 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Trainable Language Model Test-Time Scaling via Local Branch Routing
Jun 24, 2026Test-time scaling improves language-model reasoning, but existing approaches often face a difficult trade-off: long chain-of-thought sampling remains single-threaded, while sentence- or solution-level search can be computationally expensive and hard to train end-to-end. We introduce Local Branch Routing (LBR), a token-level test-time scaling framework that expands a small local lookahead tree, forwards all sampled branches through the language model, and uses a lightweight router to select the depth-1 subtree to commit. By routing over the hidden states of candidate local futures, LBR allows each token decision to use evidence beyond the root next-token distribution while avoiding full solution-level search. The resulting prune-shift-grow decoding process preserves discrete branch identities and defines a tractable tree-trajectory likelihood: newly grown nodes are counted when first sampled, and router decisions are assigned explicit probabilities. This enables end-to-end reinforcement learning with verifiable rewards, jointly optimizing the base model and router under the same likelihood-ratio principle as discrete-token RLVR. On synthetic hierarchical-planning tasks, LBR shows that post-candidate hidden states provide useful routing evidence. On mathematical reasoning benchmarks, LBR improves both Pass@1 and Pass@32 over discrete chain-of-thought, vanilla discrete-token RLVR, and RL-compatible soft-token branching baselines. These results suggest that lightweight local branching offers an efficient, trainable, and discrete form of language-model test-time scaling.
DRFLOW: A Deep Research Benchmark for Personalized Workflow Prediction
Jun 17, 2026Deep research (DR) systems are increasingly used for complex information-seeking tasks, but existing works mainly focus on generating reports and summaries. In contrast, many enterprise tasks instead require an agent to identify concrete workflows which is a sequence of action-steps. For example, rather than summarizing budgeting policies, an agent should be able to determine the steps needed to answer a question such as: "How do I request new headcount given a fixed budget?". Therefore, we introduce DRFLOW, a benchmark for evaluating personalized workflows predicted by agents from heterogeneous sources. Each task requires the agent to identify relevant evidence from scattered sources, then use that evidence to predict the correct action-step sequence for the user's task. DRFLOW contains 100 tasks across five domains, with 1,246 reference workflow steps grounded in more than 3,900 sources. We define seven diagnostic metrics covering factual grounding, step recovery, structural ordering, condition resolution, and personalization. We further present DRFLOW-Agent (DRFA), a workflow-oriented reference agent to predict personalized workflow. We show that although DRFA improves over strong baseline agents (upto 10.02% average F1 score), there is substantial room for improvement remains across these workflow metrics, indicating that predicting complete and correct personalized workflows remains a challenging frontier for deep research.
MCompassRAG: Topic Metadata as a Semantic Compass for Paragraph-Level Retrieval
Jun 16, 2026Retrieval-augmented generation (RAG) systems depend critically on how documents are chunked and searched. Fine-grained chunks can improve retrieval precision but expand the search space, increasing latency and cost; larger chunks reduce the number of candidates but make dense similarity less reliable, as the representation for each chunk mixes multiple topics and introduces more semantic noise. This trade-off becomes especially limiting in deep research tasks, where retrieval must be both fast and precise across large, heterogeneous corpora. We introduce MCompassRAG, a metadata-guided retrieval framework that uses topic-level signals as a semantic compass for selecting relevant evidence. Instead of relying only on cosine similarity between queries and noisy chunk embeddings, MCompassRAG enriches chunk representations with topic metadata in the same embedding space and trains a lightweight retriever through LLM-teacher distillation. At inference time, MCompassRAG performs topic-aware retrieval without additional LLM calls, improving both efficiency and evidence quality. Across six complex retrieval benchmarks, MCompassRAG improves information efficiency (IE) by 8.24% on average with over 5 times lower latency than the strongest efficient RAG baselines. Code is available on https://github.com/AmirAbaskohi/MCompassRAG.
Super Apriel: One Checkpoint, Many Speeds
Apr 21, 2026We release Super Apriel, a 15B-parameter supernet in which every decoder layer provides four trained mixer choices -- Full Attention (FA), Sliding Window Attention (SWA), Kimi Delta Attention (KDA), and Gated DeltaNet (GDN). A placement selects one mixer per layer; placements can be switched between requests at serving time without reloading weights, enabling multiple speed presets from a single checkpoint. The shared checkpoint also enables speculative decoding without a separate draft model. The all-FA preset matches the Apriel 1.6 teacher on all reported benchmarks; recommended hybrid presets span $2.9\times$ to $10.7\times$ decode throughput at 96% to 77% quality retention, with throughput advantages that compound at longer context lengths. With four mixer types across 48 layers, the configuration space is vast. A surrogate that predicts placement quality from the per-layer mixer assignment makes the speed-quality landscape tractable and identifies the best tradeoffs at each speed level. We investigate whether the best configurations at each speed level can be identified early in training or only after convergence. Rankings stabilize quickly at 0.5B scale, but the most efficient configurations exhibit higher instability at 15B, cautioning against extrapolation from smaller models. Super Apriel is trained by stochastic distillation from a frozen Apriel 1.6 teacher, followed by supervised fine-tuning. We release the supernet weights, Fast-LLM training code, vLLM serving code, and a placement optimization toolkit.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Using Scaling Laws for Data Source Utility Estimation in Domain-Specific Pre-Training
Jul 29, 2025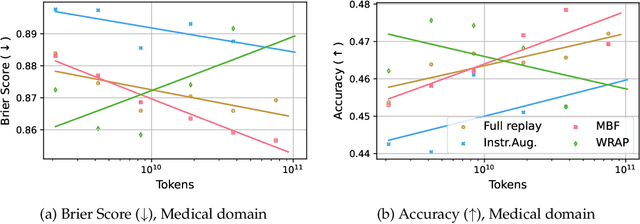
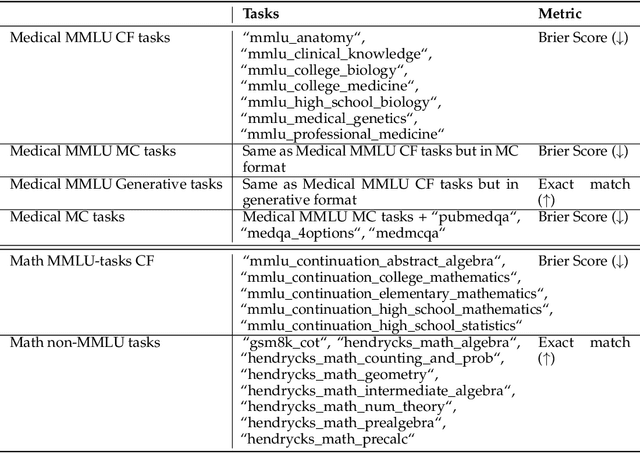
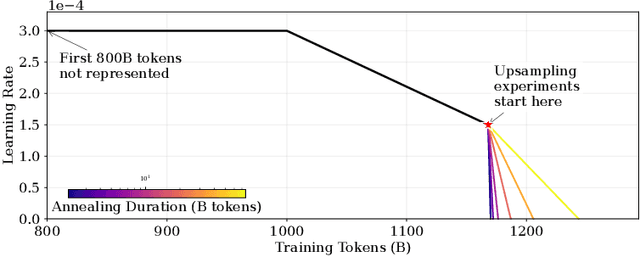
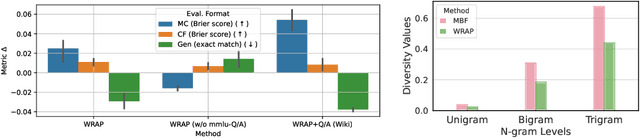
We introduce a framework for optimizing domain-specific dataset construction in foundation model training. Specifically, we seek a cost-efficient way to estimate the quality of data sources (e.g. synthetically generated or filtered web data, etc.) in order to make optimal decisions about resource allocation for data sourcing from these sources for the stage two pre-training phase, aka annealing, with the goal of specializing a generalist pre-trained model to specific domains. Our approach extends the usual point estimate approaches, aka micro-annealing, to estimating scaling laws by performing multiple annealing runs of varying compute spent on data curation and training. This addresses a key limitation in prior work, where reliance on point estimates for data scaling decisions can be misleading due to the lack of rank invariance across compute scales -- a phenomenon we confirm in our experiments. By systematically analyzing performance gains relative to acquisition costs, we find that scaling curves can be estimated for different data sources. Such scaling laws can inform cost effective resource allocation across different data acquisition methods (e.g. synthetic data), data sources (e.g. user or web data) and available compute resources. We validate our approach through experiments on a pre-trained model with 7 billion parameters. We adapt it to: a domain well-represented in the pre-training data -- the medical domain, and a domain underrepresented in the pretraining corpora -- the math domain. We show that one can efficiently estimate the scaling behaviors of a data source by running multiple annealing runs, which can lead to different conclusions, had one used point estimates using the usual micro-annealing technique instead. This enables data-driven decision-making for selecting and optimizing data sources.
Multi$^2$: Multi-Agent Test-Time Scalable Framework for Multi-Document Processing
Feb 27, 2025



Recent advances in test-time scaling have shown promising results in improving Large Language Models (LLMs) performance through strategic computation allocation during inference. While this approach has demonstrated strong performance improvements in logical and mathematical reasoning tasks, its application to natural language generation (NLG), especially summarization, has yet to be explored. Multi-Document Summarization (MDS) is a challenging task that focuses on extracting and synthesizing useful information from multiple lengthy documents. Unlike reasoning tasks, MDS requires a more nuanced approach to prompt design and ensemble, as there is no "best" prompt to satisfy diverse summarization requirements. To address this, we propose a novel framework that leverages inference-time scaling for this task. Precisely, we take prompt ensemble approach by leveraging various prompt to first generate candidate summaries and then ensemble them with an aggregator to produce a refined summary. We also introduce two new evaluation metrics: Consistency-Aware Preference (CAP) score and LLM Atom-Content-Unit (ACU) score, to enhance LLM's contextual understanding while mitigating its positional bias. Extensive experiments demonstrate the effectiveness of our approach in improving summary quality while identifying and analyzing the scaling boundaries in summarization tasks.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
DeTriever: Decoder-representation-based Retriever for Improving NL2SQL In-Context Learning
Jun 12, 2024



While in-context Learning (ICL) has proven to be an effective technique to improve the performance of Large Language Models (LLMs) in a variety of complex tasks, notably in translating natural language questions into Structured Query Language (NL2SQL), the question of how to select the most beneficial demonstration examples remains an open research problem. While prior works often adapted off-the-shelf encoders to retrieve examples dynamically, an inherent discrepancy exists in the representational capacities between the external retrievers and the LLMs. Further, optimizing the selection of examples is a non-trivial task, since there are no straightforward methods to assess the relative benefits of examples without performing pairwise inference. To address these shortcomings, we propose DeTriever, a novel demonstration retrieval framework that learns a weighted combination of LLM hidden states, where rich semantic information is encoded. To train the model, we propose a proxy score that estimates the relative benefits of examples based on the similarities between output queries. Experiments on two popular NL2SQL benchmarks demonstrate that our method significantly outperforms the state-of-the-art baselines on one-shot NL2SQL tasks.
SQL-Encoder: Improving NL2SQL In-Context Learning Through a Context-Aware Encoder
Mar 24, 2024



Detecting structural similarity between queries is essential for selecting examples in in-context learning models. However, assessing structural similarity based solely on the natural language expressions of queries, without considering SQL queries, presents a significant challenge. This paper explores the significance of this similarity metric and proposes a model for accurately estimating it. To achieve this, we leverage a dataset comprising 170k question pairs, meticulously curated to train a similarity prediction model. Our comprehensive evaluation demonstrates that the proposed model adeptly captures the structural similarity between questions, as evidenced by improvements in Kendall-Tau distance and precision@k metrics. Notably, our model outperforms strong competitive embedding models from OpenAI and Cohere. Furthermore, compared to these competitive models, our proposed encoder enhances the downstream performance of NL2SQL models in 1-shot in-context learning scenarios by 1-2\% for GPT-3.5-turbo, 4-8\% for CodeLlama-7B, and 2-3\% for CodeLlama-13B.