 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Scaling Laws for Data Source Utility Estimation in Domain-Specific Pre-Training
Jul 29, 2025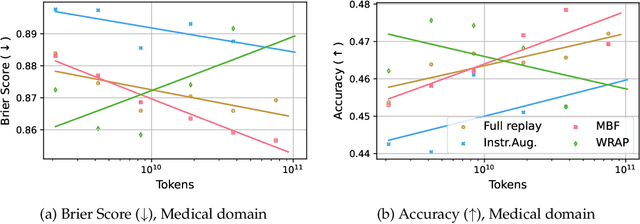
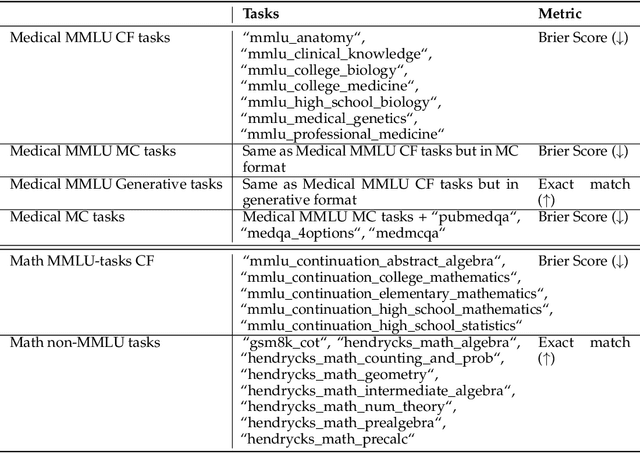
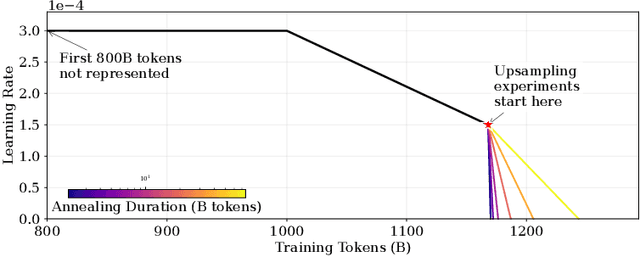
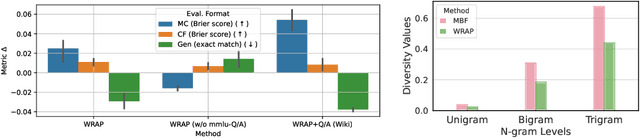
We introduce a framework for optimizing domain-specific dataset construction in foundation model training. Specifically, we seek a cost-efficient way to estimate the quality of data sources (e.g. synthetically generated or filtered web data, etc.) in order to make optimal decisions about resource allocation for data sourcing from these sources for the stage two pre-training phase, aka annealing, with the goal of specializing a generalist pre-trained model to specific domains. Our approach extends the usual point estimate approaches, aka micro-annealing, to estimating scaling laws by performing multiple annealing runs of varying compute spent on data curation and training. This addresses a key limitation in prior work, where reliance on point estimates for data scaling decisions can be misleading due to the lack of rank invariance across compute scales -- a phenomenon we confirm in our experiments. By systematically analyzing performance gains relative to acquisition costs, we find that scaling curves can be estimated for different data sources. Such scaling laws can inform cost effective resource allocation across different data acquisition methods (e.g. synthetic data), data sources (e.g. user or web data) and available compute resources. We validate our approach through experiments on a pre-trained model with 7 billion parameters. We adapt it to: a domain well-represented in the pre-training data -- the medical domain, and a domain underrepresented in the pretraining corpora -- the math domain. We show that one can efficiently estimate the scaling behaviors of a data source by running multiple annealing runs, which can lead to different conclusions, had one used point estimates using the usual micro-annealing technique instead. This enables data-driven decision-making for selecting and optimizing data sources.
StarCoder 2 and The Stack v2: The Next Generation
Feb 29, 2024



The BigCode project, an open-scientific collaboration focused on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder2. In partnership with Software Heritage (SWH), we build The Stack v2 on top of the digital commons of their source code archive. Alongside the SWH repositories spanning 619 programming languages, we carefully select other high-quality data sources, such as GitHub pull requests, Kaggle notebooks, and code documentation. This results in a training set that is 4x larger than the first StarCoder dataset. We train StarCoder2 models with 3B, 7B, and 15B parameters on 3.3 to 4.3 trillion tokens and thoroughly evaluate them on a comprehensive set of Code LLM benchmarks. We find that our small model, StarCoder2-3B, outperforms other Code LLMs of similar size on most benchmarks, and also outperforms StarCoderBase-15B. Our large model, StarCoder2- 15B, significantly outperforms other models of comparable size. In addition, it matches or outperforms CodeLlama-34B, a model more than twice its size. Although DeepSeekCoder- 33B is the best-performing model at code completion for high-resource languages, we find that StarCoder2-15B outperforms it on math and code reasoning benchmarks, as well as several low-resource languages. We make the model weights available under an OpenRAIL license and ensure full transparency regarding the training data by releasing the SoftWare Heritage persistent IDentifiers (SWHIDs) of the source code data.
The BigCode Project Governance Card
Dec 06, 2023This document serves as an overview of the different mechanisms and areas of governance in the BigCode project. It aims to support transparency by providing relevant information about choices that were made during the project to the broader public, and to serve as an example of intentional governance of an open research project that future endeavors can leverage to shape their own approach. The first section, Project Structure, covers the project organization, its stated goals and values, its internal decision processes, and its funding and resources. The second section, Data and Model Governance, covers decisions relating to the questions of data subject consent, privacy, and model release.
Towards Solving the Interdisciplinary Language Barrier Problem
Oct 18, 2001
This work aims to make it easier for a specialist in one field to find and explore ideas from another field which may be useful in solving a new problem arising in his practice. It presents a methodology which serves to represent the relationships that exist between concepts, problems, and solution patterns from different fields of human activity in the form of a graph. Our approach is based upon generalization and specialization relationships and problem solving. It is simple enough to be understood quite easily, and general enough to enable coherent integration of concepts and problems from virtually any field. We have built an implementation which uses the World Wide Web as a support to allow navigation between graph nodes and collaborative development of the graph.