 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumANDiff: Articulated Noise Diffusion for Motion-Consistent Human Video Generation
Apr 07, 2026Despite tremendous recent progress in human video generation, generative video diffusion models still struggle to capture the dynamics and physics of human motions faithfully. In this paper, we propose a new framework for human video generation, HumANDiff, which enhances the human motion control with three key designs: 1) Articulated motion-consistent noise sampling that correlates the spatiotemporal distribution of latent noise and replaces the unstructured random Gaussian noise with 3D articulated noise sampled on the dense surface manifold of a statistical human body template. It inherits body topology priors for spatially and temporally consistent noise sampling. 2) Joint appearance-motion learning that enhances the standard training objective of video diffusion models by jointly predicting pixel appearances and corresponding physical motions from the articulated noises. It enables high-fidelity human video synthesis, e.g., capturing motion-dependent clothing wrinkles. 3) Geometric motion consistency learning that enforces physical motion consistency across frames via a novel geometric motion consistency loss defined in the articulated noise space. HumANDiff enables scalable controllable human video generation by fine-tuning video diffusion models with articulated noise sampling. Consequently, our method is agnostic to diffusion model design, and requires no modifications to the model architecture. During inference, HumANDiff enables image-to-video generation within a single framework, achieving intrinsic motion control without requiring additional motion modules. Extensive experiments demonstrate that our method achieves state-of-the-art performance in rendering motion-consistent, high-fidelity humans with diverse clothing styles. Project page: https://taohuumd.github.io/projects/HumANDiff/
ReLi3D: Relightable Multi-view 3D Reconstruction with Disentangled Illumination
Mar 20, 2026Reconstructing 3D assets from images has long required separate pipelines for geometry reconstruction, material estimation, and illumination recovery, each with distinct limitations and computational overhead. We present ReLi3D, the first unified end-to-end pipeline that simultaneously reconstructs complete 3D geometry, spatially-varying physically-based materials, and environment illumination from sparse multi-view images in under one second. Our key insight is that multi-view constraints can dramatically improve material and illumination disentanglement, a problem that remains fundamentally ill-posed for single-image methods. Key to our approach is the fusion of the multi-view input via a transformer cross-conditioning architecture, followed by a novel unified two-path prediction strategy. The first path predicts the object's structure and appearance, while the second path predicts the environment illumination from image background or object reflections. This, combined with a differentiable Monte Carlo multiple importance sampling renderer, creates an optimal illumination disentanglement training pipeline. In addition, with our mixed domain training protocol, which combines synthetic PBR datasets with real-world RGB captures, we establish generalizable results in geometry, material accuracy, and illumination quality. By unifying previously separate reconstruction tasks into a single feed-forward pass, we enable near-instantaneous generation of complete, relightable 3D assets. Project Page: https://reli3d.jdihlmann.com/
* Project Page: https://reli3d.jdihlmann.com/
Human Video Generation from a Single Image with 3D Pose and View Control
Feb 24, 2026Recent diffusion methods have made significant progress in generating videos from single images due to their powerful visual generation capabilities. However, challenges persist in image-to-video synthesis, particularly in human video generation, where inferring view-consistent, motion-dependent clothing wrinkles from a single image remains a formidable problem. In this paper, we present Human Video Generation in 4D (HVG), a latent video diffusion model capable of generating high-quality, multi-view, spatiotemporally coherent human videos from a single image with 3D pose and view control. HVG achieves this through three key designs: (i) Articulated Pose Modulation, which captures the anatomical relationships of 3D joints via a novel dual-dimensional bone map and resolves self-occlusions across views by introducing 3D information; (ii) View and Temporal Alignment, which ensures multi-view consistency and alignment between a reference image and pose sequences for frame-to-frame stability; and (iii) Progressive Spatio-Temporal Sampling with temporal alignment to maintain smooth transitions in long multi-view animations. Extensive experiments on image-to-video tasks demonstrate that HVG outperforms existing methods in generating high-quality 4D human videos from diverse human images and pose inputs.
FROMAT: Multiview Material Appearance Transfer via Few-Shot Self-Attention Adaptation
Dec 10, 2025Multiview diffusion models have rapidly emerged as a powerful tool for content creation with spatial consistency across viewpoints, offering rich visual realism without requiring explicit geometry and appearance representation. However, compared to meshes or radiance fields, existing multiview diffusion models offer limited appearance manipulation, particularly in terms of material, texture, or style. In this paper, we present a lightweight adaptation technique for appearance transfer in multiview diffusion models. Our method learns to combine object identity from an input image with appearance cues rendered in a separate reference image, producing multi-view-consistent output that reflects the desired materials, textures, or styles. This allows explicit specification of appearance parameters at generation time while preserving the underlying object geometry and view coherence. We leverage three diffusion denoising processes responsible for generating the original object, the reference, and the target images, and perform reverse sampling to aggregate a small subset of layer-wise self-attention features from the object and the reference to influence the target generation. Our method requires only a few training examples to introduce appearance awareness to pretrained multiview models. The experiments show that our method provides a simple yet effective way toward multiview generation with diverse appearance, advocating the adoption of implicit generative 3D representations in practice.
Foley Control: Aligning a Frozen Latent Text-to-Audio Model to Video
Oct 24, 2025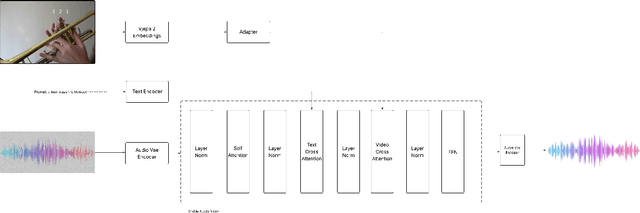
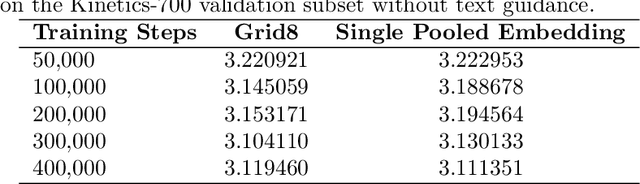
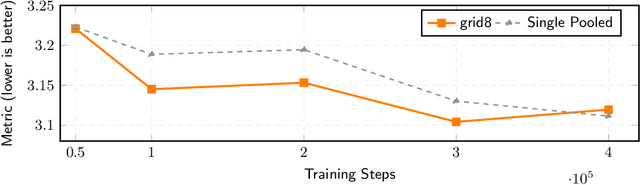

Foley Control is a lightweight approach to video-guided Foley that keeps pretrained single-modality models frozen and learns only a small cross-attention bridge between them. We connect V-JEPA2 video embeddings to a frozen Stable Audio Open DiT text-to-audio (T2A) model by inserting compact video cross-attention after the model's existing text cross-attention, so prompts set global semantics while video refines timing and local dynamics. The frozen backbones retain strong marginals (video; audio given text) and the bridge learns the audio-video dependency needed for synchronization -- without retraining the audio prior. To cut memory and stabilize training, we pool video tokens before conditioning. On curated video-audio benchmarks, Foley Control delivers competitive temporal and semantic alignment with far fewer trainable parameters than recent multi-modal systems, while preserving prompt-driven controllability and production-friendly modularity (swap/upgrade encoders or the T2A backbone without end-to-end retraining). Although we focus on Video-to-Foley, the same bridge design can potentially extend to other audio modalities (e.g., speech).
Stable Cinemetrics : Structured Taxonomy and Evaluation for Professional Video Generation
Sep 30, 2025Recent advances in video generation have enabled high-fidelity video synthesis from user provided prompts. However, existing models and benchmarks fail to capture the complexity and requirements of professional video generation. Towards that goal, we introduce Stable Cinemetrics, a structured evaluation framework that formalizes filmmaking controls into four disentangled, hierarchical taxonomies: Setup, Event, Lighting, and Camera. Together, these taxonomies define 76 fine-grained control nodes grounded in industry practices. Using these taxonomies, we construct a benchmark of prompts aligned with professional use cases and develop an automated pipeline for prompt categorization and question generation, enabling independent evaluation of each control dimension. We conduct a large-scale human study spanning 10+ models and 20K videos, annotated by a pool of 80+ film professionals. Our analysis, both coarse and fine-grained reveal that even the strongest current models exhibit significant gaps, particularly in Events and Camera-related controls. To enable scalable evaluation, we train an automatic evaluator, a vision-language model aligned with expert annotations that outperforms existing zero-shot baselines. SCINE is the first approach to situate professional video generation within the landscape of video generative models, introducing taxonomies centered around cinematic controls and supporting them with structured evaluation pipelines and detailed analyses to guide future research.
DiffusionLight-Turbo: Accelerated Light Probes for Free via Single-Pass Chrome Ball Inpainting
Jul 02, 2025We introduce a simple yet effective technique for estimating lighting from a single low-dynamic-range (LDR) image by reframing the task as a chrome ball inpainting problem. This approach leverages a pre-trained diffusion model, Stable Diffusion XL, to overcome the generalization failures of existing methods that rely on limited HDR panorama datasets. While conceptually simple, the task remains challenging because diffusion models often insert incorrect or inconsistent content and cannot readily generate chrome balls in HDR format. Our analysis reveals that the inpainting process is highly sensitive to the initial noise in the diffusion process, occasionally resulting in unrealistic outputs. To address this, we first introduce DiffusionLight, which uses iterative inpainting to compute a median chrome ball from multiple outputs to serve as a stable, low-frequency lighting prior that guides the generation of a high-quality final result. To generate high-dynamic-range (HDR) light probes, an Exposure LoRA is fine-tuned to create LDR images at multiple exposure values, which are then merged. While effective, DiffusionLight is time-intensive, requiring approximately 30 minutes per estimation. To reduce this overhead, we introduce DiffusionLight-Turbo, which reduces the runtime to about 30 seconds with minimal quality loss. This 60x speedup is achieved by training a Turbo LoRA to directly predict the averaged chrome balls from the iterative process. Inference is further streamlined into a single denoising pass using a LoRA swapping technique. Experimental results that show our method produces convincing light estimates across diverse settings and demonstrates superior generalization to in-the-wild scenarios. Our code is available at https://diffusionlight.github.io/turbo
PhysRig: Differentiable Physics-Based Skinning and Rigging Framework for Realistic Articulated Object Modeling
Jun 26, 2025Skinning and rigging are fundamental components in animation, articulated object reconstruction, motion transfer, and 4D generation. Existing approaches predominantly rely on Linear Blend Skinning (LBS), due to its simplicity and differentiability. However, LBS introduces artifacts such as volume loss and unnatural deformations, and it fails to model elastic materials like soft tissues, fur, and flexible appendages (e.g., elephant trunks, ears, and fatty tissues). In this work, we propose PhysRig: a differentiable physics-based skinning and rigging framework that overcomes these limitations by embedding the rigid skeleton into a volumetric representation (e.g., a tetrahedral mesh), which is simulated as a deformable soft-body structure driven by the animated skeleton. Our method leverages continuum mechanics and discretizes the object as particles embedded in an Eulerian background grid to ensure differentiability with respect to both material properties and skeletal motion. Additionally, we introduce material prototypes, significantly reducing the learning space while maintaining high expressiveness. To evaluate our framework, we construct a comprehensive synthetic dataset using meshes from Objaverse, The Amazing Animals Zoo, and MixaMo, covering diverse object categories and motion patterns. Our method consistently outperforms traditional LBS-based approaches, generating more realistic and physically plausible results. Furthermore, we demonstrate the applicability of our framework in the pose transfer task highlighting its versatility for articulated object modeling.
GIQ: Benchmarking 3D Geometric Reasoning of Vision Foundation Models with Simulated and Real Polyhedra
Jun 11, 2025
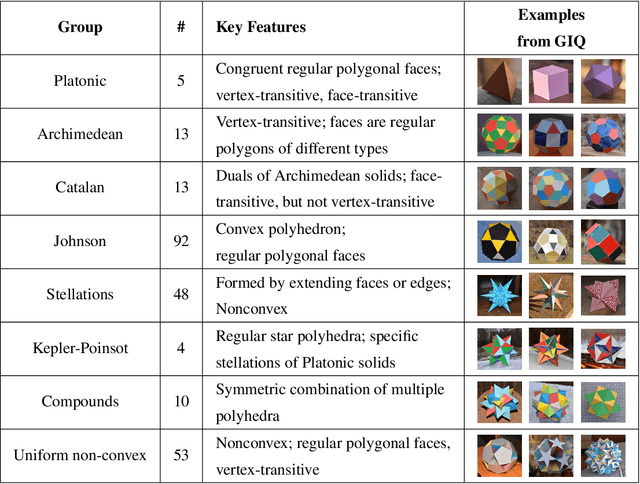
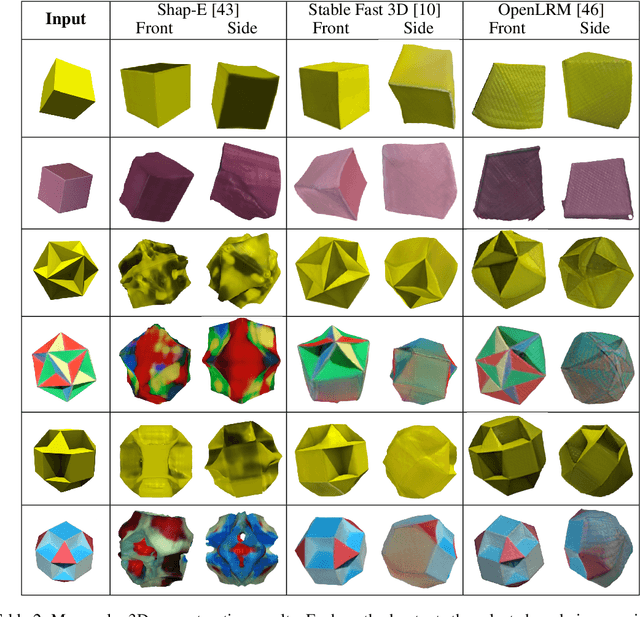
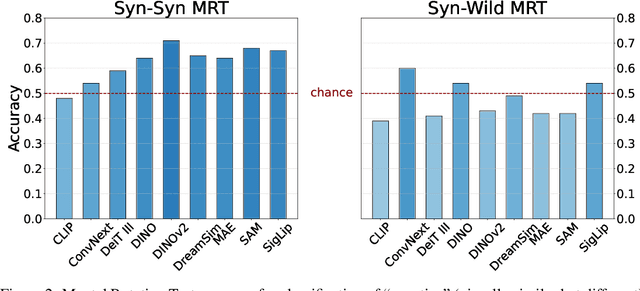
Monocular 3D reconstruction methods and vision-language models (VLMs) demonstrate impressive results on standard benchmarks, yet their true understanding of geometric properties remains unclear. We introduce GIQ , a comprehensive benchmark specifically designed to evaluate the geometric reasoning capabilities of vision and vision-language foundation models. GIQ comprises synthetic and real-world images of 224 diverse polyhedra - including Platonic, Archimedean, Johnson, and Catalan solids, as well as stellations and compound shapes - covering varying levels of complexity and symmetry. Through systematic experiments involving monocular 3D reconstruction, 3D symmetry detection, mental rotation tests, and zero-shot shape classification tasks, we reveal significant shortcomings in current models. State-of-the-art reconstruction algorithms trained on extensive 3D datasets struggle to reconstruct even basic geometric forms accurately. While foundation models effectively detect specific 3D symmetry elements via linear probing, they falter significantly in tasks requiring detailed geometric differentiation, such as mental rotation. Moreover, advanced vision-language assistants exhibit remarkably low accuracy on complex polyhedra, systematically misinterpreting basic properties like face geometry, convexity, and compound structures. GIQ is publicly available, providing a structured platform to highlight and address critical gaps in geometric intelligence, facilitating future progress in robust, geometry-aware representation learning.
MARBLE: Material Recomposition and Blending in CLIP-Space
Jun 05, 2025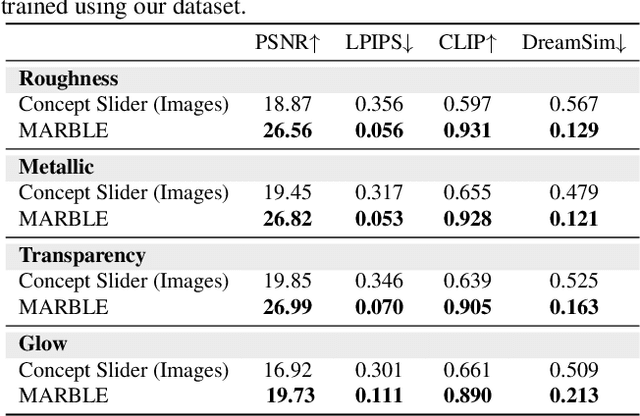

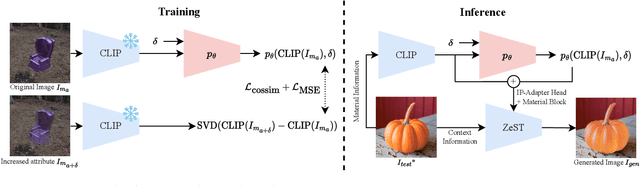

Editing materials of objects in images based on exemplar images is an active area of research in computer vision and graphics. We propose MARBLE, a method for performing material blending and recomposing fine-grained material properties by finding material embeddings in CLIP-space and using that to control pre-trained text-to-image models. We improve exemplar-based material editing by finding a block in the denoising UNet responsible for material attribution. Given two material exemplar-images, we find directions in the CLIP-space for blending the materials. Further, we can achieve parametric control over fine-grained material attributes such as roughness, metallic, transparency, and glow using a shallow network to predict the direction for the desired material attribute change. We perform qualitative and quantitative analysis to demonstrate the efficacy of our proposed method. We also present the ability of our method to perform multiple edits in a single forward pass and applicability to painting. Project Page: https://marblecontrol.github.io/