 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeedance 2.0: Advancing Video Generation for World Complexity
Apr 15, 2026Seedance 2.0 is a new native multi-modal audio-video generation model, officially released in China in early February 2026. Compared with its predecessors, Seedance 1.0 and 1.5 Pro, Seedance 2.0 adopts a unified, highly efficient, and large-scale architecture for multi-modal audio-video joint generation. This allows it to support four input modalities: text, image, audio, and video, by integrating one of the most comprehensive suites of multi-modal content reference and editing capabilities available in the industry to date. It delivers substantial, well-rounded improvements across all key sub-dimensions of video and audio generation. In both expert evaluations and public user tests, the model has demonstrated performance on par with the leading levels in the field. Seedance 2.0 supports direct generation of audio-video content with durations ranging from 4 to 15 seconds, with native output resolutions of 480p and 720p. For multi-modal inputs as reference, its current open platform supports up to 3 video clips, 9 images, and 3 audio clips. In addition, we provide Seedance 2.0 Fast version, an accelerated variant of Seedance 2.0 designed to boost generation speed for low-latency scenarios. Seedance 2.0 has delivered significant improvements to its foundational generation capabilities and multi-modal generation performance, bringing an enhanced creative experience for end users.
ReSyncer: Rewiring Style-based Generator for Unified Audio-Visually Synced Facial Performer
Aug 06, 2024



Lip-syncing videos with given audio is the foundation for various applications including the creation of virtual presenters or performers. While recent studies explore high-fidelity lip-sync with different techniques, their task-orientated models either require long-term videos for clip-specific training or retain visible artifacts. In this paper, we propose a unified and effective framework ReSyncer, that synchronizes generalized audio-visual facial information. The key design is revisiting and rewiring the Style-based generator to efficiently adopt 3D facial dynamics predicted by a principled style-injected Transformer. By simply re-configuring the information insertion mechanisms within the noise and style space, our framework fuses motion and appearance with unified training. Extensive experiments demonstrate that ReSyncer not only produces high-fidelity lip-synced videos according to audio, but also supports multiple appealing properties that are suitable for creating virtual presenters and performers, including fast personalized fine-tuning, video-driven lip-syncing, the transfer of speaking styles, and even face swapping. Resources can be found at https://guanjz20.github.io/projects/ReSyncer.
GIR: 3D Gaussian Inverse Rendering for Relightable Scene Factorization
Dec 08, 2023



This paper presents GIR, a 3D Gaussian Inverse Rendering method for relightable scene factorization. Compared to existing methods leveraging discrete meshes or neural implicit fields for inverse rendering, our method utilizes 3D Gaussians to estimate the material properties, illumination, and geometry of an object from multi-view images. Our study is motivated by the evidence showing that 3D Gaussian is a more promising backbone than neural fields in terms of performance, versatility, and efficiency. In this paper, we aim to answer the question: ``How can 3D Gaussian be applied to improve the performance of inverse rendering?'' To address the complexity of estimating normals based on discrete and often in-homogeneous distributed 3D Gaussian representations, we proposed an efficient self-regularization method that facilitates the modeling of surface normals without the need for additional supervision. To reconstruct indirect illumination, we propose an approach that simulates ray tracing. Extensive experiments demonstrate our proposed GIR's superior performance over existing methods across multiple tasks on a variety of widely used datasets in inverse rendering. This substantiates its efficacy and broad applicability, highlighting its potential as an influential tool in relighting and reconstruction. Project page: https://3dgir.github.io
Accelerating Vision Transformers Based on Heterogeneous Attention Patterns
Oct 11, 2023



Recently, Vision Transformers (ViTs) have attracted a lot of attention in the field of computer vision. Generally, the powerful representative capacity of ViTs mainly benefits from the self-attention mechanism, which has a high computation complexity. To accelerate ViTs, we propose an integrated compression pipeline based on observed heterogeneous attention patterns across layers. On one hand, different images share more similar attention patterns in early layers than later layers, indicating that the dynamic query-by-key self-attention matrix may be replaced with a static self-attention matrix in early layers. Then, we propose a dynamic-guided static self-attention (DGSSA) method where the matrix inherits self-attention information from the replaced dynamic self-attention to effectively improve the feature representation ability of ViTs. On the other hand, the attention maps have more low-rank patterns, which reflect token redundancy, in later layers than early layers. In a view of linear dimension reduction, we further propose a method of global aggregation pyramid (GLAD) to reduce the number of tokens in later layers of ViTs, such as Deit. Experimentally, the integrated compression pipeline of DGSSA and GLAD can accelerate up to 121% run-time throughput compared with DeiT, which surpasses all SOTA approaches.
HD-Fusion: Detailed Text-to-3D Generation Leveraging Multiple Noise Estimation
Jul 30, 2023



In this paper, we study Text-to-3D content generation leveraging 2D diffusion priors to enhance the quality and detail of the generated 3D models. Recent progress (Magic3D) in text-to-3D has shown that employing high-resolution (e.g., 512 x 512) renderings can lead to the production of high-quality 3D models using latent diffusion priors. To enable rendering at even higher resolutions, which has the potential to further augment the quality and detail of the models, we propose a novel approach that combines multiple noise estimation processes with a pretrained 2D diffusion prior. Distinct from the Bar-Tal et al.s' study which binds multiple denoised results to generate images from texts, our approach integrates the computation of scoring distillation losses such as SDS loss and VSD loss which are essential techniques for the 3D content generation with 2D diffusion priors. We experimentally evaluated the proposed approach. The results show that the proposed approach can generate high-quality details compared to the baselines.
StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator
May 09, 2023



Despite recent advances in syncing lip movements with any audio waves, current methods still struggle to balance generation quality and the model's generalization ability. Previous studies either require long-term data for training or produce a similar movement pattern on all subjects with low quality. In this paper, we propose StyleSync, an effective framework that enables high-fidelity lip synchronization. We identify that a style-based generator would sufficiently enable such a charming property on both one-shot and few-shot scenarios. Specifically, we design a mask-guided spatial information encoding module that preserves the details of the given face. The mouth shapes are accurately modified by audio through modulated convolutions. Moreover, our design also enables personalized lip-sync by introducing style space and generator refinement on only limited frames. Thus the identity and talking style of a target person could be accurately preserved. Extensive experiments demonstrate the effectiveness of our method in producing high-fidelity results on a variety of scenes. Resources can be found at https://hangz-nju-cuhk.github.io/projects/StyleSync.
Make Your Brief Stroke Real and Stereoscopic: 3D-Aware Simplified Sketch to Portrait Generation
Feb 14, 2023



Creating the photo-realistic version of people sketched portraits is useful to various entertainment purposes. Existing studies only generate portraits in the 2D plane with fixed views, making the results less vivid. In this paper, we present Stereoscopic Simplified Sketch-to-Portrait (SSSP), which explores the possibility of creating Stereoscopic 3D-aware portraits from simple contour sketches by involving 3D generative models. Our key insight is to design sketch-aware constraints that can fully exploit the prior knowledge of a tri-plane-based 3D-aware generative model. Specifically, our designed region-aware volume rendering strategy and global consistency constraint further enhance detail correspondences during sketch encoding. Moreover, in order to facilitate the usage of layman users, we propose a Contour-to-Sketch module with vector quantized representations, so that easily drawn contours can directly guide the generation of 3D portraits. Extensive comparisons show that our method generates high-quality results that match the sketch. Our usability study verifies that our system is greatly preferred by user.
Masked Lip-Sync Prediction by Audio-Visual Contextual Exploitation in Transformers
Dec 09, 2022



Previous studies have explored generating accurately lip-synced talking faces for arbitrary targets given audio conditions. However, most of them deform or generate the whole facial area, leading to non-realistic results. In this work, we delve into the formulation of altering only the mouth shapes of the target person. This requires masking a large percentage of the original image and seamlessly inpainting it with the aid of audio and reference frames. To this end, we propose the Audio-Visual Context-Aware Transformer (AV-CAT) framework, which produces accurate lip-sync with photo-realistic quality by predicting the masked mouth shapes. Our key insight is to exploit desired contextual information provided in audio and visual modalities thoroughly with delicately designed Transformers. Specifically, we propose a convolution-Transformer hybrid backbone and design an attention-based fusion strategy for filling the masked parts. It uniformly attends to the textural information on the unmasked regions and the reference frame. Then the semantic audio information is involved in enhancing the self-attention computation. Additionally, a refinement network with audio injection improves both image and lip-sync quality. Extensive experiments validate that our model can generate high-fidelity lip-synced results for arbitrary subjects.
Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition
Nov 22, 2022



While dynamic Neural Radiance Fields (NeRF) have shown success in high-fidelity 3D modeling of talking portraits, the slow training and inference speed severely obstruct their potential usage. In this paper, we propose an efficient NeRF-based framework that enables real-time synthesizing of talking portraits and faster convergence by leveraging the recent success of grid-based NeRF. Our key insight is to decompose the inherently high-dimensional talking portrait representation into three low-dimensional feature grids. Specifically, a Decomposed Audio-spatial Encoding Module models the dynamic head with a 3D spatial grid and a 2D audio grid. The torso is handled with another 2D grid in a lightweight Pseudo-3D Deformable Module. Both modules focus on efficiency under the premise of good rendering quality. Extensive experiments demonstrate that our method can generate realistic and audio-lips synchronized talking portrait videos, while also being highly efficient compared to previous methods.
StyleSwap: Style-Based Generator Empowers Robust Face Swapping
Sep 27, 2022
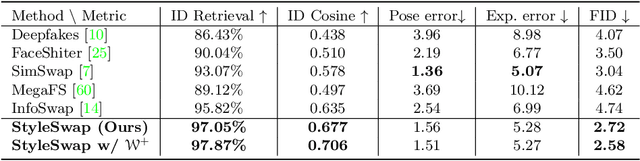
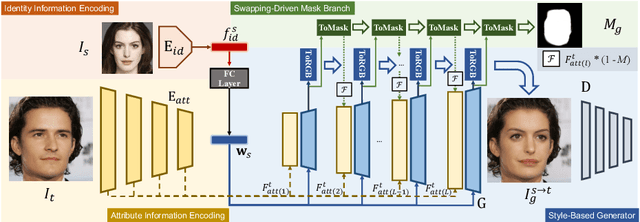

Numerous attempts have been made to the task of person-agnostic face swapping given its wide applications. While existing methods mostly rely on tedious network and loss designs, they still struggle in the information balancing between the source and target faces, and tend to produce visible artifacts. In this work, we introduce a concise and effective framework named StyleSwap. Our core idea is to leverage a style-based generator to empower high-fidelity and robust face swapping, thus the generator's advantage can be adopted for optimizing identity similarity. We identify that with only minimal modifications, a StyleGAN2 architecture can successfully handle the desired information from both source and target. Additionally, inspired by the ToRGB layers, a Swapping-Driven Mask Branch is further devised to improve information blending. Furthermore, the advantage of StyleGAN inversion can be adopted. Particularly, a Swapping-Guided ID Inversion strategy is proposed to optimize identity similarity. Extensive experiments validate that our framework generates high-quality face swapping results that outperform state-of-the-art methods both qualitatively and quantitatively.