 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBurstGP: Enhancing Raw Burst Image Super Resolution with Generative Priors
Apr 26, 2026Burst image super resolution (BISR) aims to construct a single high-resolution (HR) image by aggregating information from multiple low-resolution (LR) frames, relying on temporal redundancy and spatial coherence across the burst. While conventional methods achieve impressive results, they often struggle with complex textures and oversmoothing. Diffusion models, particularly those pretrained on high-quality data, have shown remarkable capability in generating realistic details for image and video super-resolution. However, their potential remains largely under-explored in BISR, where existing approaches typically rely on task-specific diffusion models trained from scratch and operate on single-frame reconstructions. In this work, we propose BurstGP, a novel diffusion-based solution for BISR, which leverages generative priors of recent foundation models to overcome these issues. In particular, we build a multiframe-aware diffusion model on top of a conventional BISR approach, which boosts image quality with minimal loss to fidelity. Further, we introduce (i) a novel degradation-aware conditioning mechanism, which controls synthesis of fine details based on the estimated degradation in the input, and (ii) a robust sRGB-to-lRGB inverter, enabling us to utilize generative multiframe (video) sRGB priors, while operating with raw input and lRGB output images. Empirically, we demonstrate that BurstGP outperforms the existing state of the art, both quantitatively (especially with respect to perceptual metrics, including MUSIQ and LPIPS) and qualitatively. In particular, our proposed method excels at recovering richer textures and finer structural details, highlighting the potential of video priors for BISR over traditional methods.
Zero-Shot Personalization of Objects via Textual Inversion
Mar 24, 2026Recent advances in text-to-image diffusion models have substantially improved the quality of image customization, enabling the synthesis of highly realistic images. Despite this progress, achieving fast and efficient personalization remains a key challenge, particularly for real-world applications. Existing approaches primarily accelerate customization for human subjects by injecting identity-specific embeddings into diffusion models, but these strategies do not generalize well to arbitrary object categories, limiting their applicability. To address this limitation, we propose a novel framework that employs a learned network to predict object-specific textual inversion embeddings, which are subsequently integrated into the UNet timesteps of a diffusion model for text-conditional customization. This design enables rapid, zero-shot personalization of a wide range of objects in a single forward pass, offering both flexibility and scalability. Extensive experiments across multiple tasks and settings demonstrate the effectiveness of our approach, highlighting its potential to support fast, versatile, and inclusive image customization. To the best of our knowledge, this work represents the first attempt to achieve such general-purpose, training-free personalization within diffusion models, paving the way for future research in personalized image generation.
Face2Scene: Using Facial Degradation as an Oracle for Diffusion-Based Scene Restoration
Mar 17, 2026Recent advances in image restoration have enabled high-fidelity recovery of faces from degraded inputs using reference-based face restoration models (Ref-FR). However, such methods focus solely on facial regions, neglecting degradation across the full scene, including body and background, which limits practical usability. Meanwhile, full-scene restorers often ignore degradation cues entirely, leading to underdetermined predictions and visual artifacts. In this work, we propose Face2Scene, a two-stage restoration framework that leverages the face as a perceptual oracle to estimate degradation and guide the restoration of the entire image. Given a degraded image and one or more identity references, we first apply a Ref-FR model to reconstruct high-quality facial details. From the restored-degraded face pair, we extract a face-derived degradation code that captures degradation attributes (e.g., noise, blur, compression), which is then transformed into multi-scale degradation-aware tokens. These tokens condition a diffusion model to restore the full scene in a single step, including the body and background. Extensive experiments demonstrate the superior effectiveness of the proposed method compared to state-of-the-art methods.
MultLFG: Training-free Multi-LoRA composition using Frequency-domain Guidance
May 26, 2025



Low-Rank Adaptation (LoRA) has gained prominence as a computationally efficient method for fine-tuning generative models, enabling distinct visual concept synthesis with minimal overhead. However, current methods struggle to effectively merge multiple LoRA adapters without training, particularly in complex compositions involving diverse visual elements. We introduce MultLFG, a novel framework for training-free multi-LoRA composition that utilizes frequency-domain guidance to achieve adaptive fusion of multiple LoRAs. Unlike existing methods that uniformly aggregate concept-specific LoRAs, MultLFG employs a timestep and frequency subband adaptive fusion strategy, selectively activating relevant LoRAs based on content relevance at specific timesteps and frequency bands. This frequency-sensitive guidance not only improves spatial coherence but also provides finer control over multi-LoRA composition, leading to more accurate and consistent results. Experimental evaluations on the ComposLoRA benchmark reveal that MultLFG substantially enhances compositional fidelity and image quality across various styles and concept sets, outperforming state-of-the-art baselines in multi-concept generation tasks. Code will be released.
Spatially-Attentive Patch-Hierarchical Network with Adaptive Sampling for Motion Deblurring
Feb 09, 2024



This paper tackles the problem of motion deblurring of dynamic scenes. Although end-to-end fully convolutional designs have recently advanced the state-of-the-art in non-uniform motion deblurring, their performance-complexity trade-off is still sub-optimal. Most existing approaches achieve a large receptive field by increasing the number of generic convolution layers and kernel size. In this work, we propose a pixel adaptive and feature attentive design for handling large blur variations across different spatial locations and process each test image adaptively. We design a content-aware global-local filtering module that significantly improves performance by considering not only global dependencies but also by dynamically exploiting neighboring pixel information. We further introduce a pixel-adaptive non-uniform sampling strategy that implicitly discovers the difficult-to-restore regions present in the image and, in turn, performs fine-grained refinement in a progressive manner. Extensive qualitative and quantitative comparisons with prior art on deblurring benchmarks demonstrate that our approach performs favorably against the state-of-the-art deblurring algorithms.
CLR-Face: Conditional Latent Refinement for Blind Face Restoration Using Score-Based Diffusion Models
Feb 08, 2024



Recent generative-prior-based methods have shown promising blind face restoration performance. They usually project the degraded images to the latent space and then decode high-quality faces either by single-stage latent optimization or directly from the encoding. Generating fine-grained facial details faithful to inputs remains a challenging problem. Most existing methods produce either overly smooth outputs or alter the identity as they attempt to balance between generation and reconstruction. This may be attributed to the typical trade-off between quality and resolution in the latent space. If the latent space is highly compressed, the decoded output is more robust to degradations but shows worse fidelity. On the other hand, a more flexible latent space can capture intricate facial details better, but is extremely difficult to optimize for highly degraded faces using existing techniques. To address these issues, we introduce a diffusion-based-prior inside a VQGAN architecture that focuses on learning the distribution over uncorrupted latent embeddings. With such knowledge, we iteratively recover the clean embedding conditioning on the degraded counterpart. Furthermore, to ensure the reverse diffusion trajectory does not deviate from the underlying identity, we train a separate Identity Recovery Network and use its output to constrain the reverse diffusion process. Specifically, using a learnable latent mask, we add gradients from a face-recognition network to a subset of latent features that correlates with the finer identity-related details in the pixel space, leaving the other features untouched. Disentanglement between perception and fidelity in the latent space allows us to achieve the best of both worlds. We perform extensive evaluations on multiple real and synthetic datasets to validate the superiority of our approach.
Unsupervised network for low-light enhancement
Jun 05, 2023

Supervised networks address the task of low-light enhancement using paired images. However, collecting a wide variety of low-light/clean paired images is tedious as the scene needs to remain static during imaging. In this paper, we propose an unsupervised low-light enhancement network using contextguided illumination-adaptive norm (CIN). Inspired by coarse to fine methods, we propose to address this task in two stages. In stage-I, a pixel amplifier module (PAM) is used to generate a coarse estimate with an overall improvement in visibility and aesthetic quality. Stage-II further enhances the saturated dark pixels and scene properties of the image using CIN. Different ablation studies show the importance of PAM and CIN in improving the visible quality of the image. Next, we propose a region-adaptive single input multiple output (SIMO) model that can generate multiple enhanced images from a single lowlight image. The objective of SIMO is to let users choose the image of their liking from a pool of enhanced images. Human subjective analysis of SIMO results shows that the distribution of preferred images varies, endorsing the importance of SIMO-type models. Lastly, we propose a low-light road scene (LLRS) dataset having an unpaired collection of low-light and clean scenes. Unlike existing datasets, the clean and low-light scenes in LLRS are real and captured using fixed camera settings. Exhaustive comparisons on publicly available datasets, and the proposed dataset reveal that the results of our model outperform prior art quantitatively and qualitatively.
Exploring the Effectiveness of Mask-Guided Feature Modulation as a Mechanism for Localized Style Editing of Real Images
Dec 10, 2022The success of Deep Generative Models at high-resolution image generation has led to their extensive utilization for style editing of real images. Most existing methods work on the principle of inverting real images onto their latent space, followed by determining controllable directions. Both inversion of real images and determination of controllable latent directions are computationally expensive operations. Moreover, the determination of controllable latent directions requires additional human supervision. This work aims to explore the efficacy of mask-guided feature modulation in the latent space of a Deep Generative Model as a solution to these bottlenecks. To this end, we present the SemanticStyle Autoencoder (SSAE), a deep Generative Autoencoder model that leverages semantic mask-guided latent space manipulation for highly localized photorealistic style editing of real images. We present qualitative and quantitative results for the same and their analysis. This work shall serve as a guiding primer for future work.
Hybrid Transformer Based Feature Fusion for Self-Supervised Monocular Depth Estimation
Nov 20, 2022



With an unprecedented increase in the number of agents and systems that aim to navigate the real world using visual cues and the rising impetus for 3D Vision Models, the importance of depth estimation is hard to understate. While supervised methods remain the gold standard in the domain, the copious amount of paired stereo data required to train such models makes them impractical. Most State of the Art (SOTA) works in the self-supervised and unsupervised domain employ a ResNet-based encoder architecture to predict disparity maps from a given input image which are eventually used alongside a camera pose estimator to predict depth without direct supervision. The fully convolutional nature of ResNets makes them susceptible to capturing per-pixel local information only, which is suboptimal for depth prediction. Our key insight for doing away with this bottleneck is to use Vision Transformers, which employ self-attention to capture the global contextual information present in an input image. Our model fuses per-pixel local information learned using two fully convolutional depth encoders with global contextual information learned by a transformer encoder at different scales. It does so using a mask-guided multi-stream convolution in the feature space to achieve state-of-the-art performance on most standard benchmarks.
Image Restoration using Feature-guidance
Jan 01, 2022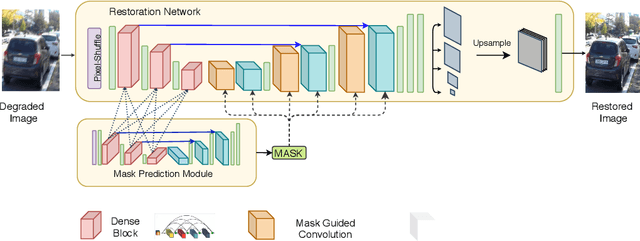



Image restoration is the task of recovering a clean image from a degraded version. In most cases, the degradation is spatially varying, and it requires the restoration network to both localize and restore the affected regions. In this paper, we present a new approach suitable for handling the image-specific and spatially-varying nature of degradation in images affected by practically occurring artifacts such as blur, rain-streaks. We decompose the restoration task into two stages of degradation localization and degraded region-guided restoration, unlike existing methods which directly learn a mapping between the degraded and clean images. Our premise is to use the auxiliary task of degradation mask prediction to guide the restoration process. We demonstrate that the model trained for this auxiliary task contains vital region knowledge, which can be exploited to guide the restoration network's training using attentive knowledge distillation technique. Further, we propose mask-guided convolution and global context aggregation module that focuses solely on restoring the degraded regions. The proposed approach's effectiveness is demonstrated by achieving significant improvement over strong baselines.