 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic Evaluation of Long-Context LLMs on Financial Concepts
Dec 19, 2024
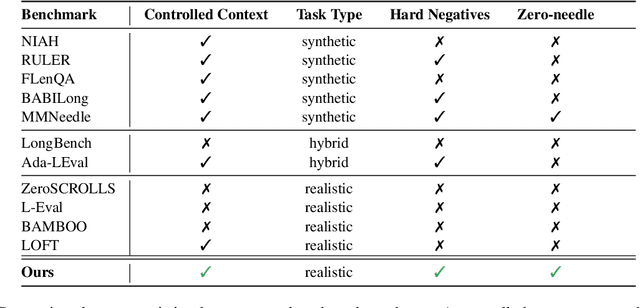
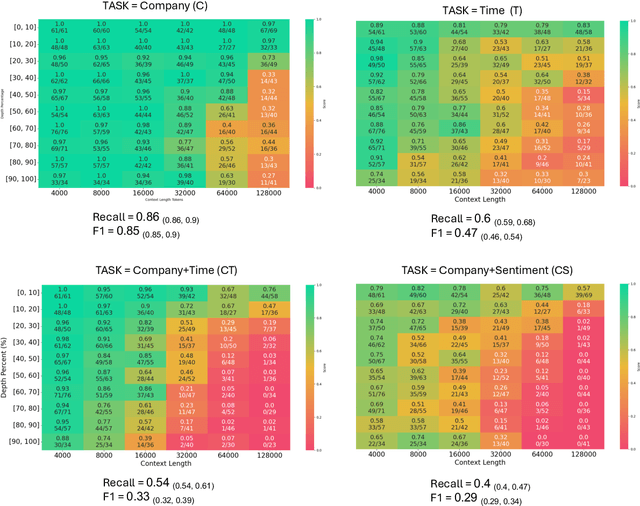
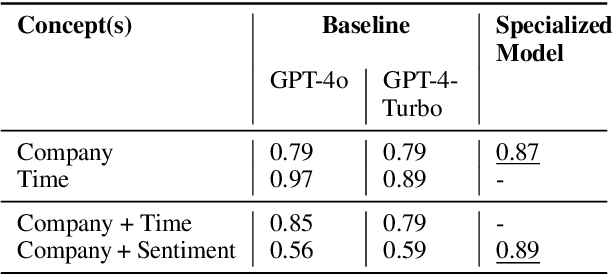
Long-context large language models (LC LLMs) promise to increase reliability of LLMs in real-world tasks requiring processing and understanding of long input documents. However, this ability of LC LLMs to reliably utilize their growing context windows remains under investigation. In this work, we evaluate the performance of state-of-the-art GPT-4 suite of LC LLMs in solving a series of progressively challenging tasks, as a function of factors such as context length, task difficulty, and position of key information by creating a real world financial news dataset. Our findings indicate that LC LLMs exhibit brittleness at longer context lengths even for simple tasks, with performance deteriorating sharply as task complexity increases. At longer context lengths, these state-of-the-art models experience catastrophic failures in instruction following resulting in degenerate outputs. Our prompt ablations also reveal unfortunate continued sensitivity to both the placement of the task instruction in the context window as well as minor markdown formatting. Finally, we advocate for more rigorous evaluation of LC LLMs by employing holistic metrics such as F1 (rather than recall) and reporting confidence intervals, thereby ensuring robust and conclusive findings.
* Accepted at EMNLP 2024
Importance of Synthesizing High-quality Data for Text-to-SQL Parsing
Dec 17, 2022



Recently, there has been increasing interest in synthesizing data to improve downstream text-to-SQL tasks. In this paper, we first examined the existing synthesized datasets and discovered that state-of-the-art text-to-SQL algorithms did not further improve on popular benchmarks when trained with augmented synthetic data. We observed two shortcomings: illogical synthetic SQL queries from independent column sampling and arbitrary table joins. To address these issues, we propose a novel synthesis framework that incorporates key relationships from schema, imposes strong typing, and conducts schema-distance-weighted column sampling. We also adopt an intermediate representation (IR) for the SQL-to-text task to further improve the quality of the generated natural language questions. When existing powerful semantic parsers are pre-finetuned on our high-quality synthesized data, our experiments show that these models have significant accuracy boosts on popular benchmarks, including new state-of-the-art performance on Spider.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020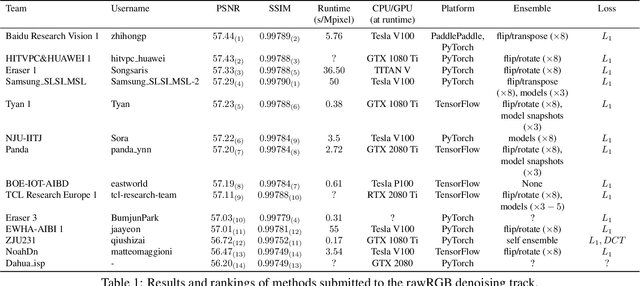
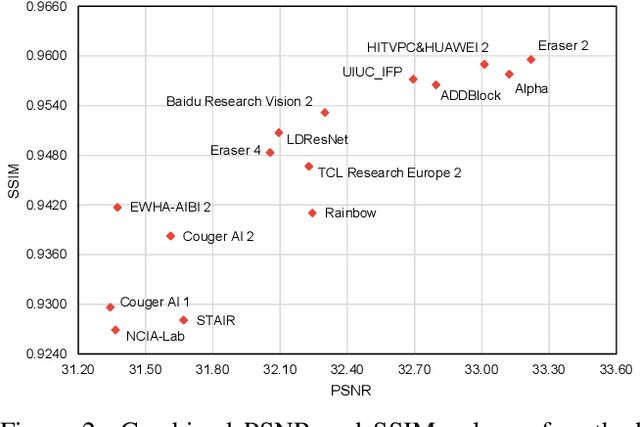
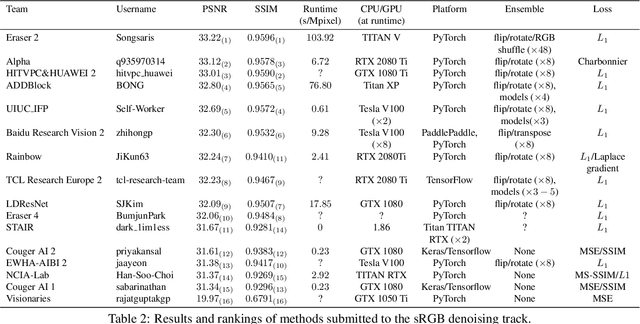
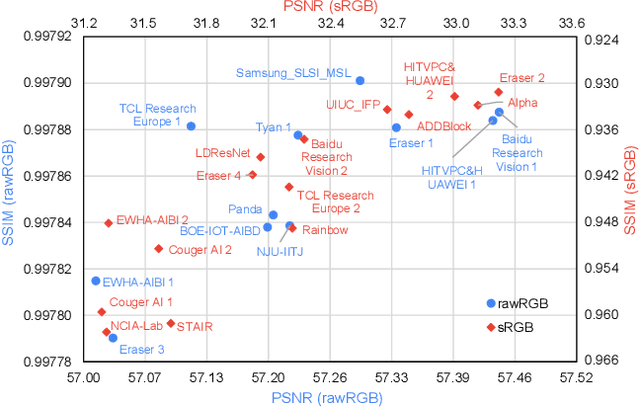
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Pyramid Real Image Denoising Network
Aug 01, 2019
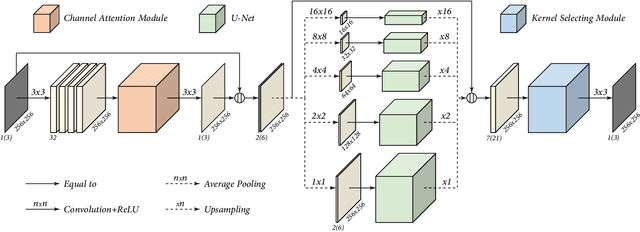
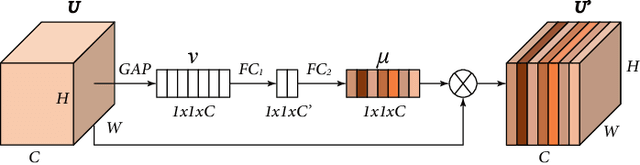
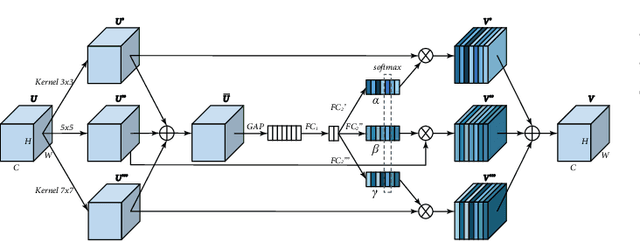
While deep Convolutional Neural Networks (CNNs) have shown extraordinary capability of modelling specific noise and denoising, they still perform poorly on real-world noisy images. The main reason is that the real-world noise is more sophisticated and diverse. To tackle the issue of blind denoising, in this paper, we propose a novel pyramid real image denoising network (PRIDNet), which contains three stages. First, the noise estimation stage uses channel attention mechanism to recalibrate the channel importance of input noise. Second, at the multi-scale denoising stage, pyramid pooling is utilized to extract multi-scale features. Third, the stage of feature fusion adopts a kernel selecting operation to adaptively fuse multi-scale features. Experiments on two datasets of real noisy photographs demonstrate that our approach can achieve competitive performance in comparison with state-of-the-art denoisers in terms of both quantitative measure and visual perception quality.