 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIAFormer: Voxel-Image Alignment Transformer for High-Fidelity Voxel Refinement
Jan 21, 2026We propose VIAFormer, a Voxel-Image Alignment Transformer model designed for Multi-view Conditioned Voxel Refinement--the task of repairing incomplete noisy voxels using calibrated multi-view images as guidance. Its effectiveness stems from a synergistic design: an Image Index that provides explicit 3D spatial grounding for 2D image tokens, a Correctional Flow objective that learns a direct voxel-refinement trajectory, and a Hybrid Stream Transformer that enables robust cross-modal fusion. Experiments show that VIAFormer establishes a new state of the art in correcting both severe synthetic corruptions and realistic artifacts on the voxel shape obtained from powerful Vision Foundation Models. Beyond benchmarking, we demonstrate VIAFormer as a practical and reliable bridge in real-world 3D creation pipelines, paving the way for voxel-based methods to thrive in large-model, big-data wave.
LoG3D: Ultra-High-Resolution 3D Shape Modeling via Local-to-Global Partitioning
Nov 18, 2025



Generating high-fidelity 3D contents remains a fundamental challenge due to the complexity of representing arbitrary topologies-such as open surfaces and intricate internal structures-while preserving geometric details. Prevailing methods based on signed distance fields (SDFs) are hampered by costly watertight preprocessing and struggle with non-manifold geometries, while point-cloud representations often suffer from sampling artifacts and surface discontinuities. To overcome these limitations, we propose a novel 3D variational autoencoder (VAE) framework built upon unsigned distance fields (UDFs)-a more robust and computationally efficient representation that naturally handles complex and incomplete shapes. Our core innovation is a local-to-global (LoG) architecture that processes the UDF by partitioning it into uniform subvolumes, termed UBlocks. This architecture couples 3D convolutions for capturing local detail with sparse transformers for enforcing global coherence. A Pad-Average strategy further ensures smooth transitions at subvolume boundaries during reconstruction. This modular design enables seamless scaling to ultra-high resolutions up to $2048^3$-a regime previously unattainable for 3D VAEs. Experiments demonstrate state-of-the-art performance in both reconstruction accuracy and generative quality, yielding superior surface smoothness and geometric flexibility.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
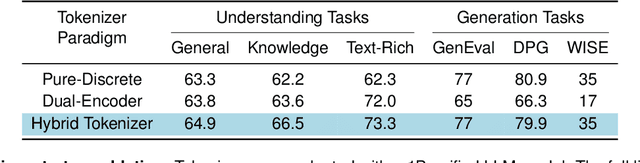
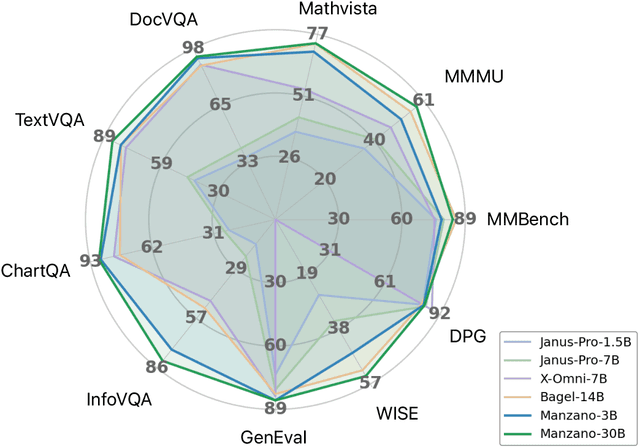
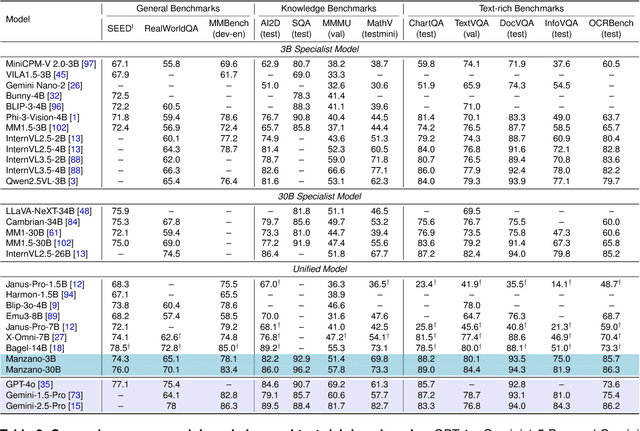
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
GlossyGS: Inverse Rendering of Glossy Objects with 3D Gaussian Splatting
Oct 17, 2024



Reconstructing objects from posed images is a crucial and complex task in computer graphics and computer vision. While NeRF-based neural reconstruction methods have exhibited impressive reconstruction ability, they tend to be time-comsuming. Recent strategies have adopted 3D Gaussian Splatting (3D-GS) for inverse rendering, which have led to quick and effective outcomes. However, these techniques generally have difficulty in producing believable geometries and materials for glossy objects, a challenge that stems from the inherent ambiguities of inverse rendering. To address this, we introduce GlossyGS, an innovative 3D-GS-based inverse rendering framework that aims to precisely reconstruct the geometry and materials of glossy objects by integrating material priors. The key idea is the use of micro-facet geometry segmentation prior, which helps to reduce the intrinsic ambiguities and improve the decomposition of geometries and materials. Additionally, we introduce a normal map prefiltering strategy to more accurately simulate the normal distribution of reflective surfaces. These strategies are integrated into a hybrid geometry and material representation that employs both explicit and implicit methods to depict glossy objects. We demonstrate through quantitative analysis and qualitative visualization that the proposed method is effective to reconstruct high-fidelity geometries and materials of glossy objects, and performs favorably against state-of-the-arts.
IntrinsicAnything: Learning Diffusion Priors for Inverse Rendering Under Unknown Illumination
Apr 17, 2024



This paper aims to recover object materials from posed images captured under an unknown static lighting condition. Recent methods solve this task by optimizing material parameters through differentiable physically based rendering. However, due to the coupling between object geometry, materials, and environment lighting, there is inherent ambiguity during the inverse rendering process, preventing previous methods from obtaining accurate results. To overcome this ill-posed problem, our key idea is to learn the material prior with a generative model for regularizing the optimization process. We observe that the general rendering equation can be split into diffuse and specular shading terms, and thus formulate the material prior as diffusion models of albedo and specular. Thanks to this design, our model can be trained using the existing abundant 3D object data, and naturally acts as a versatile tool to resolve the ambiguity when recovering material representations from RGB images. In addition, we develop a coarse-to-fine training strategy that leverages estimated materials to guide diffusion models to satisfy multi-view consistent constraints, leading to more stable and accurate results. Extensive experiments on real-world and synthetic datasets demonstrate that our approach achieves state-of-the-art performance on material recovery. The code will be available at https://zju3dv.github.io/IntrinsicAnything.
Dense Training, Sparse Inference: Rethinking Training of Mixture-of-Experts Language Models
Apr 08, 2024



Mixture-of-Experts (MoE) language models can reduce computational costs by 2-4$\times$ compared to dense models without sacrificing performance, making them more efficient in computation-bounded scenarios. However, MoE models generally require 2-4$\times$ times more parameters to achieve comparable performance to a dense model, which incurs larger GPU memory requirements and makes MoE models less efficient in I/O-bounded scenarios like autoregressive generation. In this work, we propose a hybrid dense training and sparse inference framework for MoE models (DS-MoE) which achieves strong computation and parameter efficiency by employing dense computation across all experts during training and sparse computation during inference. Our experiments on training LLMs demonstrate that our DS-MoE models are more parameter-efficient than standard sparse MoEs and are on par with dense models in terms of total parameter size and performance while being computationally cheaper (activating 30-40% of the model's parameters). Performance tests using vLLM show that our DS-MoE-6B model runs up to $1.86\times$ faster than similar dense models like Mistral-7B, and between $1.50\times$ and $1.71\times$ faster than comparable MoEs, such as DeepSeekMoE-16B and Qwen1.5-MoE-A2.7B.
EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
Nov 18, 2023



Reconstructing real-world 3D objects has numerous applications in computer vision, such as virtual reality, video games, and animations. Ideally, 3D reconstruction methods should generate high-fidelity results with 3D consistency in real-time. Traditional methods match pixels between images using photo-consistency constraints or learned features, while differentiable rendering methods like Neural Radiance Fields (NeRF) use differentiable volume rendering or surface-based representation to generate high-fidelity scenes. However, these methods require excessive runtime for rendering, making them impractical for daily applications. To address these challenges, we present $\textbf{EvaSurf}$, an $\textbf{E}$fficient $\textbf{V}$iew-$\textbf{A}$ware implicit textured $\textbf{Surf}$ace reconstruction method on mobile devices. In our method, we first employ an efficient surface-based model with a multi-view supervision module to ensure accurate mesh reconstruction. To enable high-fidelity rendering, we learn an implicit texture embedded with a set of Gaussian lobes to capture view-dependent information. Furthermore, with the explicit geometry and the implicit texture, we can employ a lightweight neural shader to reduce the expense of computation and further support real-time rendering on common mobile devices. Extensive experiments demonstrate that our method can reconstruct high-quality appearance and accurate mesh on both synthetic and real-world datasets. Moreover, our method can be trained in just 1-2 hours using a single GPU and run on mobile devices at over 40 FPS (Frames Per Second), with a final package required for rendering taking up only 40-50 MB.
LangNav: Language as a Perceptual Representation for Navigation
Oct 11, 2023



We explore the use of language as a perceptual representation for vision-and-language navigation. Our approach uses off-the-shelf vision systems (for image captioning and object detection) to convert an agent's egocentric panoramic view at each time step into natural language descriptions. We then finetune a pretrained language model to select an action, based on the current view and the trajectory history, that would best fulfill the navigation instructions. In contrast to the standard setup which adapts a pretrained language model to work directly with continuous visual features from pretrained vision models, our approach instead uses (discrete) language as the perceptual representation. We explore two use cases of our language-based navigation (LangNav) approach on the R2R vision-and-language navigation benchmark: generating synthetic trajectories from a prompted large language model (GPT-4) with which to finetune a smaller language model; and sim-to-real transfer where we transfer a policy learned on a simulated environment (ALFRED) to a real-world environment (R2R). Our approach is found to improve upon strong baselines that rely on visual features in settings where only a few gold trajectories (10-100) are available, demonstrating the potential of using language as a perceptual representation for navigation tasks.
HoloAssist: an Egocentric Human Interaction Dataset for Interactive AI Assistants in the Real World
Sep 29, 2023



Building an interactive AI assistant that can perceive, reason, and collaborate with humans in the real world has been a long-standing pursuit in the AI community. This work is part of a broader research effort to develop intelligent agents that can interactively guide humans through performing tasks in the physical world. As a first step in this direction, we introduce HoloAssist, a large-scale egocentric human interaction dataset, where two people collaboratively complete physical manipulation tasks. The task performer executes the task while wearing a mixed-reality headset that captures seven synchronized data streams. The task instructor watches the performer's egocentric video in real time and guides them verbally. By augmenting the data with action and conversational annotations and observing the rich behaviors of various participants, we present key insights into how human assistants correct mistakes, intervene in the task completion procedure, and ground their instructions to the environment. HoloAssist spans 166 hours of data captured by 350 unique instructor-performer pairs. Furthermore, we construct and present benchmarks on mistake detection, intervention type prediction, and hand forecasting, along with detailed analysis. We expect HoloAssist will provide an important resource for building AI assistants that can fluidly collaborate with humans in the real world. Data can be downloaded at https://holoassist.github.io/.
Head3D: Complete 3D Head Generation via Tri-plane Feature Distillation
Mar 28, 2023



Head generation with diverse identities is an important task in computer vision and computer graphics, widely used in multimedia applications. However, current full head generation methods require a large number of 3D scans or multi-view images to train the model, resulting in expensive data acquisition cost. To address this issue, we propose Head3D, a method to generate full 3D heads with limited multi-view images. Specifically, our approach first extracts facial priors represented by tri-planes learned in EG3D, a 3D-aware generative model, and then proposes feature distillation to deliver the 3D frontal faces into complete heads without compromising head integrity. To mitigate the domain gap between the face and head models, we present dual-discriminators to guide the frontal and back head generation, respectively. Our model achieves cost-efficient and diverse complete head generation with photo-realistic renderings and high-quality geometry representations. Extensive experiments demonstrate the effectiveness of our proposed Head3D, both qualitatively and quantitatively.