 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower Scheduler: A Batch Size and Token Number Agnostic Learning Rate Scheduler
Aug 23, 2024



Finding the optimal learning rate for language model pretraining is a challenging task. This is not only because there is a complicated correlation between learning rate, batch size, number of training tokens, model size, and other hyperparameters but also because it is prohibitively expensive to perform a hyperparameter search for large language models with Billions or Trillions of parameters. Recent studies propose using small proxy models and small corpus to perform hyperparameter searches and transposing the optimal parameters to large models and large corpus. While the zero-shot transferability is theoretically and empirically proven for model size related hyperparameters, like depth and width, the zero-shot transfer from small corpus to large corpus is underexplored. In this paper, we study the correlation between optimal learning rate, batch size, and number of training tokens for the recently proposed WSD scheduler. After thousands of small experiments, we found a power-law relationship between variables and demonstrated its transferability across model sizes. Based on the observation, we propose a new learning rate scheduler, Power scheduler, that is agnostic about the number of training tokens and batch size. The experiment shows that combining the Power scheduler with Maximum Update Parameterization (muP) can consistently achieve impressive performance with one set of hyperparameters regardless of the number of training tokens, batch size, model size, and even model architecture. Our 3B dense and MoE models trained with the Power scheduler achieve comparable performance as state-of-the-art small language models. We open-source these pretrained models at https://ibm.biz/BdKhLa.
Scaling Granite Code Models to 128K Context
Jul 18, 2024This paper introduces long-context Granite code models that support effective context windows of up to 128K tokens. Our solution for scaling context length of Granite 3B/8B code models from 2K/4K to 128K consists of a light-weight continual pretraining by gradually increasing its RoPE base frequency with repository-level file packing and length-upsampled long-context data. Additionally, we also release instruction-tuned models with long-context support which are derived by further finetuning the long context base models on a mix of permissively licensed short and long-context instruction-response pairs. While comparing to the original short-context Granite code models, our long-context models achieve significant improvements on long-context tasks without any noticeable performance degradation on regular code completion benchmarks (e.g., HumanEval). We release all our long-context Granite code models under an Apache 2.0 license for both research and commercial use.
The infrastructure powering IBM's Gen AI model development
Jul 07, 2024



AI Infrastructure plays a key role in the speed and cost-competitiveness of developing and deploying advanced AI models. The current demand for powerful AI infrastructure for model training is driven by the emergence of generative AI and foundational models, where on occasion thousands of GPUs must cooperate on a single training job for the model to be trained in a reasonable time. Delivering efficient and high-performing AI training requires an end-to-end solution that combines hardware, software and holistic telemetry to cater for multiple types of AI workloads. In this report, we describe IBM's hybrid cloud infrastructure that powers our generative AI model development. This infrastructure includes (1) Vela: an AI-optimized supercomputing capability directly integrated into the IBM Cloud, delivering scalable, dynamic, multi-tenant and geographically distributed infrastructure for large-scale model training and other AI workflow steps and (2) Blue Vela: a large-scale, purpose-built, on-premises hosting environment that is optimized to support our largest and most ambitious AI model training tasks. Vela provides IBM with the dual benefit of high performance for internal use along with the flexibility to adapt to an evolving commercial landscape. Blue Vela provides us with the benefits of rapid development of our largest and most ambitious models, as well as future-proofing against the evolving model landscape in the industry. Taken together, they provide IBM with the ability to rapidly innovate in the development of both AI models and commercial offerings.
Granite Code Models: A Family of Open Foundation Models for Code Intelligence
May 07, 2024



Large Language Models (LLMs) trained on code are revolutionizing the software development process. Increasingly, code LLMs are being integrated into software development environments to improve the productivity of human programmers, and LLM-based agents are beginning to show promise for handling complex tasks autonomously. Realizing the full potential of code LLMs requires a wide range of capabilities, including code generation, fixing bugs, explaining and documenting code, maintaining repositories, and more. In this work, we introduce the Granite series of decoder-only code models for code generative tasks, trained with code written in 116 programming languages. The Granite Code models family consists of models ranging in size from 3 to 34 billion parameters, suitable for applications ranging from complex application modernization tasks to on-device memory-constrained use cases. Evaluation on a comprehensive set of tasks demonstrates that Granite Code models consistently reaches state-of-the-art performance among available open-source code LLMs. The Granite Code model family was optimized for enterprise software development workflows and performs well across a range of coding tasks (e.g. code generation, fixing and explanation), making it a versatile all around code model. We release all our Granite Code models under an Apache 2.0 license for both research and commercial use.
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Apr 08, 2024



Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$\times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$\times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86\times$ faster than similar dense models like Mistral-7B, and between $1.50\times$ and $1.71\times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
Rapid Development of Compositional AI
Feb 12, 2023



Compositional AI systems, which combine multiple artificial intelligence components together with other application components to solve a larger problem, have no known pattern of development and are often approached in a bespoke and ad hoc style. This makes development slower and harder to reuse for future applications. To support the full rapid development cycle of compositional AI applications, we have developed a novel framework called (Bee)* (written as a regular expression and pronounced as "beestar"). We illustrate how (Bee)* supports building integrated, scalable, and interactive compositional AI applications with a simplified developer experience.
* Accepted to ICSE 2023, NIER track
Distributed Adversarial Training to Robustify Deep Neural Networks at Scale
Jun 13, 2022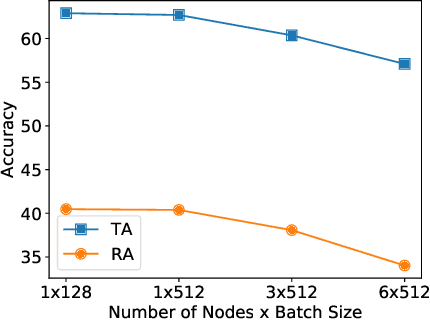
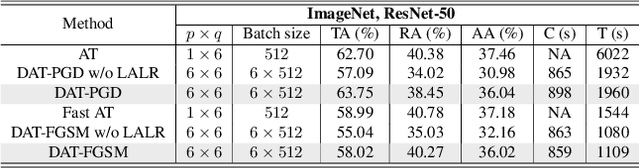
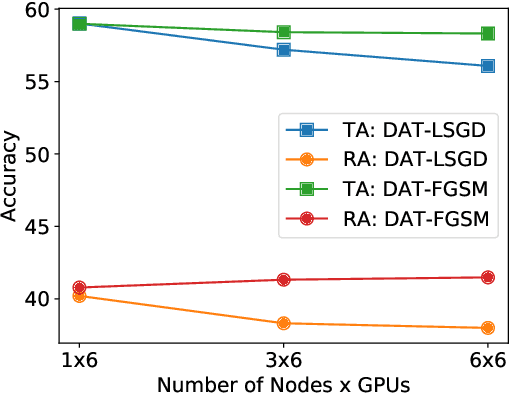
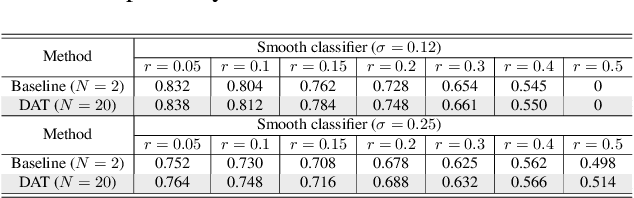
Current deep neural networks (DNNs) are vulnerable to adversarial attacks, where adversarial perturbations to the inputs can change or manipulate classification. To defend against such attacks, an effective and popular approach, known as adversarial training (AT), has been shown to mitigate the negative impact of adversarial attacks by virtue of a min-max robust training method. While effective, it remains unclear whether it can successfully be adapted to the distributed learning context. The power of distributed optimization over multiple machines enables us to scale up robust training over large models and datasets. Spurred by that, we propose distributed adversarial training (DAT), a large-batch adversarial training framework implemented over multiple machines. We show that DAT is general, which supports training over labeled and unlabeled data, multiple types of attack generation methods, and gradient compression operations favored for distributed optimization. Theoretically, we provide, under standard conditions in the optimization theory, the convergence rate of DAT to the first-order stationary points in general non-convex settings. Empirically, we demonstrate that DAT either matches or outperforms state-of-the-art robust accuracies and achieves a graceful training speedup (e.g., on ResNet-50 under ImageNet). Codes are available at https://github.com/dat-2022/dat.
When Does Contrastive Learning Preserve Adversarial Robustness from Pretraining to Finetuning?
Nov 01, 2021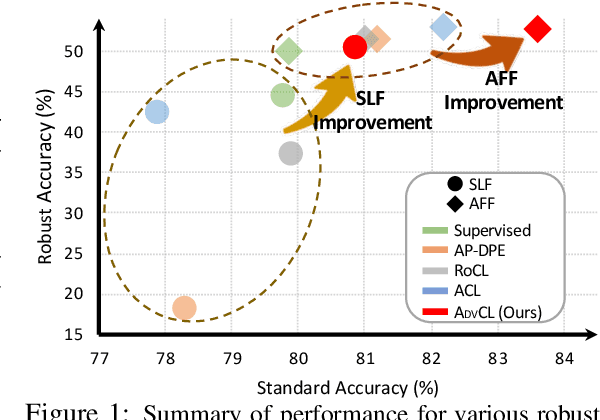
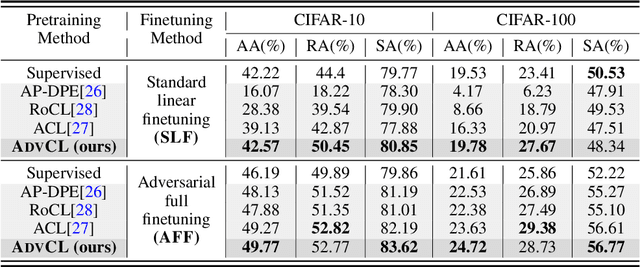
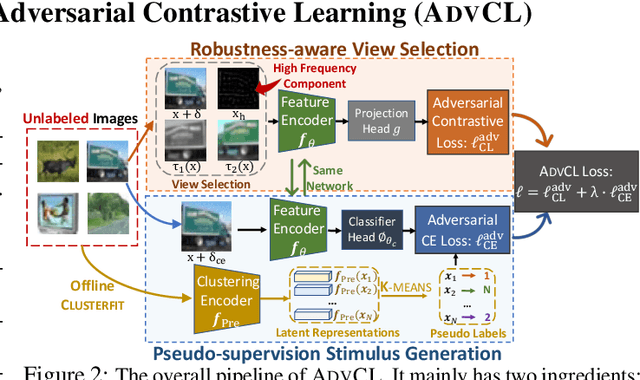
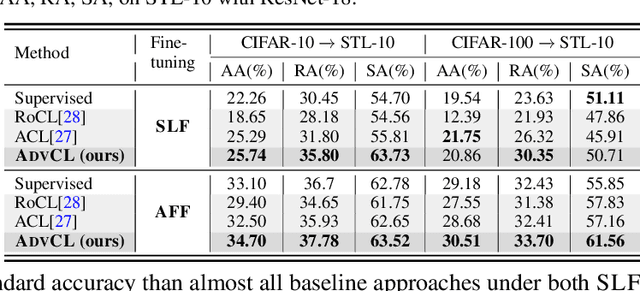
Contrastive learning (CL) can learn generalizable feature representations and achieve the state-of-the-art performance of downstream tasks by finetuning a linear classifier on top of it. However, as adversarial robustness becomes vital in image classification, it remains unclear whether or not CL is able to preserve robustness to downstream tasks. The main challenge is that in the self-supervised pretraining + supervised finetuning paradigm, adversarial robustness is easily forgotten due to a learning task mismatch from pretraining to finetuning. We call such a challenge 'cross-task robustness transferability'. To address the above problem, in this paper we revisit and advance CL principles through the lens of robustness enhancement. We show that (1) the design of contrastive views matters: High-frequency components of images are beneficial to improving model robustness; (2) Augmenting CL with pseudo-supervision stimulus (e.g., resorting to feature clustering) helps preserve robustness without forgetting. Equipped with our new designs, we propose AdvCL, a novel adversarial contrastive pretraining framework. We show that AdvCL is able to enhance cross-task robustness transferability without loss of model accuracy and finetuning efficiency. With a thorough experimental study, we demonstrate that AdvCL outperforms the state-of-the-art self-supervised robust learning methods across multiple datasets (CIFAR-10, CIFAR-100, and STL-10) and finetuning schemes (linear evaluation and full model finetuning).
Generating Adversarial Computer Programs using Optimized Obfuscations
Mar 18, 2021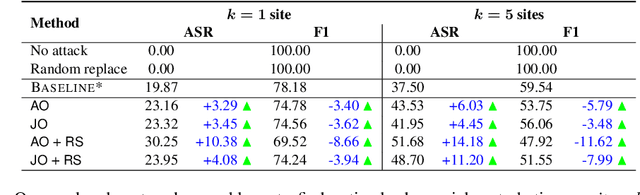

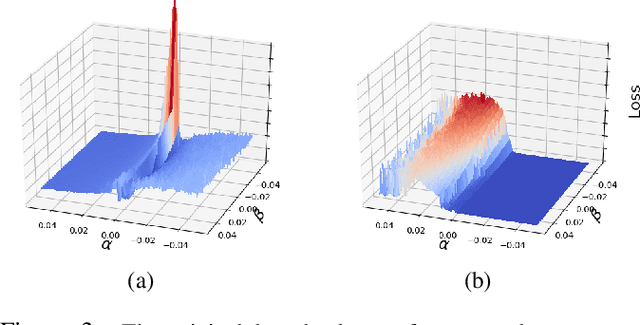
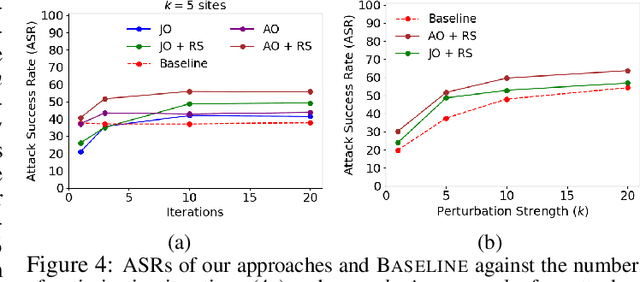
Machine learning (ML) models that learn and predict properties of computer programs are increasingly being adopted and deployed. These models have demonstrated success in applications such as auto-completing code, summarizing large programs, and detecting bugs and malware in programs. In this work, we investigate principled ways to adversarially perturb a computer program to fool such learned models, and thus determine their adversarial robustness. We use program obfuscations, which have conventionally been used to avoid attempts at reverse engineering programs, as adversarial perturbations. These perturbations modify programs in ways that do not alter their functionality but can be crafted to deceive an ML model when making a decision. We provide a general formulation for an adversarial program that allows applying multiple obfuscation transformations to a program in any language. We develop first-order optimization algorithms to efficiently determine two key aspects -- which parts of the program to transform, and what transformations to use. We show that it is important to optimize both these aspects to generate the best adversarially perturbed program. Due to the discrete nature of this problem, we also propose using randomized smoothing to improve the attack loss landscape to ease optimization. We evaluate our work on Python and Java programs on the problem of program summarization. We show that our best attack proposal achieves a $52\%$ improvement over a state-of-the-art attack generation approach for programs trained on a seq2seq model. We further show that our formulation is better at training models that are robust to adversarial attacks.
Fast Training of Provably Robust Neural Networks by SingleProp
Feb 01, 2021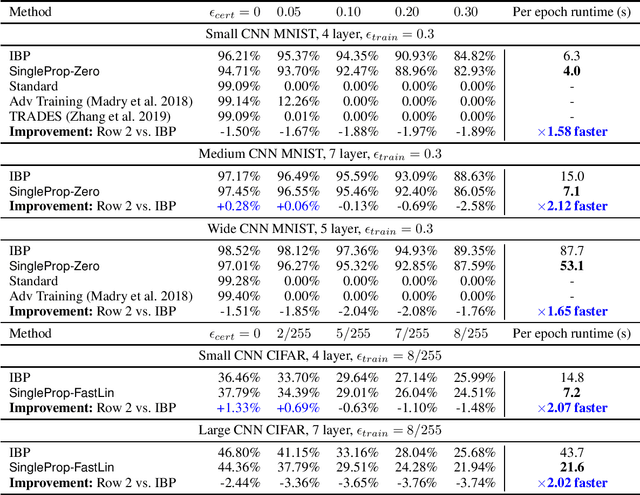


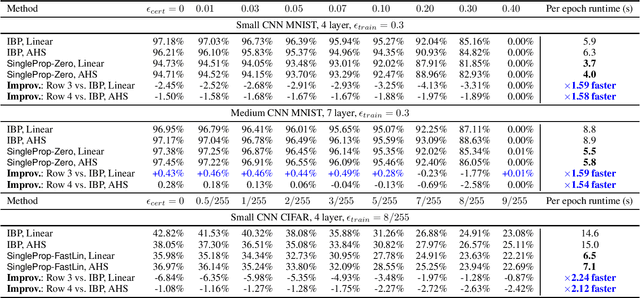
Recent works have developed several methods of defending neural networks against adversarial attacks with certified guarantees. However, these techniques can be computationally costly due to the use of certification during training. We develop a new regularizer that is both more efficient than existing certified defenses, requiring only one additional forward propagation through a network, and can be used to train networks with similar certified accuracy. Through experiments on MNIST and CIFAR-10 we demonstrate improvements in training speed and comparable certified accuracy compared to state-of-the-art certified defenses.