 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMRABooth: Subject and Motion Representation Alignment for Customized Video Generation
Dec 13, 2025Customized video generation aims to produce videos that faithfully preserve the subject's appearance from reference images while maintaining temporally consistent motion from reference videos. Existing methods struggle to ensure both subject appearance similarity and motion pattern consistency due to the lack of object-level guidance for subject and motion. To address this, we propose SMRABooth, which leverages the self-supervised encoder and optical flow encoder to provide object-level subject and motion representations. These representations are aligned with the model during the LoRA fine-tuning process. Our approach is structured in three core stages: (1) We exploit subject representations via a self-supervised encoder to guide subject alignment, enabling the model to capture overall structure of subject and enhance high-level semantic consistency. (2) We utilize motion representations from an optical flow encoder to capture structurally coherent and object-level motion trajectories independent of appearance. (3) We propose a subject-motion association decoupling strategy that applies sparse LoRAs injection across both locations and timing, effectively reducing interference between subject and motion LoRAs. Extensive experiments show that SMRABooth excels in subject and motion customization, maintaining consistent subject appearance and motion patterns, proving its effectiveness in controllable text-to-video generation.
Epipolar Focus Spectrum: A Novel Light Field Representation and Application in Dense-view Reconstruction
Apr 01, 2022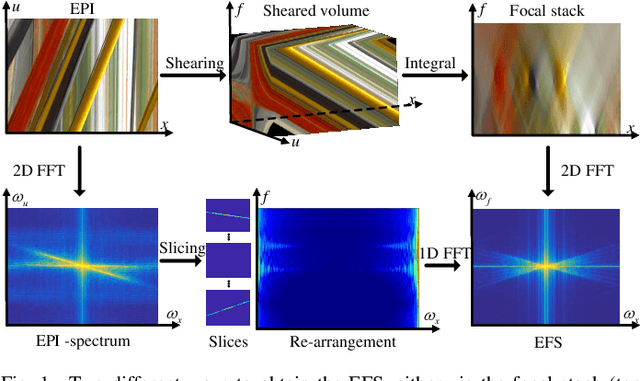

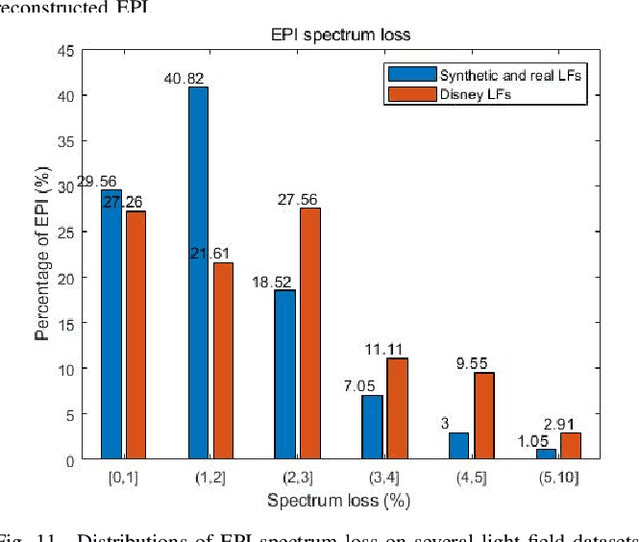
Existing light field representations, such as epipolar plane image (EPI) and sub-aperture images, do not consider the structural characteristics across the views, so they usually require additional disparity and spatial structure cues for follow-up tasks. Besides, they have difficulties dealing with occlusions or larger disparity scenes. To this end, this paper proposes a novel Epipolar Focus Spectrum (EFS) representation by rearranging the EPI spectrum. Different from the classical EPI representation where an EPI line corresponds to a specific depth, there is a one-to-one mapping from the EFS line to the view. Accordingly, compared to a sparsely-sampled light field, a densely-sampled one with the same field of view (FoV) leads to a more compact distribution of such linear structures in the double-cone-shaped region with the identical opening angle in its corresponding EFS. Hence the EFS representation is invariant to the scene depth. To demonstrate its effectiveness, we develop a trainable EFS-based pipeline for light field reconstruction, where a dense light field can be reconstructed by compensating the "missing EFS lines" given a sparse light field, yielding promising results with cross-view consistency, especially in the presence of severe occlusion and large disparity. Experimental results on both synthetic and real-world datasets demonstrate the validity and superiority of the proposed method over SOTA methods.
Deep Anti-aliasing of Whole Focal Stack Using its Slice Spectrum
Jan 23, 2021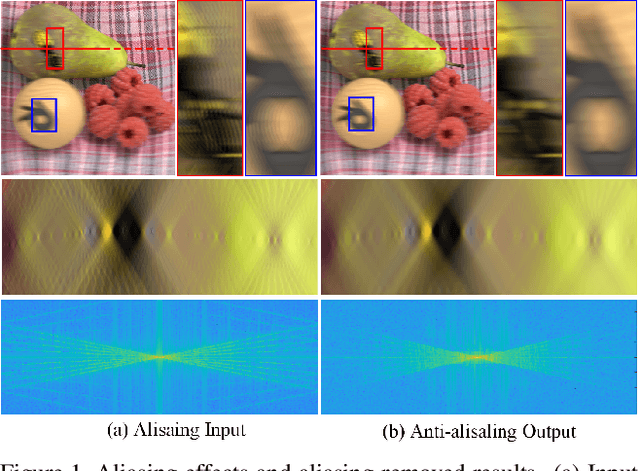
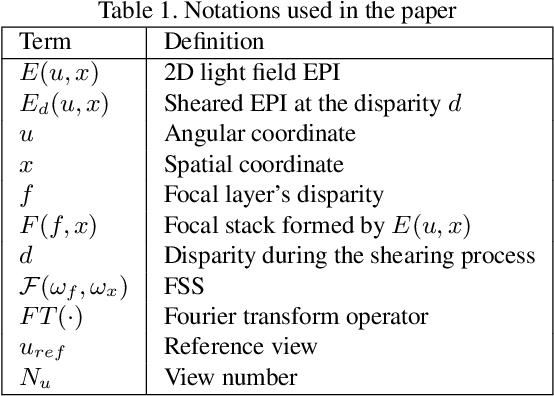
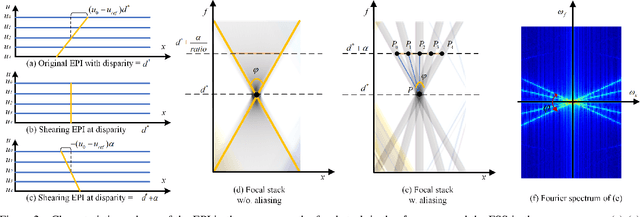
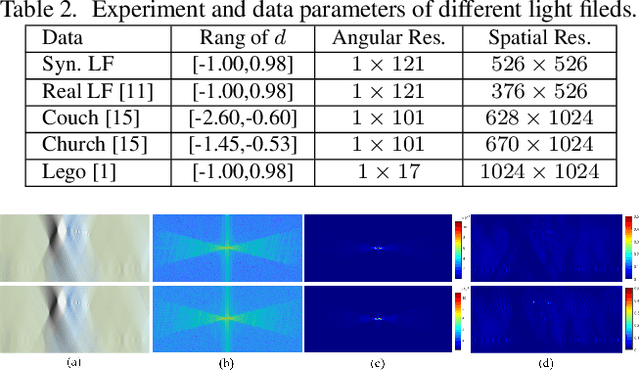
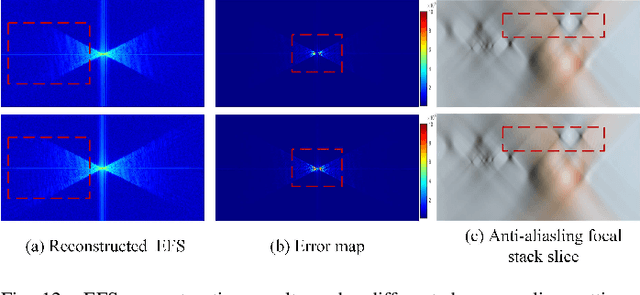
The paper aims at removing the aliasing effects for the whole focal stack generated from a sparse 3D light field, while keeping the consistency across all the focal layers.We first explore the structural characteristics embedded in the focal stack slice and its corresponding frequency-domain representation, i.e., the focal stack spectrum (FSS). We also observe that the energy distribution of FSS always locates within the same triangular area under different angular sampling rates, additionally the continuity of point spread function (PSF) is intrinsically maintained in the FSS. Based on these two findings, we propose a learning-based FSS reconstruction approach for one-time aliasing removing over the whole focal stack. What's more, a novel conjugate-symmetric loss function is proposed for the optimization. Compared to previous works, our method avoids an explicit depth estimation, and can handle challenging large-disparity scenarios. Experimental results on both synthetic and real light field datasets show the superiority of the proposed approach for different scenes and various angular sampling rates.
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020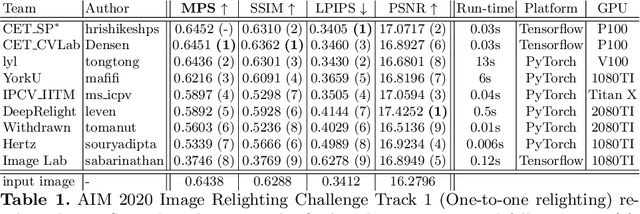

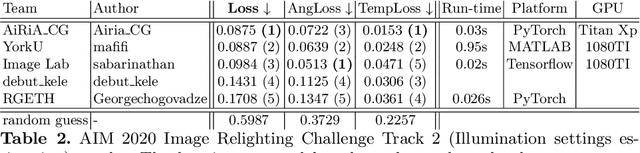

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.