 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022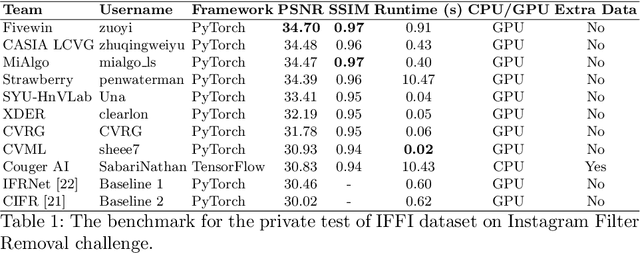

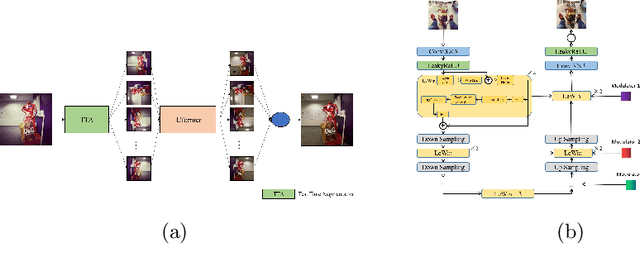
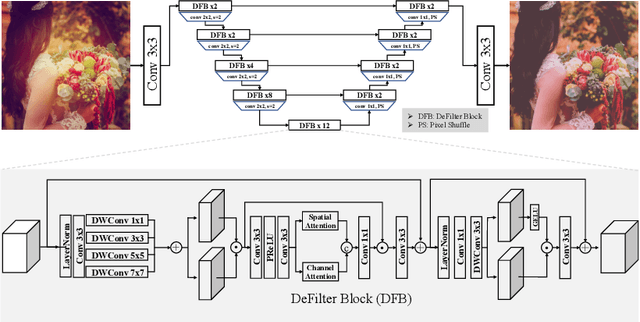
This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.
Lesion Net -- Skin Lesion Segmentation Using Coordinate Convolution and Deep Residual Units
Dec 28, 2020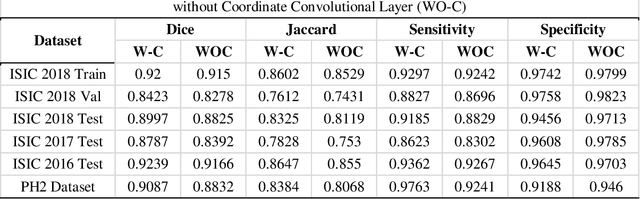
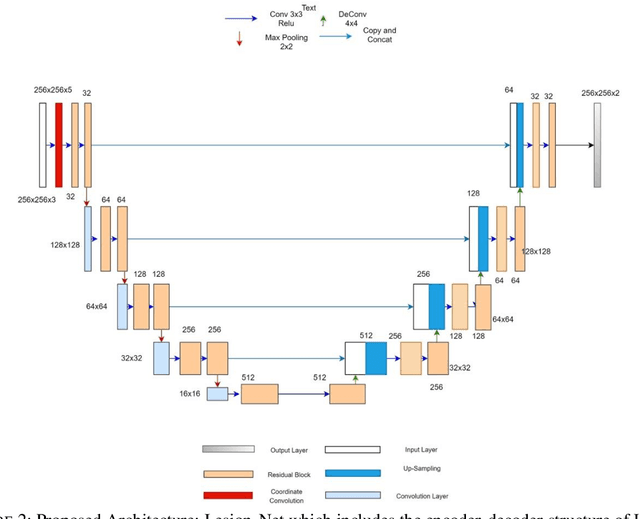
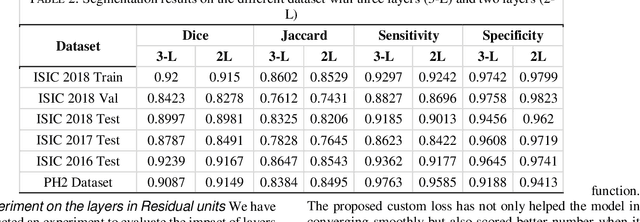
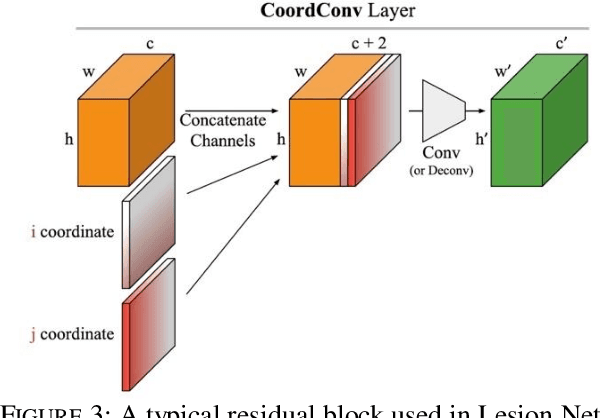
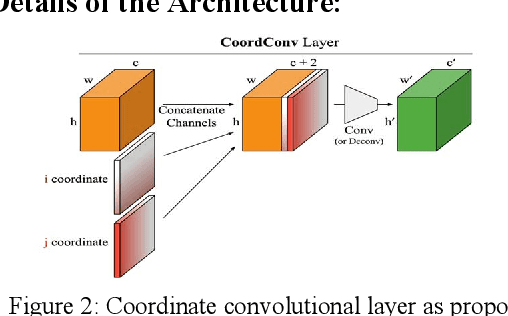
Skin lesions segmentation is an important step in the process of automated diagnosis of the skin melanoma. However, the accuracy of segmenting melanomas skin lesions is quite a challenging task due to less data for training, irregular shapes, unclear boundaries, and different skin colors. Our proposed approach helps in improving the accuracy of skin lesion segmentation. Firstly, we have introduced the coordinate convolutional layer before passing the input image into the encoder. This layer helps the network to decide on the features related to translation invariance which further improves the generalization capacity of the model. Secondly, we have leveraged the properties of deep residual units along with the convolutional layers. At last, instead of using only cross-entropy or Dice-loss, we have combined the two-loss functions to optimize the training metrics which helps in converging the loss more quickly and smoothly. After training and validating the proposed model on ISIC 2018 (60% as train set + 20% as validation set), we tested the robustness of our trained model on various other datasets like ISIC 2018 (20% as test-set) ISIC 2017, 2016 and PH2 dataset. The results show that the proposed model either outperform or at par with the existing skin lesion segmentation methods.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020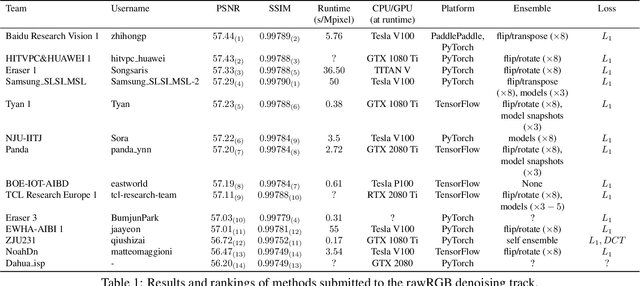
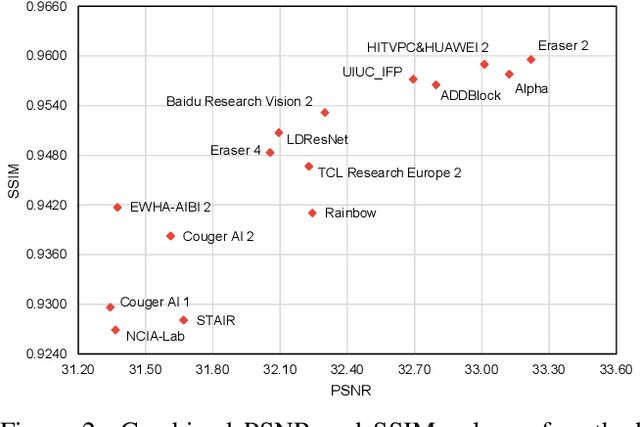
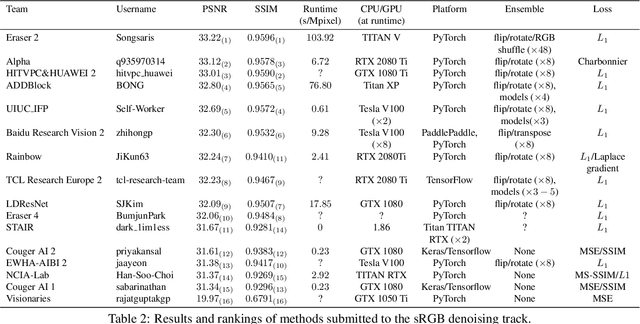
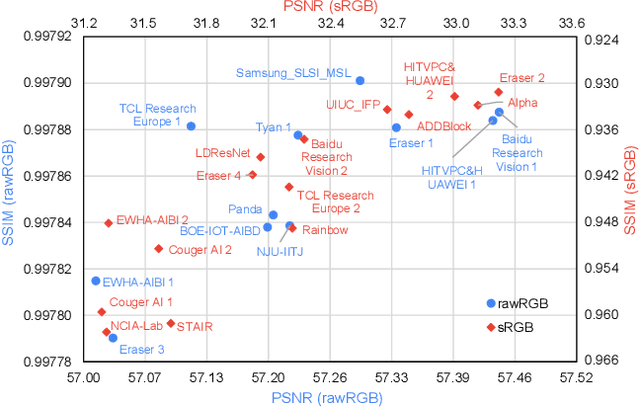
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Eyenet: Attention based Convolutional Encoder-Decoder Network for Eye Region Segmentation
Oct 08, 2019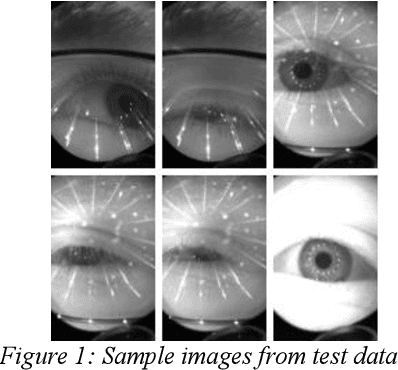
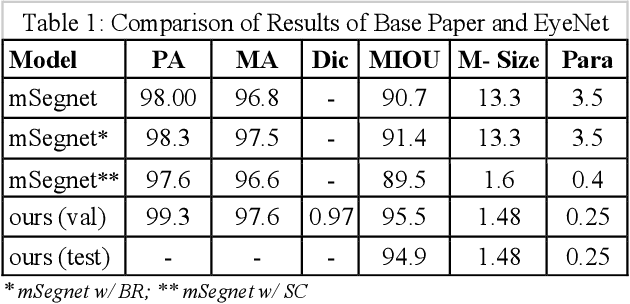
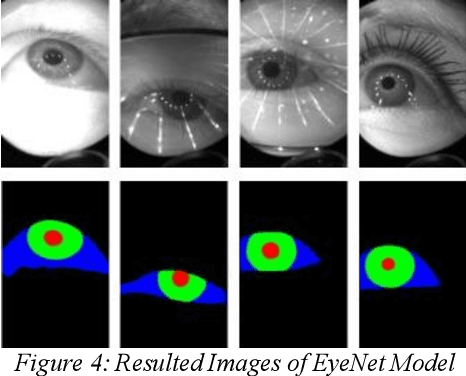
With the immersive development in the field of augmented and virtual reality, accurate and speedy eye-tracking is required. Facebook Research has organized a challenge, named OpenEDS Semantic Segmentation challenge for per-pixel segmentation of the key eye regions: the sclera, the iris, the pupil, and everything else (background). There are two constraints set for the participants viz MIOU and the computational complexity of the model. More recently, researchers have achieved quite a good result using the convolutional neural networks (CNN) in segmenting eyeregions. However, the environmental challenges involved in this task such as low resolution, blur, unusual glint and, illumination, off-angles, off-axis, use of glasses and different color of iris region hinder the accuracy of segmentation. To address the challenges in eye segmentation, the present work proposes a robust and computationally efficient attention-based convolutional encoder-decoder network for segmenting all the eye regions. Our model, named EyeNet, includes modified residual units as the backbone, two types of attention blocks and multi-scale supervision for segmenting the aforesaid four eye regions. Our proposed model achieved a total score of 0.974(EDS Evaluation metric) on test data, which demonstrates superior results compared to the baseline methods.
SkeletonNet: Shape Pixel to Skeleton Pixel
Jul 02, 2019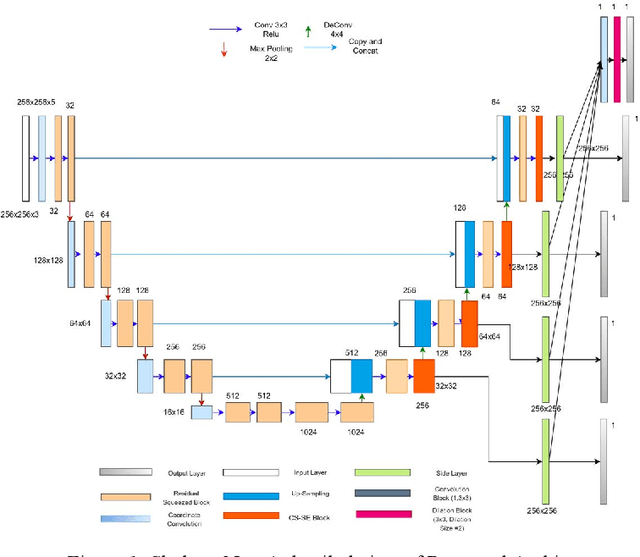
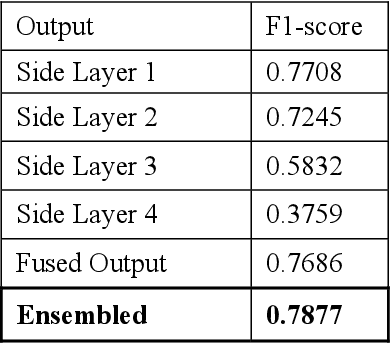
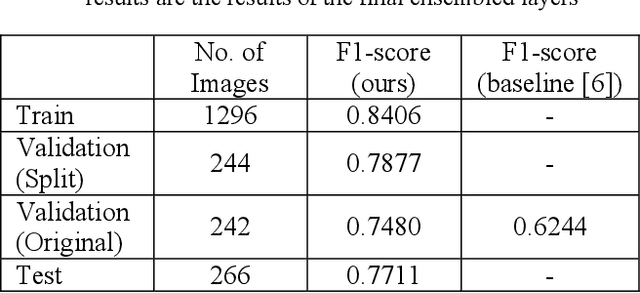
Deep Learning for Geometric Shape Understating has organized a challenge for extracting different kinds of skeletons from the images of different objects. This competition is organized in association with CVPR 2019. There are three different tracks of this competition. The present manuscript describes the method used to train the model for the dataset provided in the first track. The first track aims to extract skeleton pixels from the shape pixels of 89 different objects. For the purpose of extracting the skeleton, a U-net model which is comprised of an encoder-decoder structure has been used. In our proposed architecture, unlike the plain decoder in the traditional Unet, we have designed the decoder in the format of HED architecture, wherein we have introduced 4 side layers and fused them to one dilation convolutional layer to connect the broken links of the skeleton. Our proposed architecture achieved the F1 score of 0.77 on test data.
* Published in CVPRw 2019