 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhantom-Data : Towards a General Subject-Consistent Video Generation Dataset
Jun 23, 2025Subject-to-video generation has witnessed substantial progress in recent years. However, existing models still face significant challenges in faithfully following textual instructions. This limitation, commonly known as the copy-paste problem, arises from the widely used in-pair training paradigm. This approach inherently entangles subject identity with background and contextual attributes by sampling reference images from the same scene as the target video. To address this issue, we introduce \textbf{Phantom-Data, the first general-purpose cross-pair subject-to-video consistency dataset}, containing approximately one million identity-consistent pairs across diverse categories. Our dataset is constructed via a three-stage pipeline: (1) a general and input-aligned subject detection module, (2) large-scale cross-context subject retrieval from more than 53 million videos and 3 billion images, and (3) prior-guided identity verification to ensure visual consistency under contextual variation. Comprehensive experiments show that training with Phantom-Data significantly improves prompt alignment and visual quality while preserving identity consistency on par with in-pair baselines.
EgoM2P: Egocentric Multimodal Multitask Pretraining
Jun 09, 2025

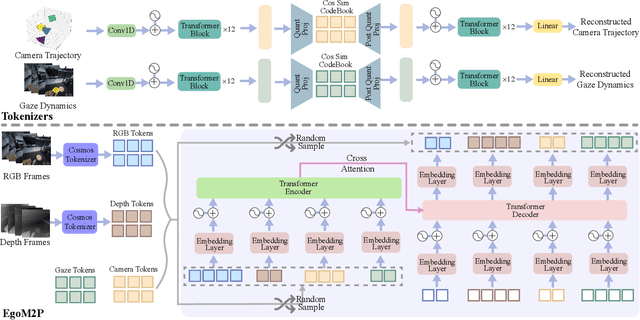
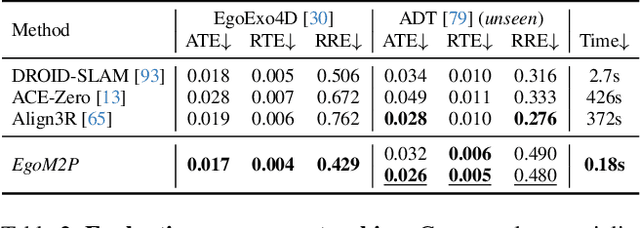
Understanding multimodal signals in egocentric vision, such as RGB video, depth, camera poses, and gaze, is essential for applications in augmented reality, robotics, and human-computer interaction. These capabilities enable systems to better interpret the camera wearer's actions, intentions, and surrounding environment. However, building large-scale egocentric multimodal and multitask models presents unique challenges. Egocentric data are inherently heterogeneous, with large variations in modality coverage across devices and settings. Generating pseudo-labels for missing modalities, such as gaze or head-mounted camera trajectories, is often infeasible, making standard supervised learning approaches difficult to scale. Furthermore, dynamic camera motion and the complex temporal and spatial structure of first-person video pose additional challenges for the direct application of existing multimodal foundation models. To address these challenges, we introduce a set of efficient temporal tokenizers and propose EgoM2P, a masked modeling framework that learns from temporally aware multimodal tokens to train a large, general-purpose model for egocentric 4D understanding. This unified design supports multitasking across diverse egocentric perception and synthesis tasks, including gaze prediction, egocentric camera tracking, and monocular depth estimation from egocentric video. EgoM2P also serves as a generative model for conditional egocentric video synthesis. Across these tasks, EgoM2P matches or outperforms specialist models while being an order of magnitude faster. We will fully open-source EgoM2P to support the community and advance egocentric vision research. Project page: https://egom2p.github.io/
Transformers Meet In-Context Learning: A Universal Approximation Theory
Jun 05, 2025Modern large language models are capable of in-context learning, the ability to perform new tasks at inference time using only a handful of input-output examples in the prompt, without any fine-tuning or parameter updates. We develop a universal approximation theory to better understand how transformers enable in-context learning. For any class of functions (each representing a distinct task), we demonstrate how to construct a transformer that, without any further weight updates, can perform reliable prediction given only a few in-context examples. In contrast to much of the recent literature that frames transformers as algorithm approximators -- i.e., constructing transformers to emulate the iterations of optimization algorithms as a means to approximate solutions of learning problems -- our work adopts a fundamentally different approach rooted in universal function approximation. This alternative approach offers approximation guarantees that are not constrained by the effectiveness of the optimization algorithms being approximated, thereby extending far beyond convex problems and linear function classes. Our construction sheds light on how transformers can simultaneously learn general-purpose representations and adapt dynamically to in-context examples.
A Convergence Theory for Diffusion Language Models: An Information-Theoretic Perspective
May 27, 2025Diffusion models have emerged as a powerful paradigm for modern generative modeling, demonstrating strong potential for large language models (LLMs). Unlike conventional autoregressive (AR) models that generate tokens sequentially, diffusion models enable parallel token sampling, leading to faster generation and eliminating left-to-right generation constraints. Despite their empirical success, the theoretical understanding of diffusion model approaches remains underdeveloped. In this work, we develop convergence guarantees for diffusion language models from an information-theoretic perspective. Our analysis demonstrates that the sampling error, measured by the Kullback-Leibler (KL) divergence, decays inversely with the number of iterations $T$ and scales linearly with the mutual information between tokens in the target text sequence. In particular, we establish matching upper and lower bounds, up to some constant factor, to demonstrate the tightness of our convergence analysis. These results offer novel theoretical insights into the practical effectiveness of diffusion language models.
TinyAlign: Boosting Lightweight Vision-Language Models by Mitigating Modal Alignment Bottlenecks
May 19, 2025Lightweight Vision-Language Models (VLMs) are indispensable for resource-constrained applications. The prevailing approach to aligning vision and language models involves freezing both the vision encoder and the language model while training small connector modules. However, this strategy heavily depends on the intrinsic capabilities of the language model, which can be suboptimal for lightweight models with limited representational capacity. In this work, we investigate this alignment bottleneck through the lens of mutual information, demonstrating that the constrained capacity of the language model inherently limits the Effective Mutual Information (EMI) between multimodal inputs and outputs, thereby compromising alignment quality. To address this challenge, we propose TinyAlign, a novel framework inspired by Retrieval-Augmented Generation, which strategically retrieves relevant context from a memory bank to enrich multimodal inputs and enhance their alignment. Extensive empirical evaluations reveal that TinyAlign significantly reduces training loss, accelerates convergence, and enhances task performance. Remarkably, it allows models to achieve baseline-level performance with only 40\% of the fine-tuning data, highlighting exceptional data efficiency. Our work thus offers a practical pathway for developing more capable lightweight VLMs while introducing a fresh theoretical lens to better understand and address alignment bottlenecks in constrained multimodal systems.
Ranking-Based At-Risk Student Prediction Using Federated Learning and Differential Features
May 14, 2025Digital textbooks are widely used in various educational contexts, such as university courses and online lectures. Such textbooks yield learning log data that have been used in numerous educational data mining (EDM) studies for student behavior analysis and performance prediction. However, these studies have faced challenges in integrating confidential data, such as academic records and learning logs, across schools due to privacy concerns. Consequently, analyses are often conducted with data limited to a single school, which makes developing high-performing and generalizable models difficult. This study proposes a method that combines federated learning and differential features to address these issues. Federated learning enables model training without centralizing data, thereby preserving student privacy. Differential features, which utilize relative values instead of absolute values, enhance model performance and generalizability. To evaluate the proposed method, a model for predicting at-risk students was trained using data from 1,136 students across 12 courses conducted over 4 years, and validated on hold-out test data from 5 other courses. Experimental results demonstrated that the proposed method addresses privacy concerns while achieving performance comparable to that of models trained via centralized learning in terms of Top-n precision, nDCG, and PR-AUC. Furthermore, using differential features improved prediction performance across all evaluation datasets compared to non-differential approaches. The trained models were also applicable for early prediction, achieving high performance in detecting at-risk students in earlier stages of the semester within the validation datasets.
Provable Efficiency of Guidance in Diffusion Models for General Data Distribution
May 02, 2025

Diffusion models have emerged as a powerful framework for generative modeling, with guidance techniques playing a crucial role in enhancing sample quality. Despite their empirical success, a comprehensive theoretical understanding of the guidance effect remains limited. Existing studies only focus on case studies, where the distribution conditioned on each class is either isotropic Gaussian or supported on a one-dimensional interval with some extra conditions. How to analyze the guidance effect beyond these case studies remains an open question. Towards closing this gap, we make an attempt to analyze diffusion guidance under general data distributions. Rather than demonstrating uniform sample quality improvement, which does not hold in some distributions, we prove that guidance can improve the whole sample quality, in the sense that the average reciprocal of the classifier probability decreases with the existence of guidance. This aligns with the motivation of introducing guidance.
Sculpting Memory: Multi-Concept Forgetting in Diffusion Models via Dynamic Mask and Concept-Aware Optimization
Apr 12, 2025Text-to-image (T2I) diffusion models have achieved remarkable success in generating high-quality images from textual prompts. However, their ability to store vast amounts of knowledge raises concerns in scenarios where selective forgetting is necessary, such as removing copyrighted content, reducing biases, or eliminating harmful concepts. While existing unlearning methods can remove certain concepts, they struggle with multi-concept forgetting due to instability, residual knowledge persistence, and generation quality degradation. To address these challenges, we propose \textbf{Dynamic Mask coupled with Concept-Aware Loss}, a novel unlearning framework designed for multi-concept forgetting in diffusion models. Our \textbf{Dynamic Mask} mechanism adaptively updates gradient masks based on current optimization states, allowing selective weight modifications that prevent interference with unrelated knowledge. Additionally, our \textbf{Concept-Aware Loss} explicitly guides the unlearning process by enforcing semantic consistency through superclass alignment, while a regularization loss based on knowledge distillation ensures that previously unlearned concepts remain forgotten during sequential unlearning. We conduct extensive experiments to evaluate our approach. Results demonstrate that our method outperforms existing unlearning techniques in forgetting effectiveness, output fidelity, and semantic coherence, particularly in multi-concept scenarios. Our work provides a principled and flexible framework for stable and high-fidelity unlearning in generative models. The code will be released publicly.
Single-Agent vs. Multi-Agent LLM Strategies for Automated Student Reflection Assessment
Apr 08, 2025We explore the use of Large Language Models (LLMs) for automated assessment of open-text student reflections and prediction of academic performance. Traditional methods for evaluating reflections are time-consuming and may not scale effectively in educational settings. In this work, we employ LLMs to transform student reflections into quantitative scores using two assessment strategies (single-agent and multi-agent) and two prompting techniques (zero-shot and few-shot). Our experiments, conducted on a dataset of 5,278 reflections from 377 students over three academic terms, demonstrate that the single-agent with few-shot strategy achieves the highest match rate with human evaluations. Furthermore, models utilizing LLM-assessed reflection scores outperform baselines in both at-risk student identification and grade prediction tasks. These findings suggest that LLMs can effectively automate reflection assessment, reduce educators' workload, and enable timely support for students who may need additional assistance. Our work emphasizes the potential of integrating advanced generative AI technologies into educational practices to enhance student engagement and academic success.
Dimension-Free Convergence of Diffusion Models for Approximate Gaussian Mixtures
Apr 07, 2025Diffusion models are distinguished by their exceptional generative performance, particularly in producing high-quality samples through iterative denoising. While current theory suggests that the number of denoising steps required for accurate sample generation should scale linearly with data dimension, this does not reflect the practical efficiency of widely used algorithms like Denoising Diffusion Probabilistic Models (DDPMs). This paper investigates the effectiveness of diffusion models in sampling from complex high-dimensional distributions that can be well-approximated by Gaussian Mixture Models (GMMs). For these distributions, our main result shows that DDPM takes at most $\widetilde{O}(1/\varepsilon)$ iterations to attain an $\varepsilon$-accurate distribution in total variation (TV) distance, independent of both the ambient dimension $d$ and the number of components $K$, up to logarithmic factors. Furthermore, this result remains robust to score estimation errors. These findings highlight the remarkable effectiveness of diffusion models in high-dimensional settings given the universal approximation capability of GMMs, and provide theoretical insights into their practical success.