mechanism as an effective technique to adaptively fuse features extracted in different directions and in hierarchically stacked convolutional stages. Based on these two important improvements, we present a compact but powerful CNN-based model for high-quality SISR via Channel Attention-based fusion of Orientation-Aware features (SISR-CA-OA). Extensive experimental results verify the superiority of the proposed SISR-CA-OA model, performing favorably against the state-of-the-art SISR models in terms of both restoration accuracy and computational efficiency. The source codes will be made publicly available.
Unsupervised Domain Adaptation for Multispectral Pedestrian Detection
Apr 07, 2019
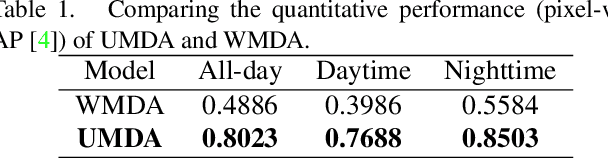
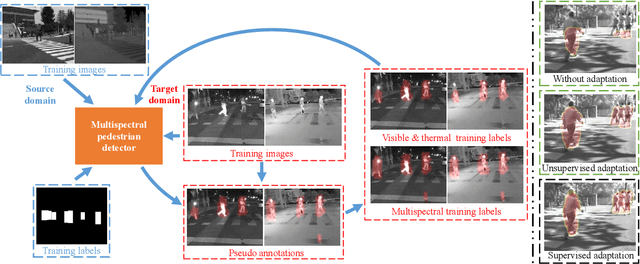

Multimodal information (e.g., visible and thermal) can generate robust pedestrian detections to facilitate around-the-clock computer vision applications, such as autonomous driving and video surveillance. However, it still remains a crucial challenge to train a reliable detector working well in different multispectral pedestrian datasets without manual annotations. In this paper, we propose a novel unsupervised domain adaptation framework for multispectral pedestrian detection, by iteratively generating pseudo annotations and updating the parameters of our designed multispectral pedestrian detector on target domain. Pseudo annotations are generated using the detector trained on source domain, and then updated by fixing the parameters of detector and minimizing the cross entropy loss without back-propagation. Training labels are generated using the pseudo annotations by considering the characteristics of similarity and complementarity between well-aligned visible and infrared image pairs. The parameters of detector are updated using the generated labels by minimizing our defined multi-detection loss function with back-propagation. The optimal parameters of detector can be obtained after iteratively updating the pseudo annotations and parameters. Experimental results show that our proposed unsupervised multimodal domain adaptation method achieves significantly higher detection performance than the approach without domain adaptation, and is competitive with the supervised multispectral pedestrian detectors.