 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Motion Synthesis via Applying Rotated Dual-Pixel Blur Kernels
Nov 15, 2021
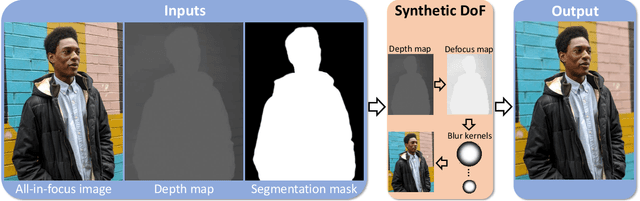
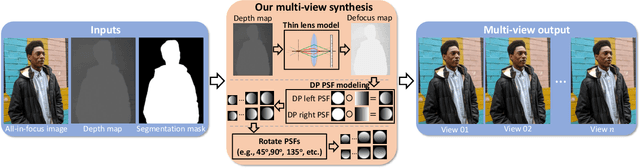
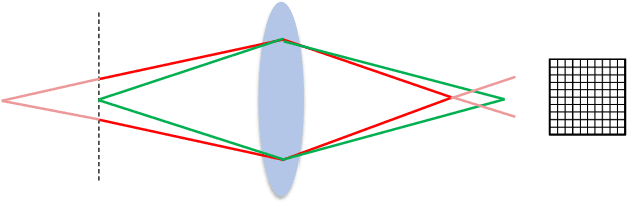
Portrait mode is widely available on smartphone cameras to provide an enhanced photographic experience. One of the primary effects applied to images captured in portrait mode is a synthetic shallow depth of field (DoF). The synthetic DoF (or bokeh effect) selectively blurs regions in the image to emulate the effect of using a large lens with a wide aperture. In addition, many applications now incorporate a new image motion attribute (NIMAT) to emulate background motion, where the motion is correlated with estimated depth at each pixel. In this work, we follow the trend of rendering the NIMAT effect by introducing a modification on the blur synthesis procedure in portrait mode. In particular, our modification enables a high-quality synthesis of multi-view bokeh from a single image by applying rotated blurring kernels. Given the synthesized multiple views, we can generate aesthetically realistic image motion similar to the NIMAT effect. We validate our approach qualitatively compared to the original NIMAT effect and other similar image motions, like Facebook 3D image. Our image motion demonstrates a smooth image view transition with fewer artifacts around the object boundary.
Auto White-Balance Correction for Mixed-Illuminant Scenes
Oct 08, 2021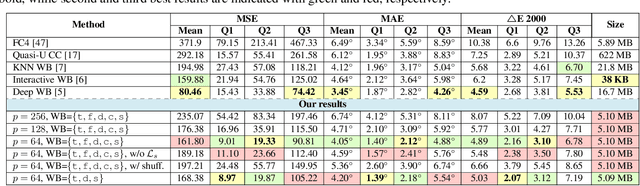

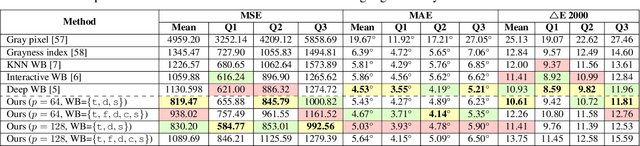

Auto white balance (AWB) is applied by camera hardware at capture time to remove the color cast caused by the scene illumination. The vast majority of white-balance algorithms assume a single light source illuminates the scene; however, real scenes often have mixed lighting conditions. This paper presents an effective AWB method to deal with such mixed-illuminant scenes. A unique departure from conventional AWB, our method does not require illuminant estimation, as is the case in traditional camera AWB modules. Instead, our method proposes to render the captured scene with a small set of predefined white-balance settings. Given this set of rendered images, our method learns to estimate weighting maps that are used to blend the rendered images to generate the final corrected image. Through extensive experiments, we show this proposed method produces promising results compared to other alternatives for single- and mixed-illuminant scene color correction. Our source code and trained models are available at https://github.com/mahmoudnafifi/mixedillWB.
Improving Single-Image Defocus Deblurring: How Dual-Pixel Images Help Through Multi-Task Learning
Aug 11, 2021

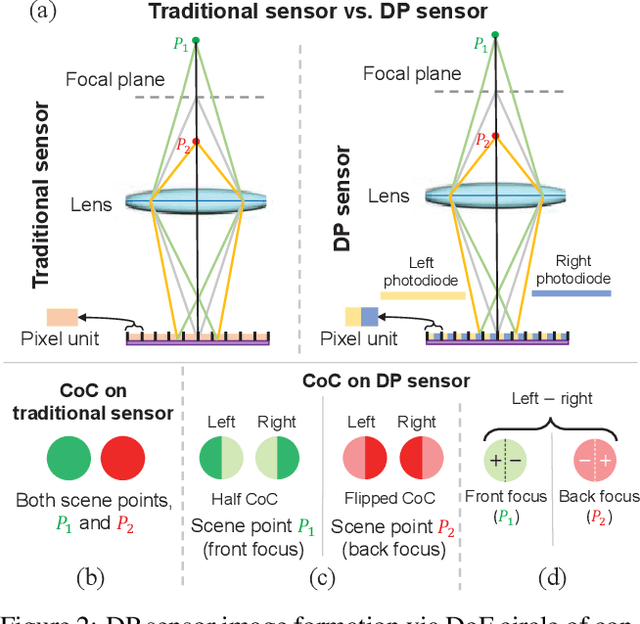
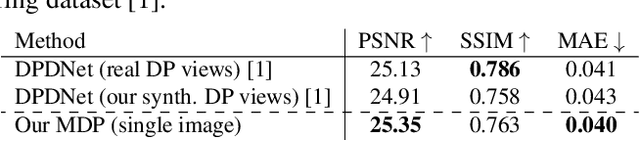
Many camera sensors use a dual-pixel (DP) design that operates as a rudimentary light field providing two sub-aperture views of a scene in a single capture. The DP sensor was developed to improve how cameras perform autofocus. Since the DP sensor's introduction, researchers have found additional uses for the DP data, such as depth estimation, reflection removal, and defocus deblurring. We are interested in the latter task of defocus deblurring. In particular, we propose a single-image deblurring network that incorporates the two sub-aperture views into a multi-task framework. Specifically, we show that jointly learning to predict the two DP views from a single blurry input image improves the network's ability to learn to deblur the image. Our experiments show this multi-task strategy achieves +1dB PSNR improvement over state-of-the-art defocus deblurring methods. In addition, our multi-task framework allows accurate DP-view synthesis (e.g., ~ 39dB PSNR) from the single input image. These high-quality DP views can be used for other DP-based applications, such as reflection removal. As part of this effort, we have captured a new dataset of 7,059 high-quality images to support our training for the DP-view synthesis task. Our dataset, code, and trained models will be made publicly available at https://github.com/Abdullah-Abuolaim/multi-task-defocus-deblurring-dual-pixel-nimat
Image color correction, enhancement, and editing
Jul 28, 2021This thesis presents methods and approaches to image color correction, color enhancement, and color editing. To begin, we study the color correction problem from the standpoint of the camera's image signal processor (ISP). A camera's ISP is hardware that applies a series of in-camera image processing and color manipulation steps, many of which are nonlinear in nature, to render the initial sensor image to its final photo-finished representation saved in the 8-bit standard RGB (sRGB) color space. As white balance (WB) is one of the major procedures applied by the ISP for color correction, this thesis presents two different methods for ISP white balancing. Afterward, we discuss another scenario of correcting and editing image colors, where we present a set of methods to correct and edit WB settings for images that have been improperly white-balanced by the ISP. Then, we explore another factor that has a significant impact on the quality of camera-rendered colors, in which we outline two different methods to correct exposure errors in camera-rendered images. Lastly, we discuss post-capture auto color editing and manipulation. In particular, we propose auto image recoloring methods to generate different realistic versions of the same camera-rendered image with new colors. Through extensive evaluations, we demonstrate that our methods provide superior solutions compared to existing alternatives targeting color correction, color enhancement, and color editing.
Semi-Supervised Raw-to-Raw Mapping
Jun 29, 2021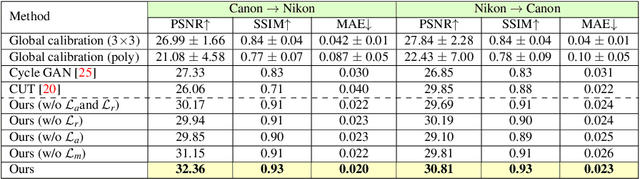
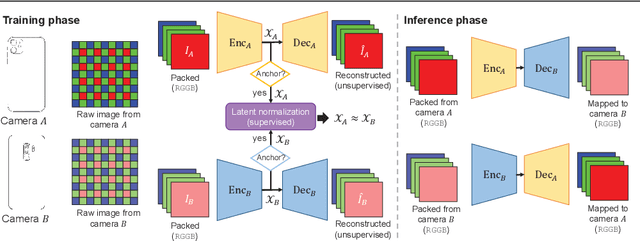
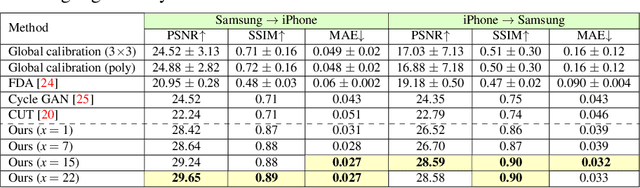

The raw-RGB colors of a camera sensor vary due to the spectral sensitivity differences across different sensor makes and models. This paper focuses on the task of mapping between different sensor raw-RGB color spaces. Prior work addressed this problem using a pairwise calibration to achieve accurate color mapping. Although being accurate, this approach is less practical as it requires: (1) capturing pair of images by both camera devices with a color calibration object placed in each new scene; (2) accurate image alignment or manual annotation of the color calibration object. This paper aims to tackle color mapping in the raw space through a more practical setup. Specifically, we present a semi-supervised raw-to-raw mapping method trained on a small set of paired images alongside an unpaired set of images captured by each camera device. Through extensive experiments, we show that our method achieves better results compared to other domain adaptation alternatives in addition to the single-calibration solution. We have generated a new dataset of raw images from two different smartphone cameras as part of this effort. Our dataset includes unpaired and paired sets for our semi-supervised training and evaluation.
CAMS: Color-Aware Multi-Style Transfer
Jun 26, 2021
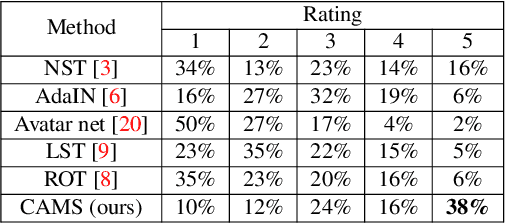

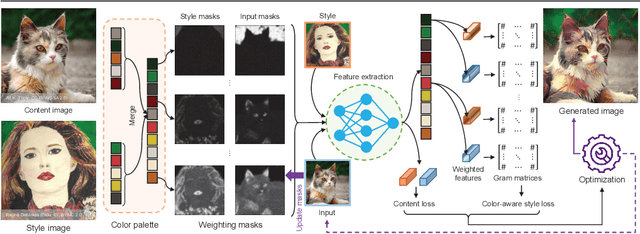
Image style transfer aims to manipulate the appearance of a source image, or "content" image, to share similar texture and colors of a target "style" image. Ideally, the style transfer manipulation should also preserve the semantic content of the source image. A commonly used approach to assist in transferring styles is based on Gram matrix optimization. One problem of Gram matrix-based optimization is that it does not consider the correlation between colors and their styles. Specifically, certain textures or structures should be associated with specific colors. This is particularly challenging when the target style image exhibits multiple style types. In this work, we propose a color-aware multi-style transfer method that generates aesthetically pleasing results while preserving the style-color correlation between style and generated images. We achieve this desired outcome by introducing a simple but efficient modification to classic Gram matrix-based style transfer optimization. A nice feature of our method is that it enables the users to manually select the color associations between the target style and content image for more transfer flexibility. We validated our method with several qualitative comparisons, including a user study conducted with 30 participants. In comparison with prior work, our method is simple, easy to implement, and achieves visually appealing results when targeting images that have multiple styles. Source code is available at https://github.com/mahmoudnafifi/color-aware-style-transfer.
Cross-Camera Convolutional Color Constancy
Nov 24, 2020
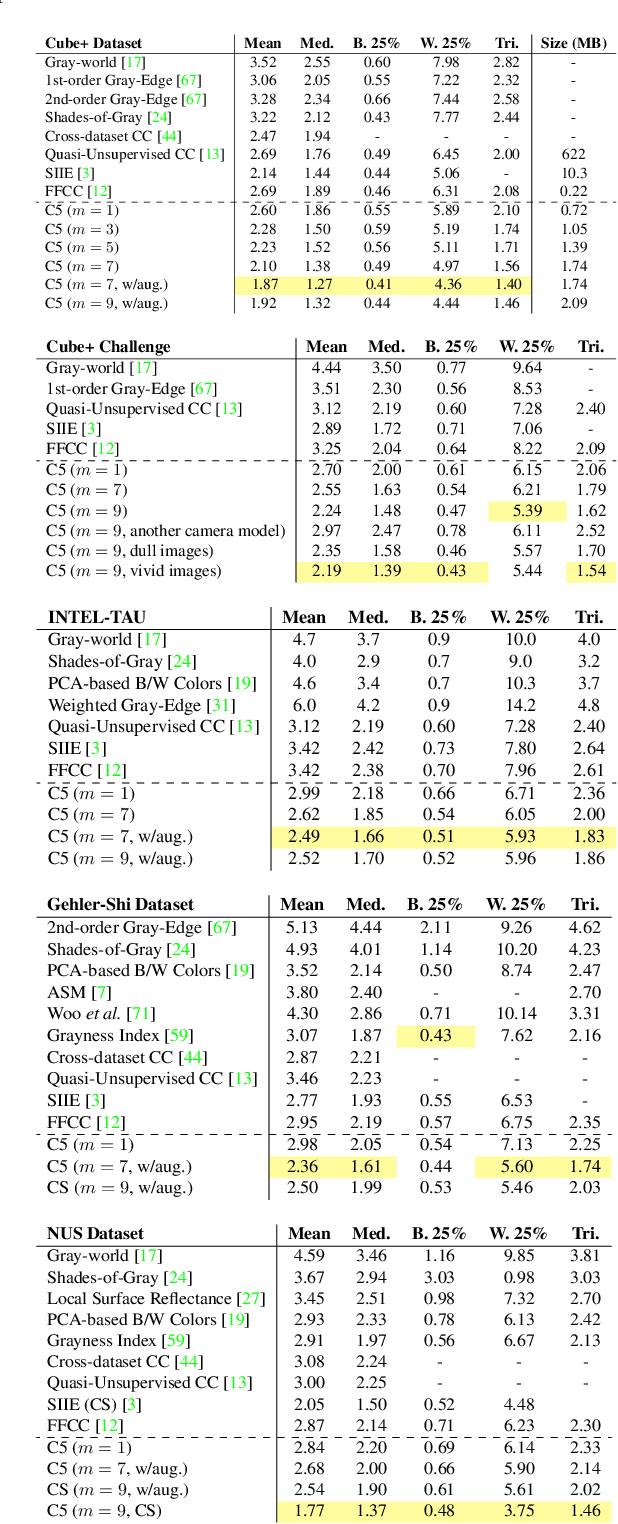
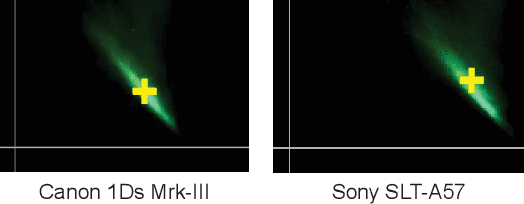
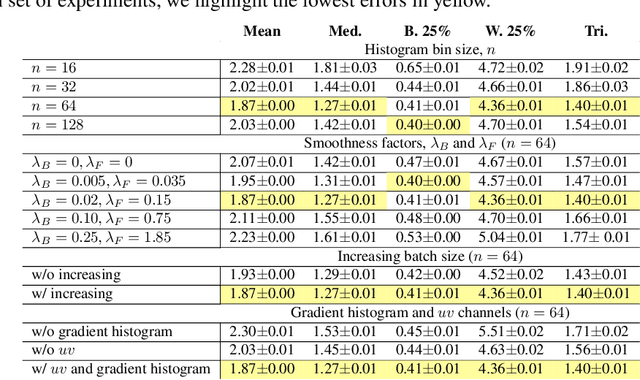
We present "Cross-Camera Convolutional Color Constancy" (C5), a learning-based method, trained on images from multiple cameras, that accurately estimates a scene's illuminant color from raw images captured by a new camera previously unseen during training. C5 is a hypernetwork-like extension of the convolutional color constancy (CCC) approach: C5 learns to generate the weights of a CCC model that is then evaluated on the input image, with the CCC weights dynamically adapted to different input content. Unlike prior cross-camera color constancy models, which are usually designed to be agnostic to the spectral properties of test-set images from unobserved cameras, C5 approaches this problem through the lens of transductive inference: additional unlabeled images are provided as input to the model at test time, which allows the model to calibrate itself to the spectral properties of the test-set camera during inference. C5 achieves state-of-the-art accuracy for cross-camera color constancy on several datasets, is fast to evaluate (~7 and ~90 ms per image on a GPU or CPU, respectively), and requires little memory (~2 MB), and, thus, is a practical solution to the problem of calibration-free automatic white balance for mobile photography.
HistoGAN: Controlling Colors of GAN-Generated and Real Images via Color Histograms
Nov 23, 2020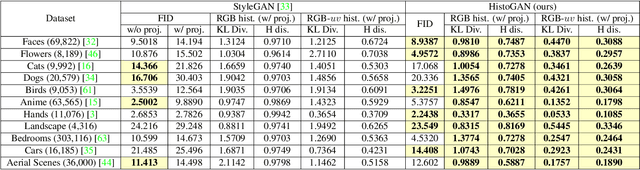
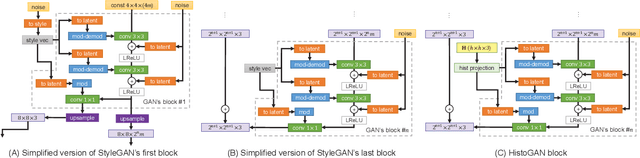

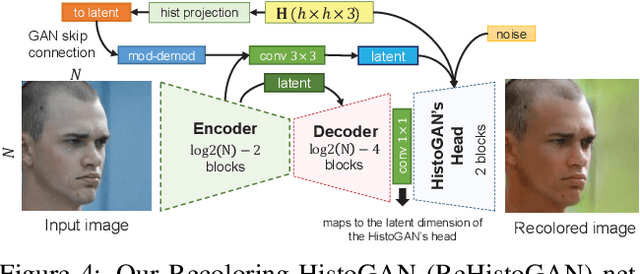
While generative adversarial networks (GANs) can successfully produce high-quality images, they can be challenging to control. Simplifying GAN-based image generation is critical for their adoption in graphic design and artistic work. This goal has led to significant interest in methods that can intuitively control the appearance of images generated by GANs. In this paper, we present HistoGAN, a color histogram-based method for controlling GAN-generated images' colors. We focus on color histograms as they provide an intuitive way to describe image color while remaining decoupled from domain-specific semantics. Specifically, we introduce an effective modification of the recent StyleGAN architecture to control the colors of GAN-generated images specified by a target color histogram feature. We then describe how to expand HistoGAN to recolor real images. For image recoloring, we jointly train an encoder network along with HistoGAN. The recoloring model, ReHistoGAN, is an unsupervised approach trained to encourage the network to keep the original image's content while changing the colors based on the given target histogram. We show that this histogram-based approach offers a better way to control GAN-generated and real images' colors while producing more compelling results compared to existing alternative strategies.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020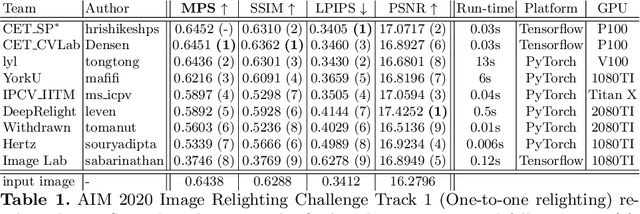

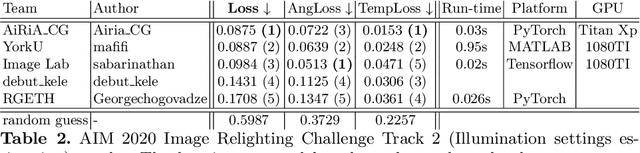

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
Interactive White Balancing for Camera-Rendered Images
Sep 26, 2020
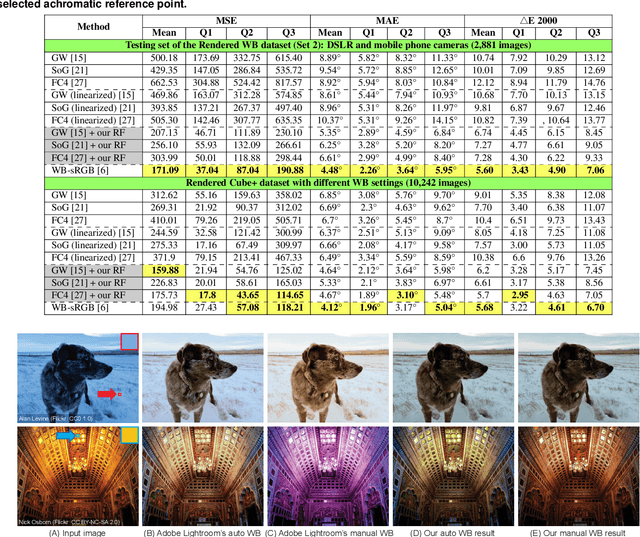
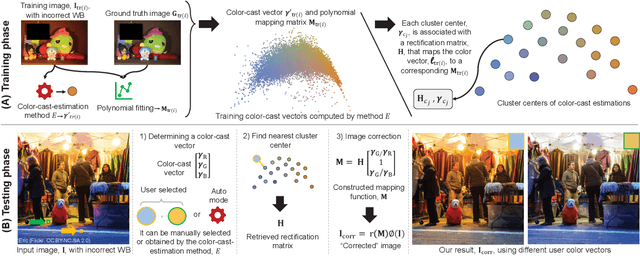

White balance (WB) is one of the first photo-finishing steps used to render a captured image to its final output. WB is applied to remove the color cast caused by the scene's illumination. Interactive photo-editing software allows users to manually select different regions in a photo as examples of the illumination for WB correction (e.g., clicking on achromatic objects). Such interactive editing is possible only with images saved in a RAW image format. This is because RAW images have no photo-rendering operations applied and photo-editing software is able to apply WB and other photo-finishing procedures to render the final image. Interactively editing WB in camera-rendered images is significantly more challenging. This is because the camera hardware has already applied WB to the image and subsequent nonlinear photo-processing routines. These nonlinear rendering operations make it difficult to change the WB post-capture. The goal of this paper is to allow interactive WB manipulation of camera-rendered images. The proposed method is an extension of our recent work \cite{afifi2019color} that proposed a post-capture method for WB correction based on nonlinear color-mapping functions. Here, we introduce a new framework that links the nonlinear color-mapping functions directly to user-selected colors to enable {\it interactive} WB manipulation. This new framework is also more efficient in terms of memory and run-time (99\% reduction in memory and 3$\times$ speed-up). Lastly, we describe how our framework can leverage a simple illumination estimation method (i.e., gray-world) to perform auto-WB correction that is on a par with the WB correction results in \cite{afifi2019color}. The source code is publicly available at https://github.com/mahmoudnafifi/Interactive_WB_correction.