 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAKEN: Cybersecurity LLM Agent with Knowledge-Based Execution
May 21, 2025



Large Language Model (LLM) agents can automate cybersecurity tasks and can adapt to the evolving cybersecurity landscape without re-engineering. While LLM agents have demonstrated cybersecurity capabilities on Capture-The-Flag (CTF) competitions, they have two key limitations: accessing latest cybersecurity expertise beyond training data, and integrating new knowledge into complex task planning. Knowledge-based approaches that incorporate technical understanding into the task-solving automation can tackle these limitations. We present CRAKEN, a knowledge-based LLM agent framework that improves cybersecurity capability through three core mechanisms: contextual decomposition of task-critical information, iterative self-reflected knowledge retrieval, and knowledge-hint injection that transforms insights into adaptive attack strategies. Comprehensive evaluations with different configurations show CRAKEN's effectiveness in multi-stage vulnerability detection and exploitation compared to previous approaches. Our extensible architecture establishes new methodologies for embedding new security knowledge into LLM-driven cybersecurity agentic systems. With a knowledge database of CTF writeups, CRAKEN obtained an accuracy of 22% on NYU CTF Bench, outperforming prior works by 3% and achieving state-of-the-art results. On evaluation of MITRE ATT&CK techniques, CRAKEN solves 25-30% more techniques than prior work, demonstrating improved cybersecurity capabilities via knowledge-based execution. We make our framework open source to public https://github.com/NYU-LLM-CTF/nyuctf_agents_craken.
EnIGMA: Enhanced Interactive Generative Model Agent for CTF Challenges
Sep 24, 2024



Although language model (LM) agents are demonstrating growing potential in many domains, their success in cybersecurity has been limited due to simplistic design and the lack of fundamental features for this domain. We present EnIGMA, an LM agent for autonomously solving Capture The Flag (CTF) challenges. EnIGMA introduces new Agent-Computer Interfaces (ACIs) to improve the success rate on CTF challenges. We establish the novel Interactive Agent Tool concept, which enables LM agents to run interactive command-line utilities essential for these challenges. Empirical analysis of EnIGMA on over 350 CTF challenges from three different benchmarks indicates that providing a robust set of new tools with demonstration of their usage helps the LM solve complex problems and achieves state-of-the-art results on the NYU CTF and Intercode-CTF benchmarks. Finally, we discuss insights on ACI design and agent behavior on cybersecurity tasks that highlight the need to adapt real-world tools for LM agents.
ARVO: Atlas of Reproducible Vulnerabilities for Open Source Software
Aug 04, 2024



High-quality datasets of real-world vulnerabilities are enormously valuable for downstream research in software security, but existing datasets are typically small, require extensive manual effort to update, and are missing crucial features that such research needs. In this paper, we introduce ARVO: an Atlas of Reproducible Vulnerabilities in Open-source software. By sourcing vulnerabilities from C/C++ projects that Google's OSS-Fuzz discovered and implementing a reliable re-compilation system, we successfully reproduce more than 5,000 memory vulnerabilities across over 250 projects, each with a triggering input, the canonical developer-written patch for fixing the vulnerability, and the ability to automatically rebuild the project from source and run it at its vulnerable and patched revisions. Moreover, our dataset can be automatically updated as OSS-Fuzz finds new vulnerabilities, allowing it to grow over time. We provide a thorough characterization of the ARVO dataset, show that it can locate fixes more accurately than Google's own OSV reproduction effort, and demonstrate its value for future research through two case studies: firstly evaluating real-world LLM-based vulnerability repair, and secondly identifying over 300 falsely patched (still-active) zero-day vulnerabilities from projects improperly labeled by OSS-Fuzz.
NYU CTF Dataset: A Scalable Open-Source Benchmark Dataset for Evaluating LLMs in Offensive Security
Jun 08, 2024



Large Language Models (LLMs) are being deployed across various domains today. However, their capacity to solve Capture the Flag (CTF) challenges in cybersecurity has not been thoroughly evaluated. To address this, we develop a novel method to assess LLMs in solving CTF challenges by creating a scalable, open-source benchmark database specifically designed for these applications. This database includes metadata for LLM testing and adaptive learning, compiling a diverse range of CTF challenges from popular competitions. Utilizing the advanced function calling capabilities of LLMs, we build a fully automated system with an enhanced workflow and support for external tool calls. Our benchmark dataset and automated framework allow us to evaluate the performance of five LLMs, encompassing both black-box and open-source models. This work lays the foundation for future research into improving the efficiency of LLMs in interactive cybersecurity tasks and automated task planning. By providing a specialized dataset, our project offers an ideal platform for developing, testing, and refining LLM-based approaches to vulnerability detection and resolution. Evaluating LLMs on these challenges and comparing with human performance yields insights into their potential for AI-driven cybersecurity solutions to perform real-world threat management. We make our dataset open source to public https://github.com/NYU-LLM-CTF/LLM_CTF_Database along with our playground automated framework https://github.com/NYU-LLM-CTF/llm_ctf_automation.
Model Cascading for Code: Reducing Inference Costs with Model Cascading for LLM Based Code Generation
May 24, 2024The rapid development of large language models (LLMs) has led to significant advancements in code completion tasks. While larger models have higher accuracy, they also cost much more to run. Meanwhile, model cascading has been proven effective to conserve computational resources while enhancing accuracy in LLMs on natural language generation tasks. It generates output with the smallest model in a set, and only queries the larger models when it fails to meet predefined quality criteria. However, this strategy has not been used in code completion tasks, primarily because assessing the quality of code completions differs substantially from assessing natural language, where the former relies heavily on the functional correctness. To address this, we propose letting each model generate and execute a set of test cases for their solutions, and use the test results as the cascading threshold. We show that our model cascading strategy reduces computational costs while increases accuracy compared to generating the output with a single model. We also introduce a heuristics to determine the optimal combination of the number of solutions, test cases, and test lines each model should generate, based on the budget. Compared to speculative decoding, our method works on black-box models, having the same level of cost-accuracy trade-off, yet providing much more choices based on the server's budget. Ours is the first work to optimize cost-accuracy trade-off for LLM code generation with model cascading.
VeriGen: A Large Language Model for Verilog Code Generation
Jul 28, 2023



In this study, we explore the capability of Large Language Models (LLMs) to automate hardware design by generating high-quality Verilog code, a common language for designing and modeling digital systems. We fine-tune pre-existing LLMs on Verilog datasets compiled from GitHub and Verilog textbooks. We evaluate the functional correctness of the generated Verilog code using a specially designed test suite, featuring a custom problem set and testing benches. Here, our fine-tuned open-source CodeGen-16B model outperforms the commercial state-of-the-art GPT-3.5-turbo model with a 1.1% overall increase. Upon testing with a more diverse and complex problem set, we find that the fine-tuned model shows competitive performance against state-of-the-art gpt-3.5-turbo, excelling in certain scenarios. Notably, it demonstrates a 41% improvement in generating syntactically correct Verilog code across various problem categories compared to its pre-trained counterpart, highlighting the potential of smaller, in-house LLMs in hardware design automation.
LLM-assisted Generation of Hardware Assertions
Jun 24, 2023



The security of computer systems typically relies on a hardware root of trust. As vulnerabilities in hardware can have severe implications on a system, there is a need for techniques to support security verification activities. Assertion-based verification is a popular verification technique that involves capturing design intent in a set of assertions that can be used in formal verification or testing-based checking. However, writing security-centric assertions is a challenging task. In this work, we investigate the use of emerging large language models (LLMs) for code generation in hardware assertion generation for security, where primarily natural language prompts, such as those one would see as code comments in assertion files, are used to produce SystemVerilog assertions. We focus our attention on a popular LLM and characterize its ability to write assertions out of the box, given varying levels of detail in the prompt. We design an evaluation framework that generates a variety of prompts, and we create a benchmark suite comprising real-world hardware designs and corresponding golden reference assertions that we want to generate with the LLM.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
Can deepfakes be created by novice users?
Apr 28, 2023



Recent advancements in machine learning and computer vision have led to the proliferation of Deepfakes. As technology democratizes over time, there is an increasing fear that novice users can create Deepfakes, to discredit others and undermine public discourse. In this paper, we conduct user studies to understand whether participants with advanced computer skills and varying levels of computer science expertise can create Deepfakes of a person saying a target statement using limited media files. We conduct two studies; in the first study (n = 39) participants try creating a target Deepfake in a constrained time frame using any tool they desire. In the second study (n = 29) participants use pre-specified deep learning-based tools to create the same Deepfake. We find that for the first study, 23.1% of the participants successfully created complete Deepfakes with audio and video, whereas, for the second user study, 58.6% of the participants were successful in stitching target speech to the target video. We further use Deepfake detection software tools as well as human examiner-based analysis, to classify the successfully generated Deepfake outputs as fake, suspicious, or real. The software detector classified 80% of the Deepfakes as fake, whereas the human examiners classified 100% of the videos as fake. We conclude that creating Deepfakes is a simple enough task for a novice user given adequate tools and time; however, the resulting Deepfakes are not sufficiently real-looking and are unable to completely fool detection software as well as human examiners
Beyond the C: Retargetable Decompilation using Neural Machine Translation
Dec 17, 2022
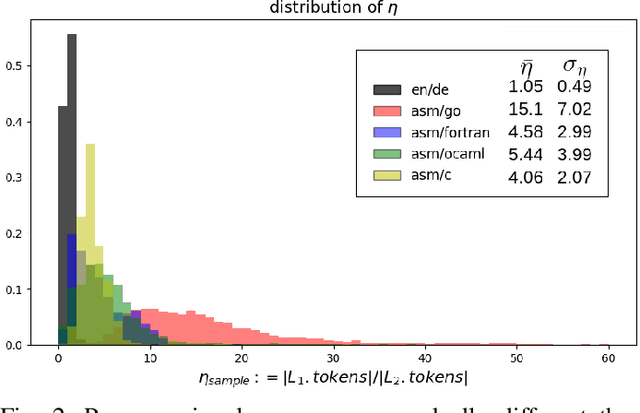
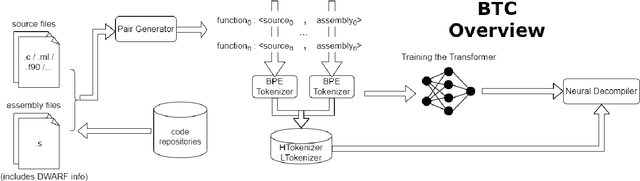
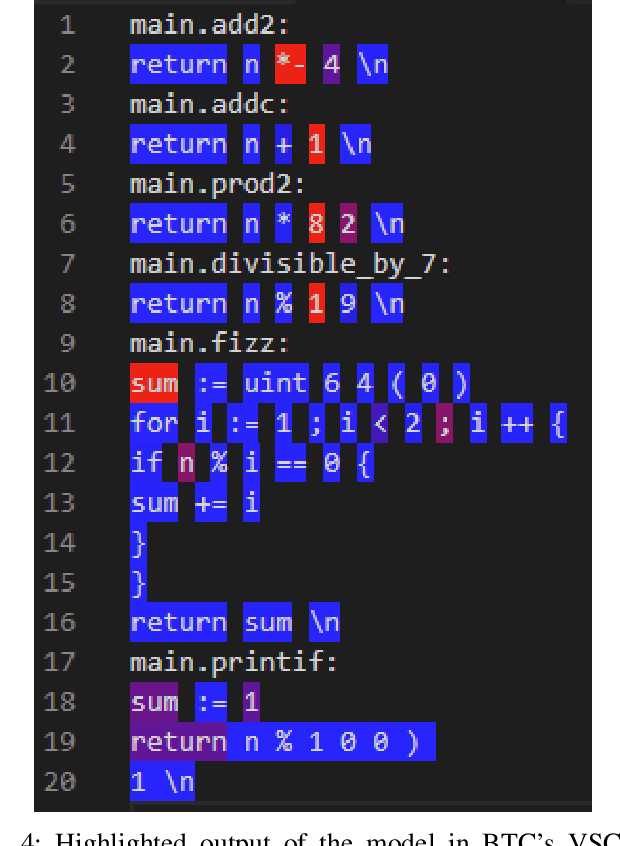
The problem of reversing the compilation process, decompilation, is an important tool in reverse engineering of computer software. Recently, researchers have proposed using techniques from neural machine translation to automate the process in decompilation. Although such techniques hold the promise of targeting a wider range of source and assembly languages, to date they have primarily targeted C code. In this paper we argue that existing neural decompilers have achieved higher accuracy at the cost of requiring language-specific domain knowledge such as tokenizers and parsers to build an abstract syntax tree (AST) for the source language, which increases the overhead of supporting new languages. We explore a different tradeoff that, to the extent possible, treats the assembly and source languages as plain text, and show that this allows us to build a decompiler that is easily retargetable to new languages. We evaluate our prototype decompiler, Beyond The C (BTC), on Go, Fortran, OCaml, and C, and examine the impact of parameters such as tokenization and training data selection on the quality of decompilation, finding that it achieves comparable decompilation results to prior work in neural decompilation with significantly less domain knowledge. We will release our training data, trained decompilation models, and code to help encourage future research into language-agnostic decompilation.