 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
An objective validation of polyp and instrument segmentation methods in colonoscopy through Medico 2020 polyp segmentation and MedAI 2021 transparency challenges
Jul 30, 2023



Automatic analysis of colonoscopy images has been an active field of research motivated by the importance of early detection of precancerous polyps. However, detecting polyps during the live examination can be challenging due to various factors such as variation of skills and experience among the endoscopists, lack of attentiveness, and fatigue leading to a high polyp miss-rate. Deep learning has emerged as a promising solution to this challenge as it can assist endoscopists in detecting and classifying overlooked polyps and abnormalities in real time. In addition to the algorithm's accuracy, transparency and interpretability are crucial to explaining the whys and hows of the algorithm's prediction. Further, most algorithms are developed in private data, closed source, or proprietary software, and methods lack reproducibility. Therefore, to promote the development of efficient and transparent methods, we have organized the "Medico automatic polyp segmentation (Medico 2020)" and "MedAI: Transparency in Medical Image Segmentation (MedAI 2021)" competitions. We present a comprehensive summary and analyze each contribution, highlight the strength of the best-performing methods, and discuss the possibility of clinical translations of such methods into the clinic. For the transparency task, a multi-disciplinary team, including expert gastroenterologists, accessed each submission and evaluated the team based on open-source practices, failure case analysis, ablation studies, usability and understandability of evaluations to gain a deeper understanding of the models' credibility for clinical deployment. Through the comprehensive analysis of the challenge, we not only highlight the advancements in polyp and surgical instrument segmentation but also encourage qualitative evaluation for building more transparent and understandable AI-based colonoscopy systems.
Real-Time Under-Display Cameras Image Restoration and HDR on Mobile Devices
Nov 25, 2022The new trend of full-screen devices implies positioning the camera behind the screen to bring a larger display-to-body ratio, enhance eye contact, and provide a notch-free viewing experience on smartphones, TV or tablets. On the other hand, the images captured by under-display cameras (UDCs) are degraded by the screen in front of them. Deep learning methods for image restoration can significantly reduce the degradation of captured images, providing satisfying results for the human eyes. However, most proposed solutions are unreliable or efficient enough to be used in real-time on mobile devices. In this paper, we aim to solve this image restoration problem using efficient deep learning methods capable of processing FHD images in real-time on commercial smartphones while providing high-quality results. We propose a lightweight model for blind UDC Image Restoration and HDR, and we also provide a benchmark comparing the performance and runtime of different methods on smartphones. Our models are competitive on UDC benchmarks while using x4 less operations than others. To the best of our knowledge, we are the first work to approach and analyze this real-world single image restoration problem from the efficiency and production point of view.
AIM 2022 Challenge on Instagram Filter Removal: Methods and Results
Oct 17, 2022

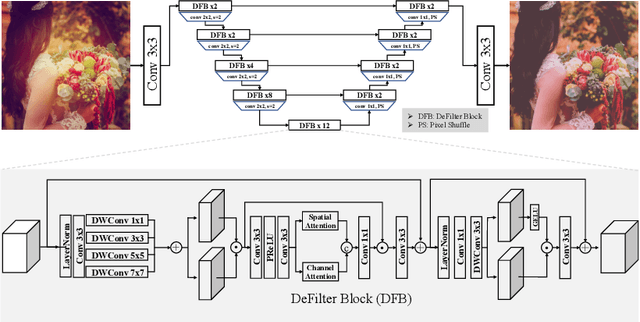
This paper introduces the methods and the results of AIM 2022 challenge on Instagram Filter Removal. Social media filters transform the images by consecutive non-linear operations, and the feature maps of the original content may be interpolated into a different domain. This reduces the overall performance of the recent deep learning strategies. The main goal of this challenge is to produce realistic and visually plausible images where the impact of the filters applied is mitigated while preserving the content. The proposed solutions are ranked in terms of the PSNR value with respect to the original images. There are two prior studies on this task as the baseline, and a total of 9 teams have competed in the final phase of the challenge. The comparison of qualitative results of the proposed solutions and the benchmark for the challenge are presented in this report.
Lesion Net -- Skin Lesion Segmentation Using Coordinate Convolution and Deep Residual Units
Dec 28, 2020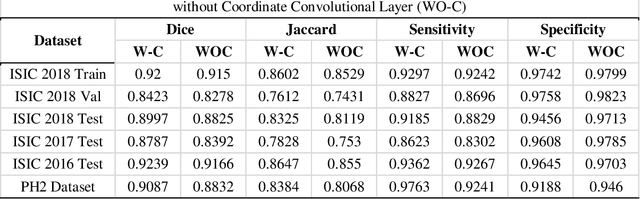
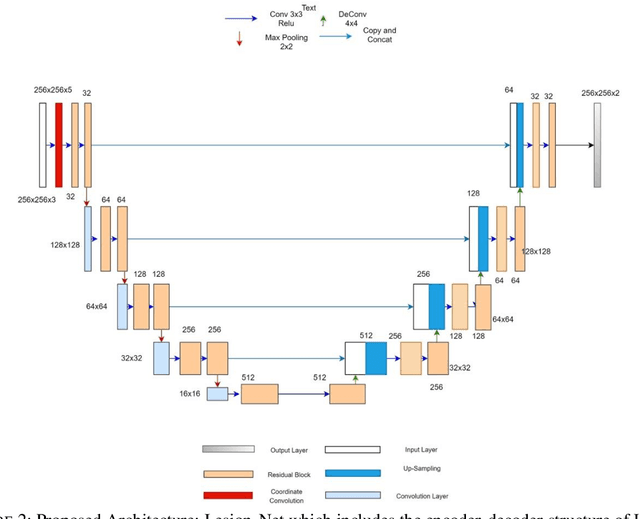
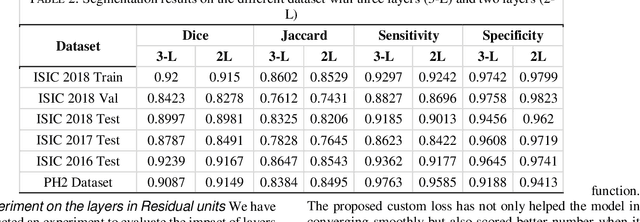
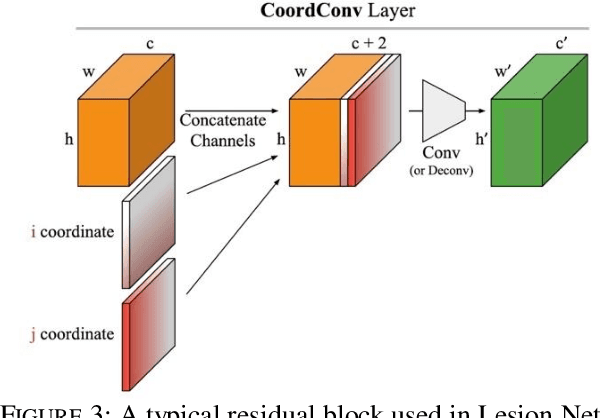
Skin lesions segmentation is an important step in the process of automated diagnosis of the skin melanoma. However, the accuracy of segmenting melanomas skin lesions is quite a challenging task due to less data for training, irregular shapes, unclear boundaries, and different skin colors. Our proposed approach helps in improving the accuracy of skin lesion segmentation. Firstly, we have introduced the coordinate convolutional layer before passing the input image into the encoder. This layer helps the network to decide on the features related to translation invariance which further improves the generalization capacity of the model. Secondly, we have leveraged the properties of deep residual units along with the convolutional layers. At last, instead of using only cross-entropy or Dice-loss, we have combined the two-loss functions to optimize the training metrics which helps in converging the loss more quickly and smoothly. After training and validating the proposed model on ISIC 2018 (60% as train set + 20% as validation set), we tested the robustness of our trained model on various other datasets like ISIC 2018 (20% as test-set) ISIC 2017, 2016 and PH2 dataset. The results show that the proposed model either outperform or at par with the existing skin lesion segmentation methods.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020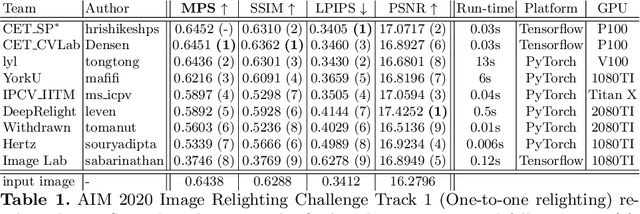

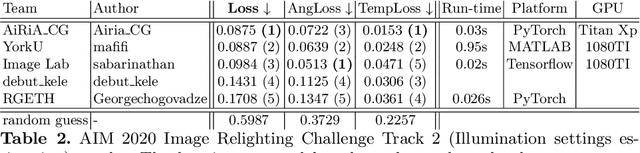

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
UDC 2020 Challenge on Image Restoration of Under-Display Camera: Methods and Results
Aug 18, 2020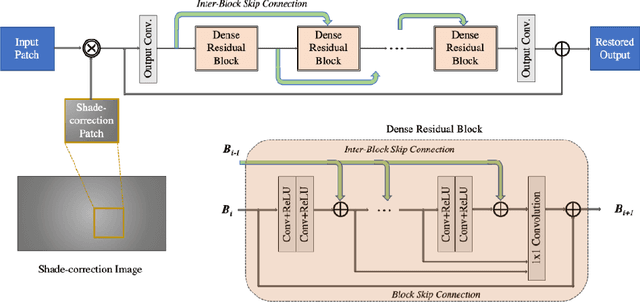
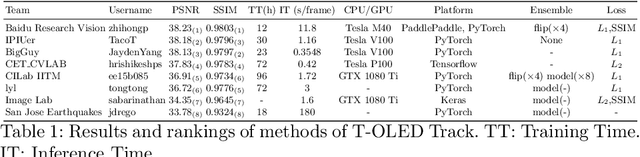
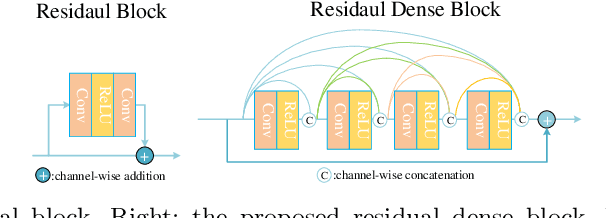
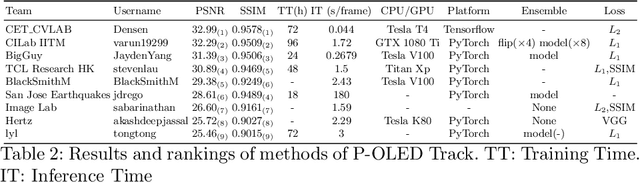
This paper is the report of the first Under-Display Camera (UDC) image restoration challenge in conjunction with the RLQ workshop at ECCV 2020. The challenge is based on a newly-collected database of Under-Display Camera. The challenge tracks correspond to two types of display: a 4k Transparent OLED (T-OLED) and a phone Pentile OLED (P-OLED). Along with about 150 teams registered the challenge, eight and nine teams submitted the results during the testing phase for each track. The results in the paper are state-of-the-art restoration performance of Under-Display Camera Restoration. Datasets and paper are available at https://yzhouas.github.io/projects/UDC/udc.html.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020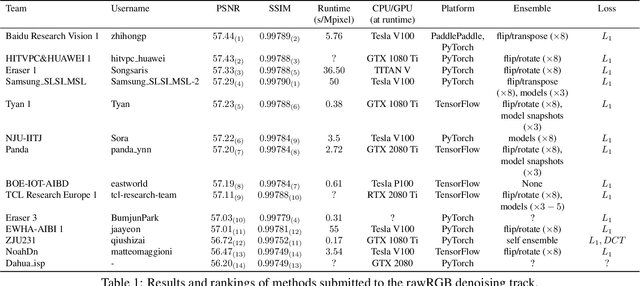
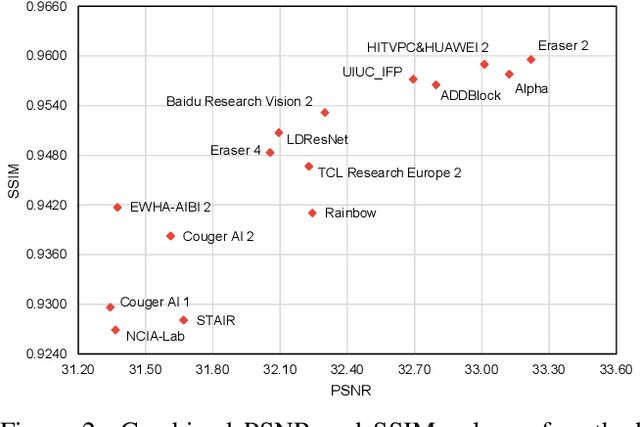
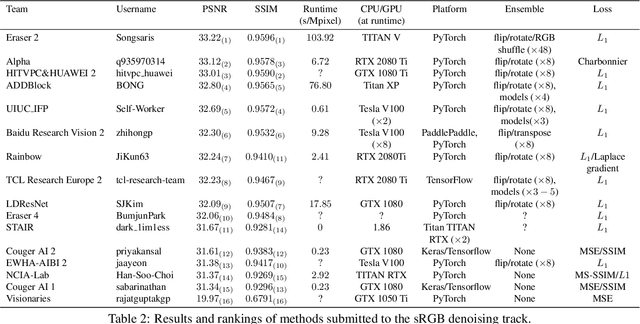
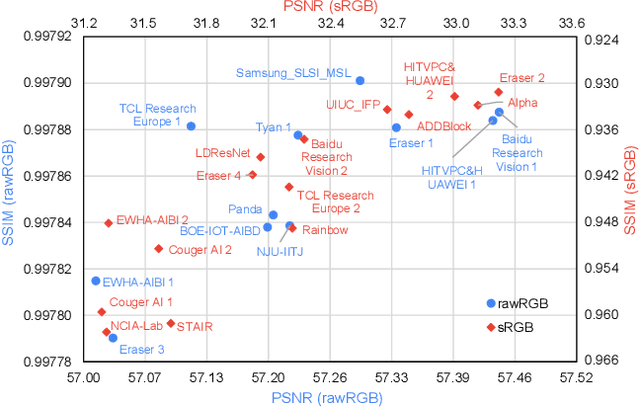
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
Lightweight Residual Network for The Classification of Thyroid Nodules
Nov 16, 2019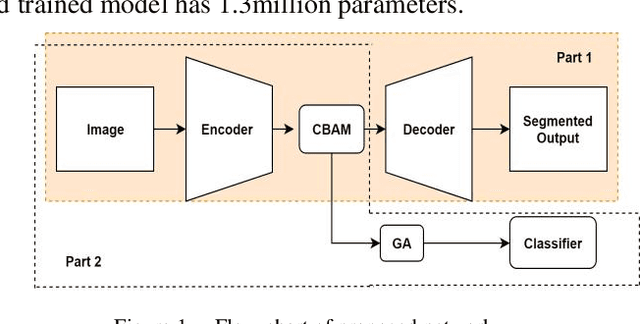
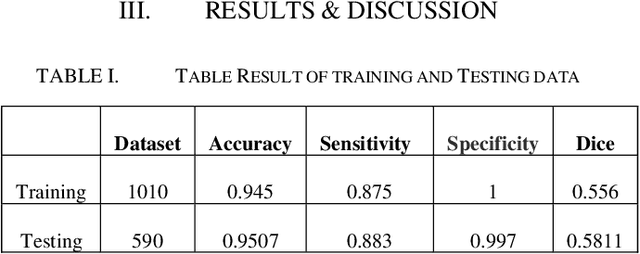
Ultrasound is a useful technique for diagnosing thyroid nodules. Benign and malignant nodules that automatically discriminate in the ultrasound pictures can provide diagnostic recommendations or, improve diagnostic accuracy in the absence of specialists. The main issue here is how to collect suitable features for this particular task. We suggest here a technique for extracting features from ultrasound pictures based on the Residual U-net. We attempt to introduce significant semantic characteristics to the classification. Our model gained 95% classification accuracy.