 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents Learn Their Runtime: Interpreter Persistence as Training-Time Semantics
Mar 05, 2026Tool-augmented LLMs are increasingly deployed as agents that interleave natural-language reasoning with executable Python actions, as in CodeAct-style frameworks. In deployment, these agents rely on runtime state that persists across steps. By contrast, the traces used to post-train these models rarely encode how interpreter state is managed. We ask whether interpreter persistence is merely a runtime scaffold, or a property of the training data that shapes how agents learn to use the interpreter. We isolate state persistence as a training-time variable. We introduce Opaque Knapsack, a procedurally generated family of partially observable optimization tasks designed to prevent one-shot solutions. Item attributes and constraints are hidden behind budgeted tool calls, forcing multi-turn control flow and iterative state revision. Holding task instances, prompts, tools, model, and supervision fixed, we generate matched trajectories differing only in whether interpreter state persists across steps or resets after each action. We then fine-tune identical base models (Qwen3-8B) on each trace variant and evaluate all four train-runtime combinations. Our 2x2 cross-evaluation shows that interpreter persistence shapes how agents reach solutions, not whether they do: solution quality is statistically indistinguishable across conditions, but token cost and stability differ substantially. A persistent-trained model in a stateless runtime triggers missing-variable errors in roughly 80% of episodes; a stateless-trained model in a persistent runtime redundantly re-derives retained state, using roughly 3.5x more tokens. Interpreter persistence should be treated as a first-class semantic of agent traces. Aligning fine-tuning data with deployment runtimes improves efficiency and reduces brittle train-runtime mismatches.
FreshBrew: A Benchmark for Evaluating AI Agents on Java Code Migration
Oct 06, 2025



AI coding assistants are rapidly becoming integral to modern software development. A key challenge in this space is the continual need to migrate and modernize codebases in response to evolving software ecosystems. Traditionally, such migrations have relied on rule-based systems and human intervention. With the advent of powerful large language models (LLMs), AI-driven agentic frameworks offer a promising alternative-but their effectiveness has not been systematically evaluated. In this paper, we introduce FreshBrew, a novel benchmark for evaluating AI agents on project-level Java migrations, with a specific focus on measuring an agent's ability to preserve program semantics and avoid reward hacking, which we argue requires projects with high test coverage for a rigorous and reliable evaluation. We benchmark several state-of-the-art LLMs, and compare their performance against established rule-based tools. Our evaluation of AI agents on this benchmark of 228 repositories shows that the top-performing model, Gemini 2.5 Flash, can successfully migrate 52.3 percent of projects to JDK 17. Our empirical analysis reveals novel insights into the critical strengths and limitations of current agentic approaches, offering actionable insights into their real-world applicability. Our empirical study reveals failure modes of current AI agents in realistic Java modernization tasks, providing a foundation for evaluating trustworthy code-migration systems. By releasing FreshBrew, we aim to facilitate rigorous, reproducible evaluation and catalyze progress in AI-driven codebase modernization.
GitChameleon: Evaluating AI Code Generation Against Python Library Version Incompatibilities
Jul 16, 2025



The rapid evolution of software libraries poses a considerable hurdle for code generation, necessitating continuous adaptation to frequent version updates while preserving backward compatibility. While existing code evolution benchmarks provide valuable insights, they typically lack execution-based evaluation for generating code compliant with specific library versions. To address this, we introduce GitChameleon, a novel, meticulously curated dataset comprising 328 Python code completion problems, each conditioned on specific library versions and accompanied by executable unit tests. GitChameleon rigorously evaluates the capacity of contemporary large language models (LLMs), LLM-powered agents, code assistants, and RAG systems to perform version-conditioned code generation that demonstrates functional accuracy through execution. Our extensive evaluations indicate that state-of-the-art systems encounter significant challenges with this task; enterprise models achieving baseline success rates in the 48-51\% range, underscoring the intricacy of the problem. By offering an execution-based benchmark emphasizing the dynamic nature of code libraries, GitChameleon enables a clearer understanding of this challenge and helps guide the development of more adaptable and dependable AI code generation methods. We make the dataset and evaluation code publicly available at https://github.com/mrcabbage972/GitChameleonBenchmark.
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Mar 30, 2024



Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
An algorithm for improving Non-Local Means operators via low-rank approximation
Nov 20, 2014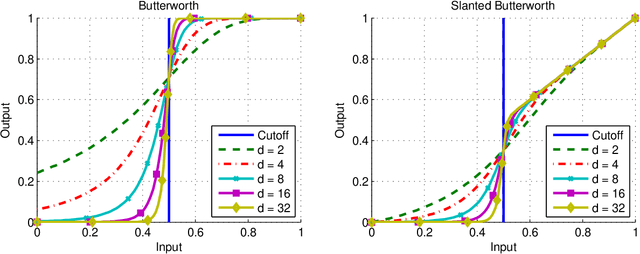
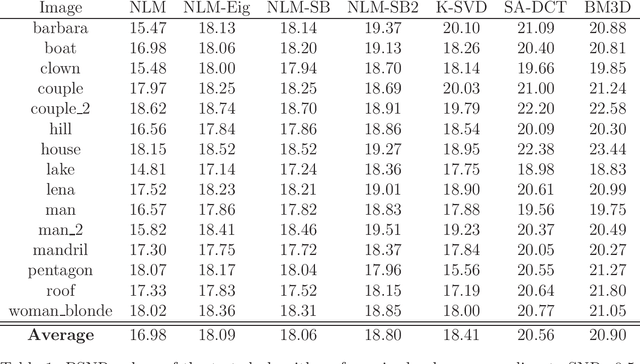
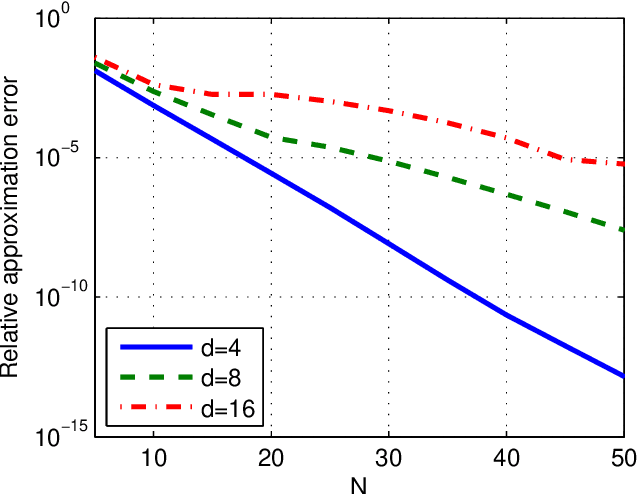
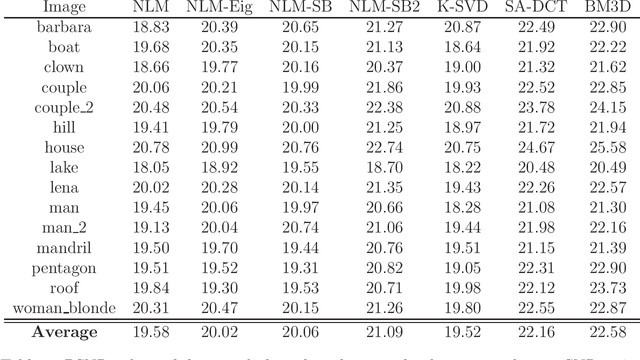
We present a method for improving a Non Local Means operator by computing its low-rank approximation. The low-rank operator is constructed by applying a filter to the spectrum of the original Non Local Means operator. This results in an operator which is less sensitive to noise while preserving important properties of the original operator. The method is efficiently implemented based on Chebyshev polynomials and is demonstrated on the application of natural images denoising. For this application, we provide a comprehensive comparison of our method with leading denoising methods.