 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Grammar Competency Estimation Using Large Language Model Generated Pseudo Labels
Nov 17, 2025



Grammar competency estimation is essential for assessing linguistic proficiency in both written and spoken language; however, the spoken modality presents additional challenges due to its spontaneous, unstructured, and disfluent nature. Developing accurate grammar scoring models further requires extensive expert annotation, making large-scale data creation impractical. To address these limitations, we propose a zero-shot grammar competency estimation framework that leverages unlabeled data and Large Language Models (LLMs) without relying on manual labels. During training, we employ LLM-generated predictions on unlabeled data by using grammar competency rubric-based prompts. These predictions, treated as pseudo labels, are utilized to train a transformer-based model through a novel training framework designed to handle label noise effectively. We show that the choice of LLM for pseudo-label generation critically affects model performance and that the ratio of clean-to-noisy samples during training strongly influences stability and accuracy. Finally, a qualitative analysis of error intensity and score prediction confirms the robustness and interpretability of our approach. Experimental results demonstrate the efficacy of our approach in estimating grammar competency scores with high accuracy, paving the way for scalable, low-resource grammar assessment systems.
Unsupervised Out-of-Distribution Dialect Detection with Mahalanobis Distance
Aug 09, 2023Dialect classification is used in a variety of applications, such as machine translation and speech recognition, to improve the overall performance of the system. In a real-world scenario, a deployed dialect classification model can encounter anomalous inputs that differ from the training data distribution, also called out-of-distribution (OOD) samples. Those OOD samples can lead to unexpected outputs, as dialects of those samples are unseen during model training. Out-of-distribution detection is a new research area that has received little attention in the context of dialect classification. Towards this, we proposed a simple yet effective unsupervised Mahalanobis distance feature-based method to detect out-of-distribution samples. We utilize the latent embeddings from all intermediate layers of a wav2vec 2.0 transformer-based dialect classifier model for multi-task learning. Our proposed approach outperforms other state-of-the-art OOD detection methods significantly.
Can No-reference features help in Full-reference image quality estimation?
Mar 02, 2022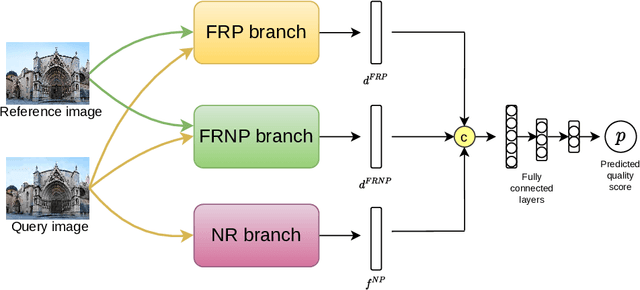
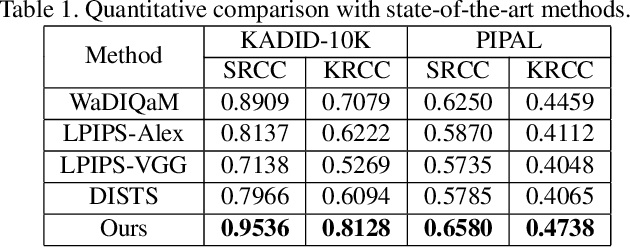

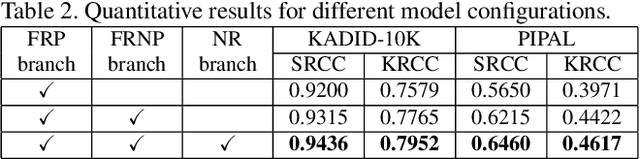
Development of perceptual image quality assessment (IQA) metrics has been of significant interest to computer vision community. The aim of these metrics is to model quality of an image as perceived by humans. Recent works in Full-reference IQA research perform pixelwise comparison between deep features corresponding to query and reference images for quality prediction. However, pixelwise feature comparison may not be meaningful if distortion present in query image is severe. In this context, we explore utilization of no-reference features in Full-reference IQA task. Our model consists of both full-reference and no-reference branches. Full-reference branches use both distorted and reference images, whereas No-reference branch only uses distorted image. Our experiments show that use of no-reference features boosts performance of image quality assessment. Our model achieves higher SRCC and KRCC scores than a number of state-of-the-art algorithms on KADID-10K and PIPAL datasets.
Anomaly Detection in Retinal Images using Multi-Scale Deep Feature Sparse Coding
Jan 27, 2022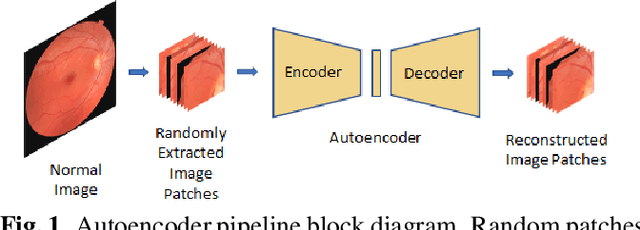
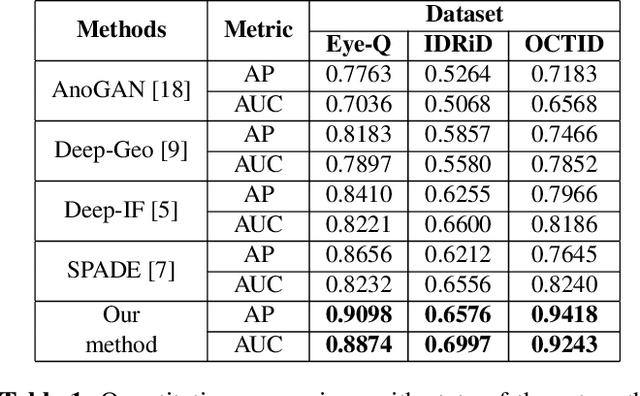
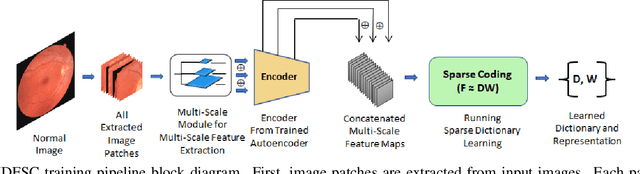
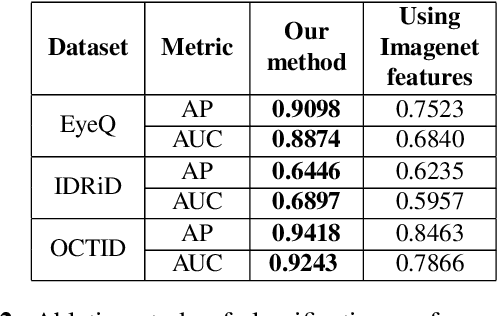
Convolutional Neural Network models have successfully detected retinal illness from optical coherence tomography (OCT) and fundus images. These CNN models frequently rely on vast amounts of labeled data for training, difficult to obtain, especially for rare diseases. Furthermore, a deep learning system trained on a data set with only one or a few diseases cannot detect other diseases, limiting the system's practical use in disease identification. We have introduced an unsupervised approach for detecting anomalies in retinal images to overcome this issue. We have proposed a simple, memory efficient, easy to train method which followed a multi-step training technique that incorporated autoencoder training and Multi-Scale Deep Feature Sparse Coding (MDFSC), an extended version of normal sparse coding, to accommodate diverse types of retinal datasets. We achieve relative AUC score improvement of 7.8\%, 6.7\% and 12.1\% over state-of-the-art SPADE on Eye-Q, IDRiD and OCTID datasets respectively.
AdvCodeMix: Adversarial Attack on Code-Mixed Data
Oct 30, 2021


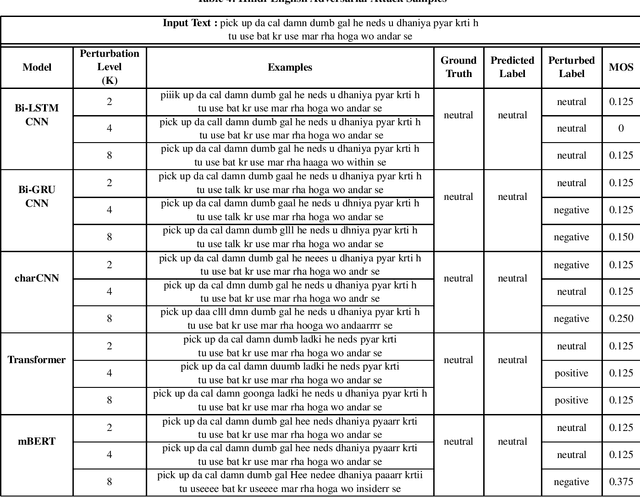
Research on adversarial attacks are becoming widely popular in the recent years. One of the unexplored areas where prior research is lacking is the effect of adversarial attacks on code-mixed data. Therefore, in the present work, we have explained the first generalized framework on text perturbation to attack code-mixed classification models in a black-box setting. We rely on various perturbation techniques that preserve the semantic structures of the sentences and also obscure the attacks from the perception of a human user. The present methodology leverages the importance of a token to decide where to attack by employing various perturbation strategies. We test our strategies on various sentiment classification models trained on Bengali-English and Hindi-English code-mixed datasets, and reduce their F1-scores by nearly 51 % and 53 % respectively, which can be further reduced if a larger number of tokens are perturbed in a given sentence.
Context-aware Retail Product Recommendation with Regularized Gradient Boosting
Sep 17, 2021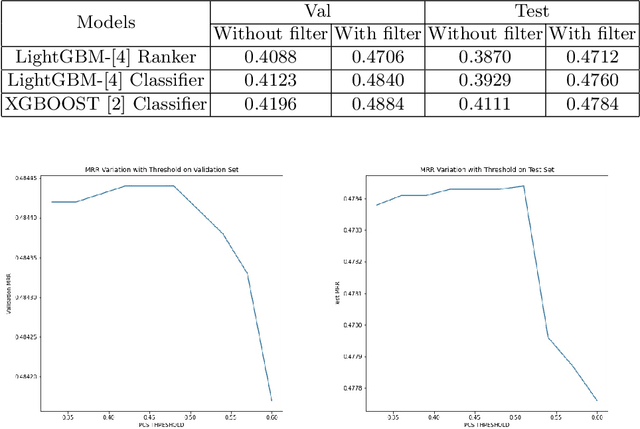
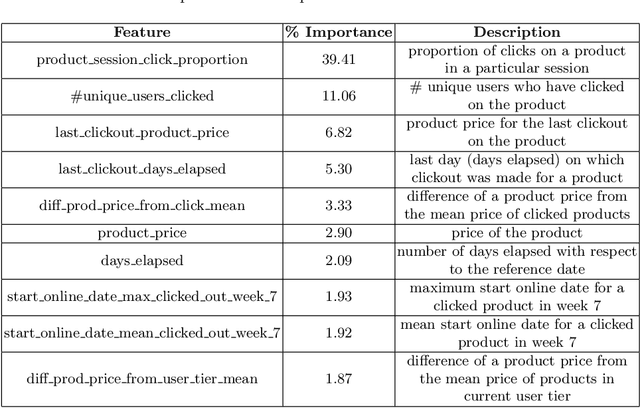
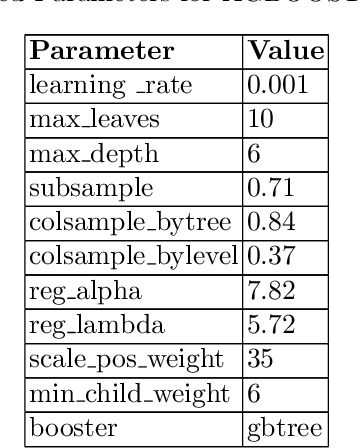
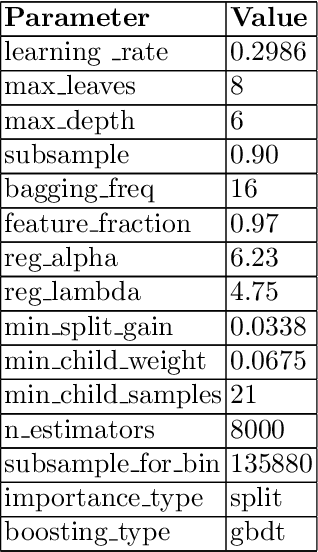
In the FARFETCH Fashion Recommendation challenge, the participants needed to predict the order in which various products would be shown to a user in a recommendation impression. The data was provided in two phases - a validation phase and a test phase. The validation phase had a labelled training set that contained a binary column indicating whether a product has been clicked or not. The dataset comprises over 5,000,000 recommendation events, 450,000 products and 230,000 unique users. It represents real, unbiased, but anonymised, interactions of actual users of the FARFETCH platform. The final evaluation was done according to the performance in the second phase. A total of 167 participants participated in the challenge, and we secured the 6th rank during the final evaluation with an MRR of 0.4658 on the test set. We have designed a unique context-aware system that takes the similarity of a product to the user context into account to rank products more effectively. Post evaluation, we have been able to fine-tune our approach with an MRR of 0.4784 on the test set, which would have placed us at the 3rd position.
MSR-Net: Multi-Scale Relighting Network for One-to-One Relighting
Jul 13, 2021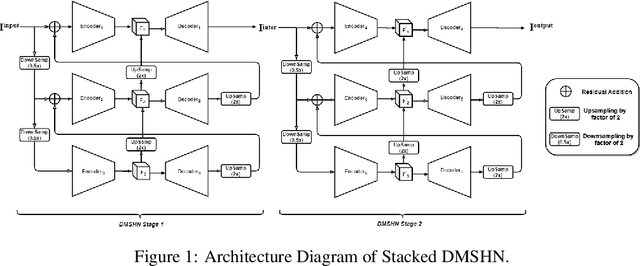


Deep image relighting allows photo enhancement by illumination-specific retouching without human effort and so it is getting much interest lately. Most of the existing popular methods available for relighting are run-time intensive and memory inefficient. Keeping these issues in mind, we propose the use of Stacked Deep Multi-Scale Hierarchical Network, which aggregates features from each image at different scales. Our solution is differentiable and robust for translating image illumination setting from input image to target image. Additionally, we have also shown that using a multi-step training approach to this problem with two different loss functions can significantly boost performance and can achieve a high quality reconstruction of a relighted image.
Fast and Accurate Quantized Camera Scene Detection on Smartphones, Mobile AI 2021 Challenge: Report
May 17, 2021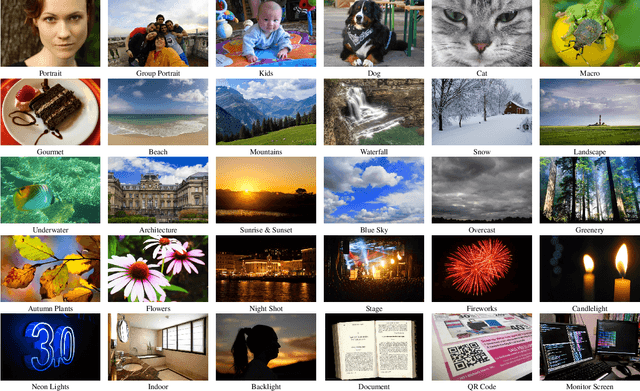
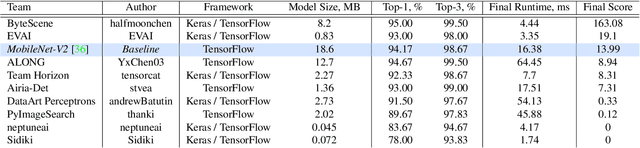

Camera scene detection is among the most popular computer vision problem on smartphones. While many custom solutions were developed for this task by phone vendors, none of the designed models were available publicly up until now. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop quantized deep learning-based camera scene classification solutions that can demonstrate a real-time performance on smartphones and IoT platforms. For this, the participants were provided with a large-scale CamSDD dataset consisting of more than 11K images belonging to the 30 most important scene categories. The runtime of all models was evaluated on the popular Apple Bionic A11 platform that can be found in many iOS devices. The proposed solutions are fully compatible with all major mobile AI accelerators and can demonstrate more than 100-200 FPS on the majority of recent smartphone platforms while achieving a top-3 accuracy of more than 98%. A detailed description of all models developed in the challenge is provided in this paper.
Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image
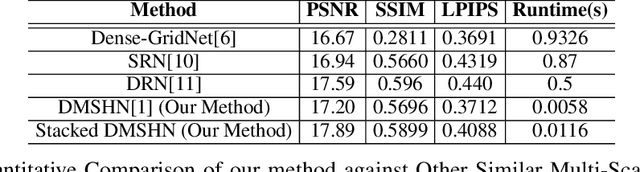
May 15, 2021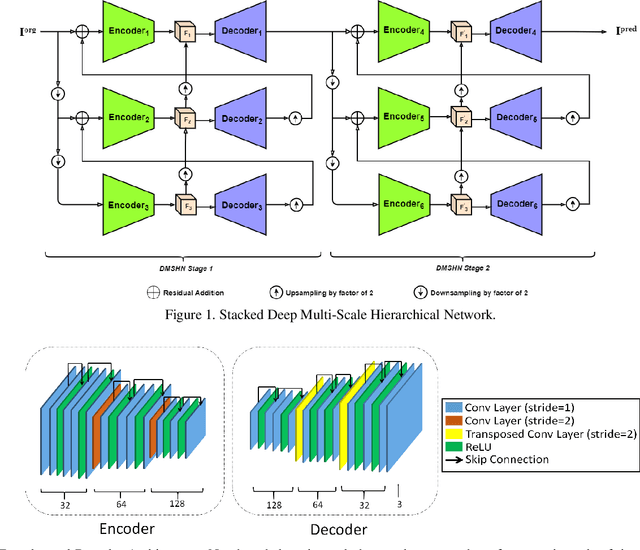
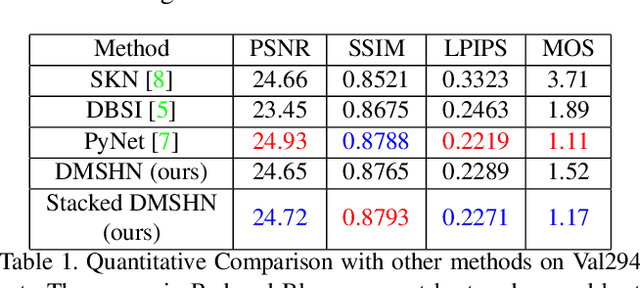
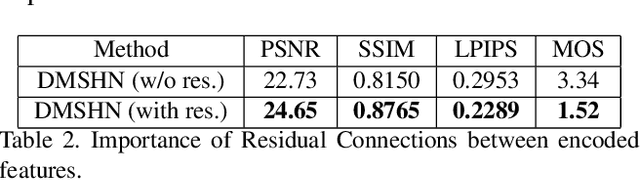

The Bokeh Effect is one of the most desirable effects in photography for rendering artistic and aesthetic photos. Usually, it requires a DSLR camera with different aperture and shutter settings and certain photography skills to generate this effect. In smartphones, computational methods and additional sensors are used to overcome the physical lens and sensor limitations to achieve such effect. Most of the existing methods utilized additional sensor's data or pretrained network for fine depth estimation of the scene and sometimes use portrait segmentation pretrained network module to segment salient objects in the image. Because of these reasons, networks have many parameters, become runtime intensive and unable to run in mid-range devices. In this paper, we used an end-to-end Deep Multi-Scale Hierarchical Network (DMSHN) model for direct Bokeh effect rendering of images captured from the monocular camera. To further improve the perceptual quality of such effect, a stacked model consisting of two DMSHN modules is also proposed. Our model does not rely on any pretrained network module for Monocular Depth Estimation or Saliency Detection, thus significantly reducing the size of model and run time. Stacked DMSHN achieves state-of-the-art results on a large scale EBB! dataset with around 6x less runtime compared to the current state-of-the-art model in processing HD quality images.
A Heuristic-driven Uncertainty based Ensemble Framework for Fake News Detection in Tweets and News Articles
Apr 05, 2021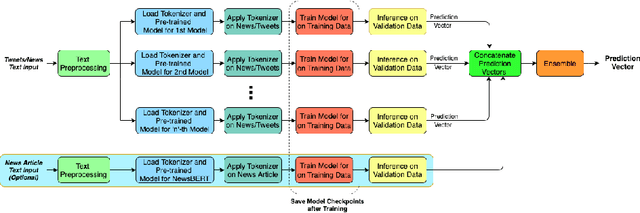

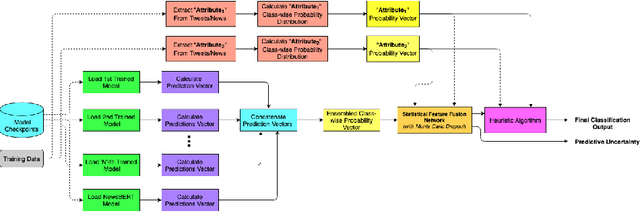
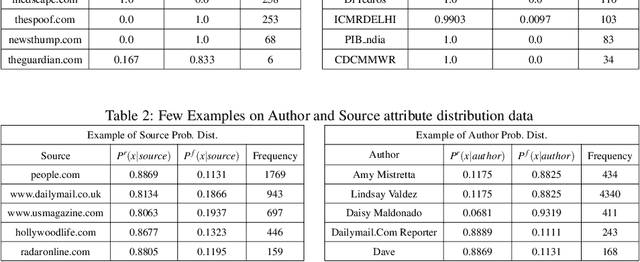
The significance of social media has increased manifold in the past few decades as it helps people from even the most remote corners of the world to stay connected. With the advent of technology, digital media has become more relevant and widely used than ever before and along with this, there has been a resurgence in the circulation of fake news and tweets that demand immediate attention. In this paper, we describe a novel Fake News Detection system that automatically identifies whether a news item is "real" or "fake", as an extension of our work in the CONSTRAINT COVID-19 Fake News Detection in English challenge. We have used an ensemble model consisting of pre-trained models followed by a statistical feature fusion network , along with a novel heuristic algorithm by incorporating various attributes present in news items or tweets like source, username handles, URL domains and authors as statistical feature. Our proposed framework have also quantified reliable predictive uncertainty along with proper class output confidence level for the classification task. We have evaluated our results on the COVID-19 Fake News dataset and FakeNewsNet dataset to show the effectiveness of the proposed algorithm on detecting fake news in short news content as well as in news articles. We obtained a best F1-score of 0.9892 on the COVID-19 dataset, and an F1-score of 0.9073 on the FakeNewsNet dataset.