 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling to Hybrid Attention Models via KL-Guided Layer Selection
Dec 23, 2025Distilling pretrained softmax attention Transformers into more efficient hybrid architectures that interleave softmax and linear attention layers is a promising approach for improving the inference efficiency of LLMs without requiring expensive pretraining from scratch. A critical factor in the conversion process is layer selection, i.e., deciding on which layers to convert to linear attention variants. This paper describes a simple and efficient recipe for layer selection that uses layer importance scores derived from a small amount of training on generic text data. Once the layers have been selected we use a recent pipeline for the distillation process itself \citep[RADLADS;][]{goldstein2025radlads}, which consists of attention weight transfer, hidden state alignment, KL-based distribution matching, followed by a small amount of finetuning. We find that this approach is more effective than existing approaches for layer selection, including heuristics that uniformly interleave linear attentions based on a fixed ratio, as well as more involved approaches that rely on specialized diagnostic datasets.
SonicMoE: Accelerating MoE with IO and Tile-aware Optimizations
Dec 16, 2025



Mixture of Experts (MoE) models have emerged as the de facto architecture for scaling up language models without significantly increasing the computational cost. Recent MoE models demonstrate a clear trend towards high expert granularity (smaller expert intermediate dimension) and higher sparsity (constant number of activated experts with higher number of total experts), which improve model quality per FLOP. However, fine-grained MoEs suffer from increased activation memory footprint and reduced hardware efficiency due to higher IO costs, while sparser MoEs suffer from wasted computations due to padding in Grouped GEMM kernels. In response, we propose a memory-efficient algorithm to compute the forward and backward passes of MoEs with minimal activation caching for the backward pass. We also design GPU kernels that overlap memory IO with computation benefiting all MoE architectures. Finally, we propose a novel "token rounding" method that minimizes the wasted compute due to padding in Grouped GEMM kernels. As a result, our method SonicMoE reduces activation memory by 45% and achieves a 1.86x compute throughput improvement on Hopper GPUs compared to ScatterMoE's BF16 MoE kernel for a fine-grained 7B MoE. Concretely, SonicMoE on 64 H100s achieves a training throughput of 213 billion tokens per day comparable to ScatterMoE's 225 billion tokens per day on 96 H100s for a 7B MoE model training with FSDP-2 using the lm-engine codebase. Under high MoE sparsity settings, our tile-aware token rounding algorithm yields an additional 1.16x speedup on kernel execution time compared to vanilla top-$K$ routing while maintaining similar downstream performance. We open-source all our kernels to enable faster MoE model training.
Description and Discussion on DCASE 2025 Challenge Task 4: Spatial Semantic Segmentation of Sound Scenes
Jun 12, 2025

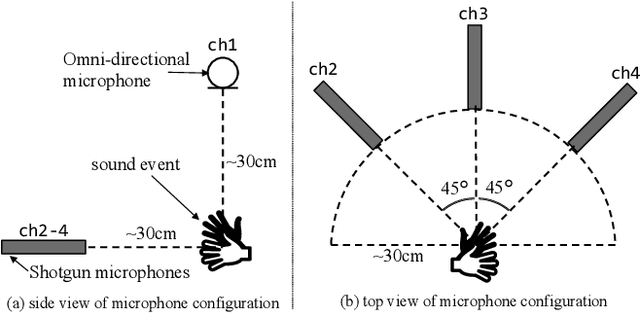
Spatial Semantic Segmentation of Sound Scenes (S5) aims to enhance technologies for sound event detection and separation from multi-channel input signals that mix multiple sound events with spatial information. This is a fundamental basis of immersive communication. The ultimate goal is to separate sound event signals with 6 Degrees of Freedom (6DoF) information into dry sound object signals and metadata about the object type (sound event class) and representing spatial information, including direction. However, because several existing challenge tasks already provide some of the subset functions, this task for this year focuses on detecting and separating sound events from multi-channel spatial input signals. This paper outlines the S5 task setting of the Detection and Classification of Acoustic Scenes and Events (DCASE) 2025 Challenge Task 4 and the DCASE2025 Task 4 Dataset, newly recorded and curated for this task. We also report experimental results for an S5 system trained and evaluated on this dataset. The full version of this paper will be published after the challenge results are made public.
FlashFormer: Whole-Model Kernels for Efficient Low-Batch Inference
May 28, 2025The size and compute characteristics of modern large language models have led to an increased interest in developing specialized kernels tailored for training and inference. Existing kernels primarily optimize for compute utilization, targeting the large-batch training and inference settings. However, low-batch inference, where memory bandwidth and kernel launch overheads contribute are significant factors, remains important for many applications of interest such as in edge deployment and latency-sensitive applications. This paper describes FlashFormer, a proof-of-concept kernel for accelerating single-batch inference for transformer-based large language models. Across various model sizes and quantizations settings, we observe nontrivial speedups compared to existing state-of-the-art inference kernels.
PaTH Attention: Position Encoding via Accumulating Householder Transformations
May 22, 2025The attention mechanism is a core primitive in modern large language models (LLMs) and AI more broadly. Since attention by itself is permutation-invariant, position encoding is essential for modeling structured domains such as language. Rotary position encoding (RoPE) has emerged as the de facto standard approach for position encoding and is part of many modern LLMs. However, in RoPE the key/query transformation between two elements in a sequence is only a function of their relative position and otherwise independent of the actual input. This limits the expressivity of RoPE-based transformers. This paper describes PaTH, a flexible data-dependent position encoding scheme based on accumulated products of Householder(like) transformations, where each transformation is data-dependent, i.e., a function of the input. We derive an efficient parallel algorithm for training through exploiting a compact representation of products of Householder matrices, and implement a FlashAttention-style blockwise algorithm that minimizes I/O cost. Across both targeted synthetic benchmarks and moderate-scale real-world language modeling experiments, we find that PaTH demonstrates superior performance compared to RoPE and other recent baselines.
Ladder-residual: parallelism-aware architecture for accelerating large model inference with communication overlapping
Jan 11, 2025



Large language model inference is both memory-intensive and time-consuming, often requiring distributed algorithms to efficiently scale. Various model parallelism strategies are used in multi-gpu training and inference to partition computation across multiple devices, reducing memory load and computation time. However, using model parallelism necessitates communication of information between GPUs, which has been a major bottleneck and limits the gains obtained by scaling up the number of devices. We introduce Ladder Residual, a simple architectural modification applicable to all residual-based models that enables straightforward overlapping that effectively hides the latency of communication. Our insight is that in addition to systems optimization, one can also redesign the model architecture to decouple communication from computation. While Ladder Residual can allow communication-computation decoupling in conventional parallelism patterns, we focus on Tensor Parallelism in this paper, which is particularly bottlenecked by its heavy communication. For a Transformer model with 70B parameters, applying Ladder Residual to all its layers can achieve 30% end-to-end wall clock speed up at inference time with TP sharding over 8 devices. We refer the resulting Transformer model as the Ladder Transformer. We train a 1B and 3B Ladder Transformer from scratch and observe comparable performance to a standard dense transformer baseline. We also show that it is possible to convert parts of the Llama-3.1 8B model to our Ladder Residual architecture with minimal accuracy degradation by only retraining for 3B tokens.
Selective Self-Rehearsal: A Fine-Tuning Approach to Improve Generalization in Large Language Models
Sep 07, 2024



Fine-tuning Large Language Models (LLMs) on specific datasets is a common practice to improve performance on target tasks. However, this performance gain often leads to overfitting, where the model becomes too specialized in either the task or the characteristics of the training data, resulting in a loss of generalization. This paper introduces Selective Self-Rehearsal (SSR), a fine-tuning approach that achieves performance comparable to the standard supervised fine-tuning (SFT) while improving generalization. SSR leverages the fact that there can be multiple valid responses to a query. By utilizing the model's correct responses, SSR reduces model specialization during the fine-tuning stage. SSR first identifies the correct model responses from the training set by deploying an appropriate LLM as a judge. Then, it fine-tunes the model using the correct model responses and the gold response for the remaining samples. The effectiveness of SSR is demonstrated through experiments on the task of identifying unanswerable queries across various datasets. The results show that standard SFT can lead to an average performance drop of up to $16.7\%$ on multiple benchmarks, such as MMLU and TruthfulQA. In contrast, SSR results in close to $2\%$ drop on average, indicating better generalization capabilities compared to standard SFT.
Power Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler
Aug 23, 2024



Finding the optimal learning rate for language model pretraining is a challenging task. This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters. Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus. While the zero-shot transferability is theoretically and empirically proven for model size related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored. In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes. Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size. The experiment shows that combining the Power scheduler with Maximum Update Parameterization (muP) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture. Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models. We open-source these pretrained models at https://ibm.biz/BdKhLa.
Scaling Granite Code Models to 128K Context
Jul 18, 2024This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024



AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.