 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Coreference Resolution Evaluation Using Explicit Semantics
May 11, 2026Coreference resolution is typically evaluated using aggregate statistical metrics such as CoNLL-F1, which measure structural overlap between predicted and gold clusters. While widely used, these metrics offer limited diagnostic insights, penalizing errors without revealing whether a system struggles with specific semantic categories, such as people, locations, or events, and making it difficult to interpret model capabilities or derive actionable improvements. We address this gap by introducing a semantically-enhanced evaluation framework for coreference resolution. Our approach overlays Concept and Named Entity Recognition (CNER) onto coreference outputs, assigning semantic labels to nominal mentions and propagating them to entire coreference clusters. This enables the computation of typed scores aimed at evaluating mention extraction and linking capabilities stratified by semantic class. Across our experiments on OntoNotes, LitBank, and PreCo, we show that our framework uncovers systematic weaknesses that remain obscured by aggregate metrics. Furthermore, we demonstrate that these diagnostics can be used to design targeted, low-cost data augmentation strategies, achieving measurable out-of-domain improvements.
Process Reward Models Meet Planning: Generating Precise and Scalable Datasets for Step-Level Rewards
Apr 20, 2026Process Reward Models (PRMs) have emerged as a powerful tool for providing step-level feedback when evaluating the reasoning of Large Language Models (LLMs), which frequently produce chains of thought (CoTs) containing errors even when the final answer is correct. However, existing PRM datasets remain expensive to construct, prone to annotation errors, and predominantly limited to the mathematical domain. This work introduces a novel and scalable approach to PRM dataset generation based on planning logical problems expressed in the Planning Domain Definition Language (PDDL). Using this method, we generate a corpus of approximately one million reasoning steps across various PDDL domains and use it to train PRMs. Experimental results show that augmenting widely-used PRM training datasets with PDDL-derived data yields substantial improvements in both mathematical and non-mathematical reasoning, as demonstrated across multiple benchmarks. These findings indicate that planning problems constitute a scalable and effective resource for generating robust, precise, and fine-grained training data for PRMs, going beyond the classical mathematical sources that dominate this field.
Do Large Language Models Understand Word Senses?
Sep 17, 2025



Understanding the meaning of words in context is a fundamental capability for Large Language Models (LLMs). Despite extensive evaluation efforts, the extent to which LLMs show evidence that they truly grasp word senses remains underexplored. In this paper, we address this gap by evaluating both i) the Word Sense Disambiguation (WSD) capabilities of instruction-tuned LLMs, comparing their performance to state-of-the-art systems specifically designed for the task, and ii) the ability of two top-performing open- and closed-source LLMs to understand word senses in three generative settings: definition generation, free-form explanation, and example generation. Notably, we find that, in the WSD task, leading models such as GPT-4o and DeepSeek-V3 achieve performance on par with specialized WSD systems, while also demonstrating greater robustness across domains and levels of difficulty. In the generation tasks, results reveal that LLMs can explain the meaning of words in context up to 98\% accuracy, with the highest performance observed in the free-form explanation task, which best aligns with their generative capabilities.
Estimating Machine Translation Difficulty
Aug 13, 2025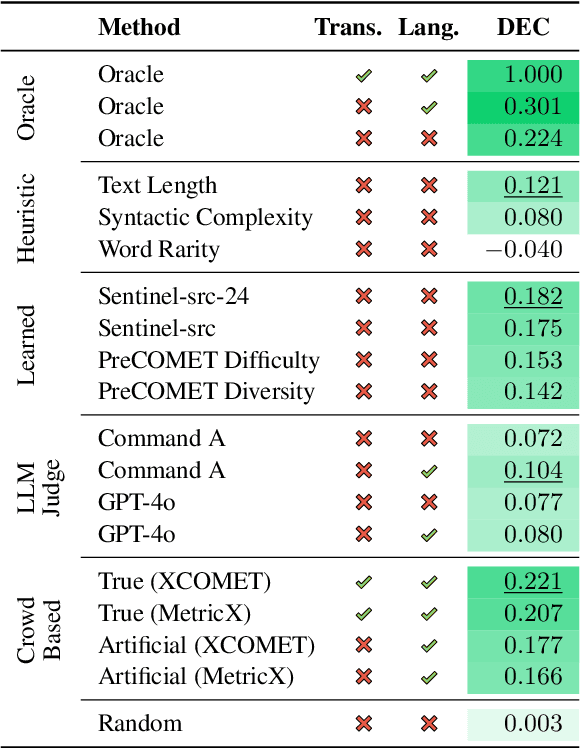
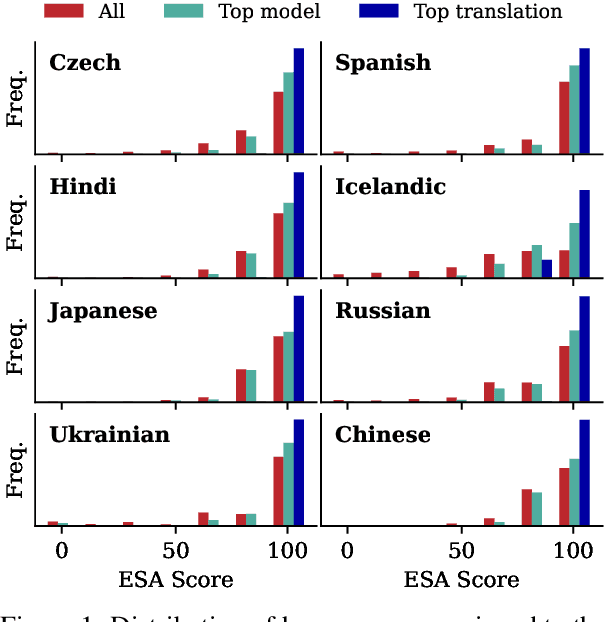
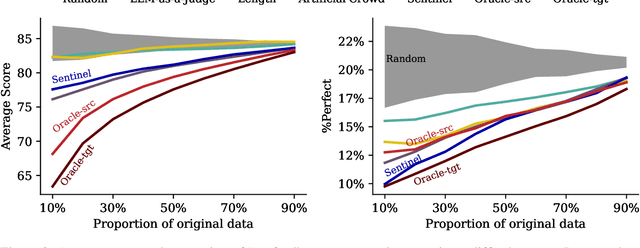
Machine translation quality has began achieving near-perfect translations in some setups. These high-quality outputs make it difficult to distinguish between state-of-the-art models and to identify areas for future improvement. Automatically identifying texts where machine translation systems struggle holds promise for developing more discriminative evaluations and guiding future research. We formalize the task of translation difficulty estimation, defining a text's difficulty based on the expected quality of its translations. We introduce a new metric to evaluate difficulty estimators and use it to assess both baselines and novel approaches. Finally, we demonstrate the practical utility of difficulty estimators by using them to construct more challenging machine translation benchmarks. Our results show that dedicated models (dubbed Sentinel-src) outperform both heuristic-based methods (e.g. word rarity or syntactic complexity) and LLM-as-a-judge approaches. We release two improved models for difficulty estimation, Sentinel-src-24 and Sentinel-src-25, which can be used to scan large collections of texts and select those most likely to challenge contemporary machine translation systems.
BOOKCOREF: Coreference Resolution at Book Scale
Jul 16, 2025Coreference Resolution systems are typically evaluated on benchmarks containing small- to medium-scale documents. When it comes to evaluating long texts, however, existing benchmarks, such as LitBank, remain limited in length and do not adequately assess system capabilities at the book scale, i.e., when co-referring mentions span hundreds of thousands of tokens. To fill this gap, we first put forward a novel automatic pipeline that produces high-quality Coreference Resolution annotations on full narrative texts. Then, we adopt this pipeline to create the first book-scale coreference benchmark, BOOKCOREF, with an average document length of more than 200,000 tokens. We carry out a series of experiments showing the robustness of our automatic procedure and demonstrating the value of our resource, which enables current long-document coreference systems to gain up to +20 CoNLL-F1 points when evaluated on full books. Moreover, we report on the new challenges introduced by this unprecedented book-scale setting, highlighting that current models fail to deliver the same performance they achieve on smaller documents. We release our data and code to encourage research and development of new book-scale Coreference Resolution systems at https://github.com/sapienzanlp/bookcoref.
FuDoBa: Fusing Document and Knowledge Graph-based Representations with Bayesian Optimisation
Jul 09, 2025Building on the success of Large Language Models (LLMs), LLM-based representations have dominated the document representation landscape, achieving great performance on the document embedding benchmarks. However, the high-dimensional, computationally expensive embeddings from LLMs tend to be either too generic or inefficient for domain-specific applications. To address these limitations, we introduce FuDoBa a Bayesian optimisation-based method that integrates LLM-based embeddings with domain-specific structured knowledge, sourced both locally and from external repositories like WikiData. This fusion produces low-dimensional, task-relevant representations while reducing training complexity and yielding interpretable early-fusion weights for enhanced classification performance. We demonstrate the effectiveness of our approach on six datasets in two domains, showing that when paired with robust AutoML-based classifiers, our proposed representation learning approach performs on par with, or surpasses, those produced solely by the proprietary LLM-based embedding baselines.
Has Machine Translation Evaluation Achieved Human Parity? The Human Reference and the Limits of Progress
Jun 24, 2025



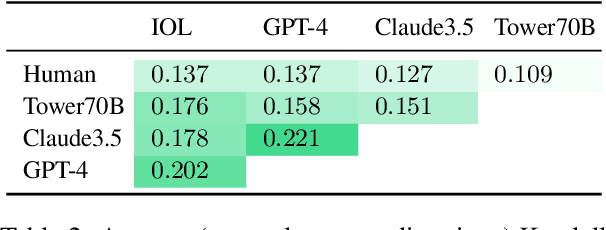
In Machine Translation (MT) evaluation, metric performance is assessed based on agreement with human judgments. In recent years, automatic metrics have demonstrated increasingly high levels of agreement with humans. To gain a clearer understanding of metric performance and establish an upper bound, we incorporate human baselines in the MT meta-evaluation, that is, the assessment of MT metrics' capabilities. Our results show that human annotators are not consistently superior to automatic metrics, with state-of-the-art metrics often ranking on par with or higher than human baselines. Despite these findings suggesting human parity, we discuss several reasons for caution. Finally, we explore the broader implications of our results for the research field, asking: Can we still reliably measure improvements in MT evaluation? With this work, we aim to shed light on the limits of our ability to measure progress in the field, fostering discussion on an issue that we believe is crucial to the entire MT evaluation community.
Optimizing LLMs for Italian: Reducing Token Fertility and Enhancing Efficiency Through Vocabulary Adaptation
Apr 23, 2025The number of pretrained Large Language Models (LLMs) is increasing steadily, though the majority are designed predominantly for the English language. While state-of-the-art LLMs can handle other languages, due to language contamination or some degree of multilingual pretraining data, they are not optimized for non-English languages, leading to inefficient encoding (high token "fertility") and slower inference speed. In this work, we thoroughly compare a variety of vocabulary adaptation techniques for optimizing English LLMs for the Italian language, and put forward Semantic Alignment Vocabulary Adaptation (SAVA), a novel method that leverages neural mapping for vocabulary substitution. SAVA achieves competitive performance across multiple downstream tasks, enhancing grounded alignment strategies. We adapt two LLMs: Mistral-7b-v0.1, reducing token fertility by 25\%, and Llama-3.1-8B, optimizing the vocabulary and reducing the number of parameters by 1 billion. We show that, following the adaptation of the vocabulary, these models can recover their performance with a relatively limited stage of continual training on the target language. Finally, we test the capabilities of the adapted models on various multi-choice and generative tasks.
Right Answer, Wrong Score: Uncovering the Inconsistencies of LLM Evaluation in Multiple-Choice Question Answering
Mar 19, 2025



One of the most widely used tasks to evaluate Large Language Models (LLMs) is Multiple-Choice Question Answering (MCQA). While open-ended question answering tasks are more challenging to evaluate, MCQA tasks are, in principle, easier to assess, as the model's answer is thought to be simple to extract and is directly compared to a set of predefined choices. However, recent studies have started to question the reliability of MCQA evaluation, showing that multiple factors can significantly impact the reported performance of LLMs, especially when the model generates free-form text before selecting one of the answer choices. In this work, we shed light on the inconsistencies of MCQA evaluation strategies, which can lead to inaccurate and misleading model comparisons. We systematically analyze whether existing answer extraction methods are aligned with human judgment, and how they are influenced by answer constraints in the prompt across different domains. Our experiments demonstrate that traditional evaluation strategies often underestimate LLM capabilities, while LLM-based answer extractors are prone to systematic errors. Moreover, we reveal a fundamental trade-off between including format constraints in the prompt to simplify answer extraction and allowing models to generate free-form text to improve reasoning. Our findings call for standardized evaluation methodologies and highlight the need for more reliable and consistent MCQA evaluation practices.
LLMs Lost in Translation: M-ALERT uncovers Cross-Linguistic Safety Gaps
Dec 19, 2024



Building safe Large Language Models (LLMs) across multiple languages is essential in ensuring both safe access and linguistic diversity. To this end, we introduce M-ALERT, a multilingual benchmark that evaluates the safety of LLMs in five languages: English, French, German, Italian, and Spanish. M-ALERT includes 15k high-quality prompts per language, totaling 75k, following the detailed ALERT taxonomy. Our extensive experiments on 10 state-of-the-art LLMs highlight the importance of language-specific safety analysis, revealing that models often exhibit significant inconsistencies in safety across languages and categories. For instance, Llama3.2 shows high unsafety in the category crime_tax for Italian but remains safe in other languages. Similar differences can be observed across all models. In contrast, certain categories, such as substance_cannabis and crime_propaganda, consistently trigger unsafe responses across models and languages. These findings underscore the need for robust multilingual safety practices in LLMs to ensure safe and responsible usage across diverse user communities.