 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePicking on the Same Person: Does Algorithmic Monoculture lead to Outcome Homogenization?
Nov 25, 2022As the scope of machine learning broadens, we observe a recurring theme of algorithmic monoculture: the same systems, or systems that share components (e.g. training data), are deployed by multiple decision-makers. While sharing offers clear advantages (e.g. amortizing costs), does it bear risks? We introduce and formalize one such risk, outcome homogenization: the extent to which particular individuals or groups experience negative outcomes from all decision-makers. If the same individuals or groups exclusively experience undesirable outcomes, this may institutionalize systemic exclusion and reinscribe social hierarchy. To relate algorithmic monoculture and outcome homogenization, we propose the component-sharing hypothesis: if decision-makers share components like training data or specific models, then they will produce more homogeneous outcomes. We test this hypothesis on algorithmic fairness benchmarks, demonstrating that sharing training data reliably exacerbates homogenization, with individual-level effects generally exceeding group-level effects. Further, given the dominant paradigm in AI of foundation models, i.e. models that can be adapted for myriad downstream tasks, we test whether model sharing homogenizes outcomes across tasks. We observe mixed results: we find that for both vision and language settings, the specific methods for adapting a foundation model significantly influence the degree of outcome homogenization. We conclude with philosophical analyses of and societal challenges for outcome homogenization, with an eye towards implications for deployed machine learning systems.
How to Fine-Tune Vision Models with SGD
Nov 17, 2022SGD (with momentum) and AdamW are the two most used optimizers for fine-tuning large neural networks in computer vision. When the two methods perform the same, SGD is preferable because it uses less memory (12 bytes/parameter) than AdamW (16 bytes/parameter). However, on a suite of downstream tasks, especially those with distribution shifts, we show that fine-tuning with AdamW performs substantially better than SGD on modern Vision Transformer and ConvNeXt models. We find that large gaps in performance between SGD and AdamW occur when the fine-tuning gradients in the first "embedding" layer are much larger than in the rest of the model. Our analysis suggests an easy fix that works consistently across datasets and models: merely freezing the embedding layer (less than 1\% of the parameters) leads to SGD performing competitively with AdamW while using less memory. Our insights result in state-of-the-art accuracies on five popular distribution shift benchmarks: WILDS-FMoW, WILDS-Camelyon, Living-17, Waterbirds, and DomainNet.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Surgical Fine-Tuning Improves Adaptation to Distribution Shifts
Oct 20, 2022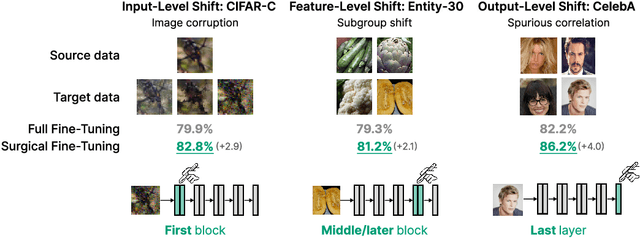
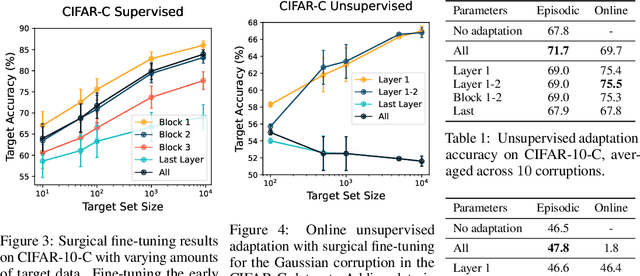
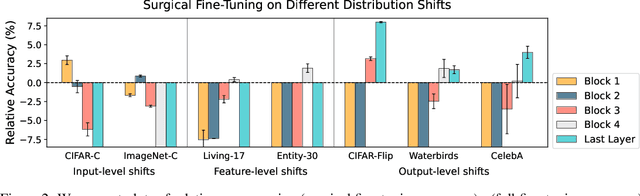
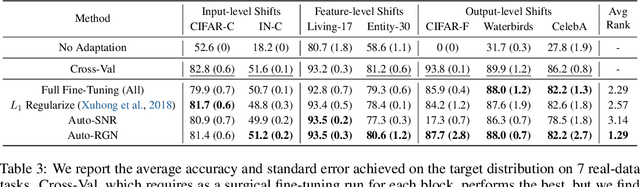
A common approach to transfer learning under distribution shift is to fine-tune the last few layers of a pre-trained model, preserving learned features while also adapting to the new task. This paper shows that in such settings, selectively fine-tuning a subset of layers (which we term surgical fine-tuning) matches or outperforms commonly used fine-tuning approaches. Moreover, the type of distribution shift influences which subset is more effective to tune: for example, for image corruptions, fine-tuning only the first few layers works best. We validate our findings systematically across seven real-world data tasks spanning three types of distribution shifts. Theoretically, we prove that for two-layer neural networks in an idealized setting, first-layer tuning can outperform fine-tuning all layers. Intuitively, fine-tuning more parameters on a small target dataset can cause information learned during pre-training to be forgotten, and the relevant information depends on the type of shift.
Are Sample-Efficient NLP Models More Robust?
Oct 12, 2022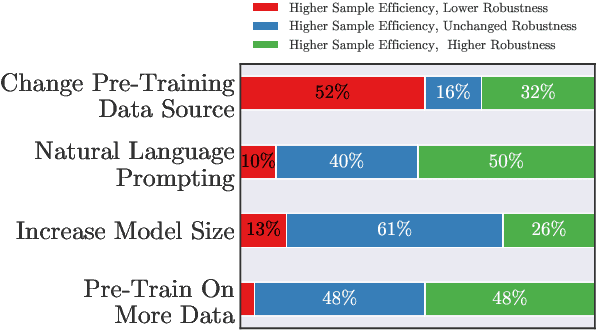
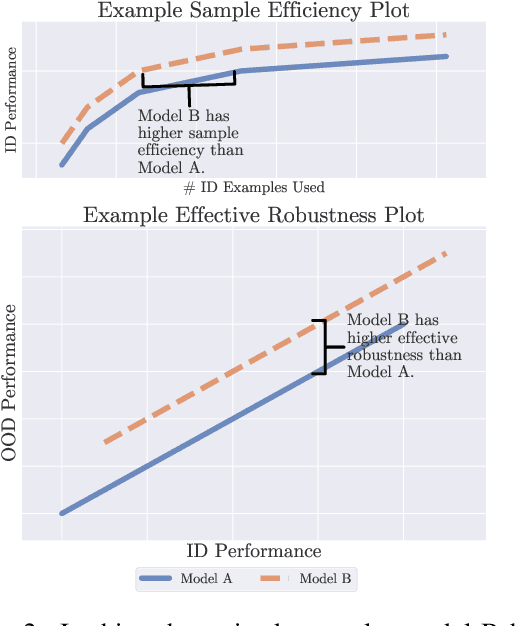
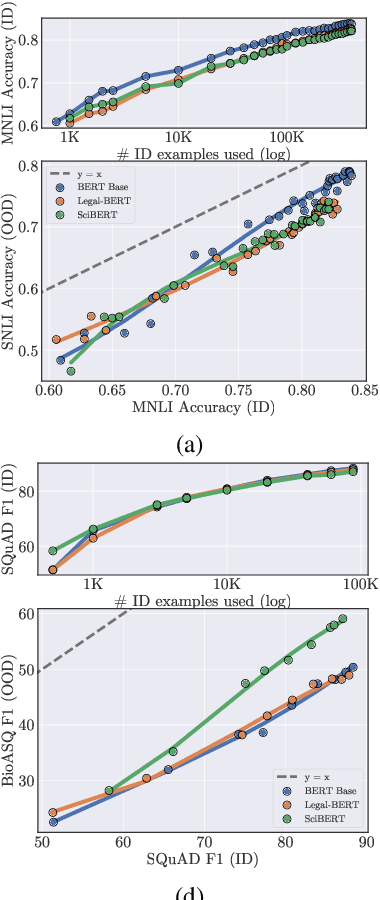
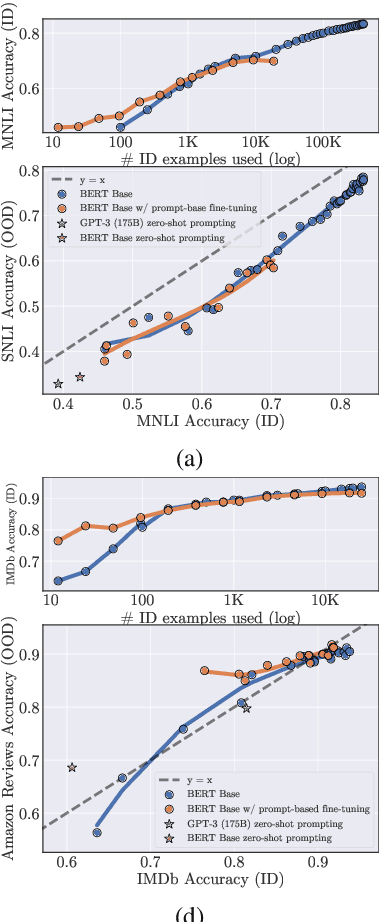
Recent work has observed that pre-trained models have higher out-of-distribution (OOD) robustness when they are exposed to less in-distribution (ID) training data (Radford et al., 2021). In particular, zero-shot models (e.g., GPT-3 and CLIP) have higher robustness than conventionally fine-tuned models, but these robustness gains fade as zero-shot models are fine-tuned on more ID data. We study this relationship between sample efficiency and robustness -- if two models have the same ID performance, does the model trained on fewer examples (higher sample efficiency) perform better OOD (higher robustness)? Surprisingly, experiments across three tasks, 23 total ID-OOD settings, and 14 models do not reveal a consistent relationship between sample efficiency and robustness -- while models with higher sample efficiency are sometimes more robust, most often there is no change in robustness, with some cases even showing decreased robustness. Since results vary on a case-by-case basis, we conduct detailed case studies of two particular ID-OOD pairs (SST-2 -> IMDb sentiment and SNLI -> HANS) to better understand why better sample efficiency may or may not yield higher robustness; attaining such an understanding requires case-by-case analysis of why models are not robust on a particular ID-OOD setting and how modeling techniques affect model capabilities.
Calibrated ensembles can mitigate accuracy tradeoffs under distribution shift
Jul 18, 2022
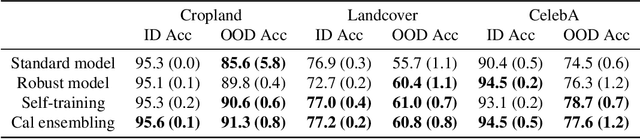
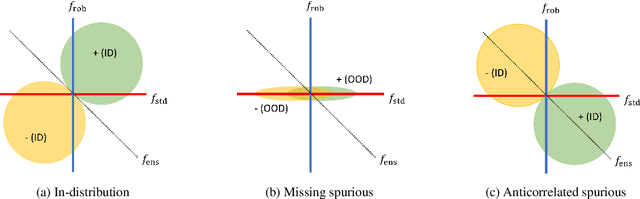
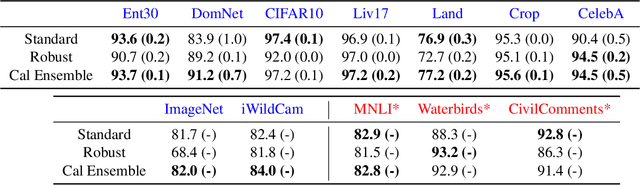
We often see undesirable tradeoffs in robust machine learning where out-of-distribution (OOD) accuracy is at odds with in-distribution (ID) accuracy: a robust classifier obtained via specialized techniques such as removing spurious features often has better OOD but worse ID accuracy compared to a standard classifier trained via ERM. In this paper, we find that ID-calibrated ensembles -- where we simply ensemble the standard and robust models after calibrating on only ID data -- outperforms prior state-of-the-art (based on self-training) on both ID and OOD accuracy. On eleven natural distribution shift datasets, ID-calibrated ensembles obtain the best of both worlds: strong ID accuracy and OOD accuracy. We analyze this method in stylized settings, and identify two important conditions for ensembles to perform well both ID and OOD: (1) we need to calibrate the standard and robust models (on ID data, because OOD data is unavailable), (2) OOD has no anticorrelated spurious features.
Beyond Separability: Analyzing the Linear Transferability of Contrastive Representations to Related Subpopulations
Apr 06, 2022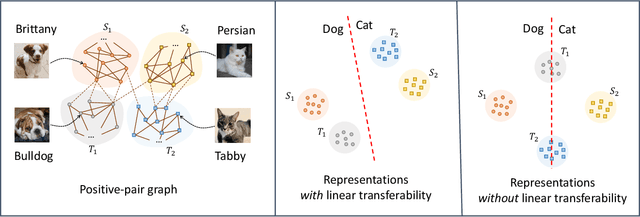

Contrastive learning is a highly effective method which uses unlabeled data to produce representations which are linearly separable for downstream classification tasks. Recent works have shown that contrastive representations are not only useful when data come from a single domain, but are also effective for transferring across domains. Concretely, when contrastive representations are trained on data from two domains (a source and target) and a linear classification head is trained to predict labels using only the labeled source data, the resulting classifier also exhibits good transfer to the target domain. In this work, we analyze this linear transferability phenomenon, building upon the framework proposed by HaoChen et al (2021) which relates contrastive learning to spectral clustering of a positive-pair graph on the data. We prove that contrastive representations capture relationships between subpopulations in the positive-pair graph: linear transferability can occur when data from the same class in different domains (e.g., photo dogs and cartoon dogs) are connected in the graph. Our analysis allows the source and target classes to have unbounded density ratios and be mapped to distant representations. Our proof is also built upon technical improvements over the main results of HaoChen et al (2021), which may be of independent interest.
Connect, Not Collapse: Explaining Contrastive Learning for Unsupervised Domain Adaptation
Apr 01, 2022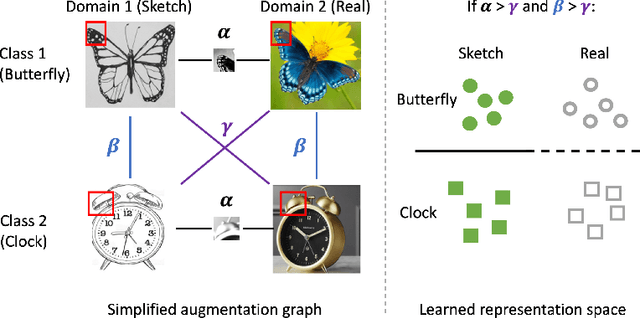
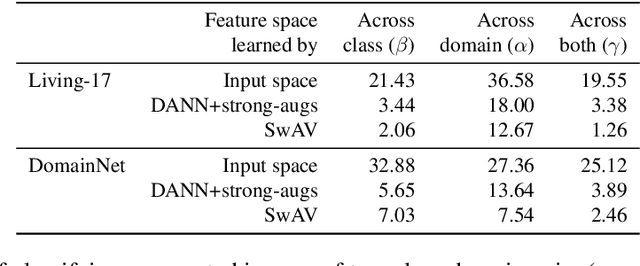
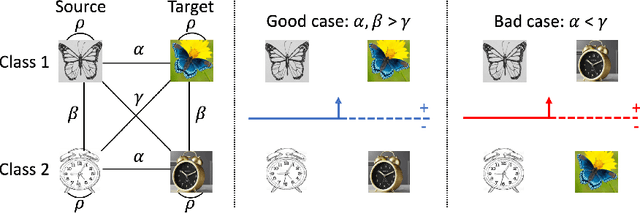

We consider unsupervised domain adaptation (UDA), where labeled data from a source domain (e.g., photographs) and unlabeled data from a target domain (e.g., sketches) are used to learn a classifier for the target domain. Conventional UDA methods (e.g., domain adversarial training) learn domain-invariant features to improve generalization to the target domain. In this paper, we show that contrastive pre-training, which learns features on unlabeled source and target data and then fine-tunes on labeled source data, is competitive with strong UDA methods. However, we find that contrastive pre-training does not learn domain-invariant features, diverging from conventional UDA intuitions. We show theoretically that contrastive pre-training can learn features that vary subtantially across domains but still generalize to the target domain, by disentangling domain and class information. Our results suggest that domain invariance is not necessary for UDA. We empirically validate our theory on benchmark vision datasets.
Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution
Feb 21, 2022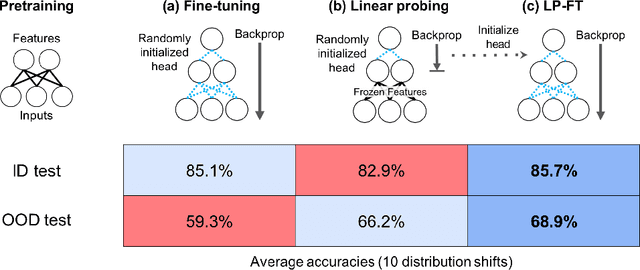

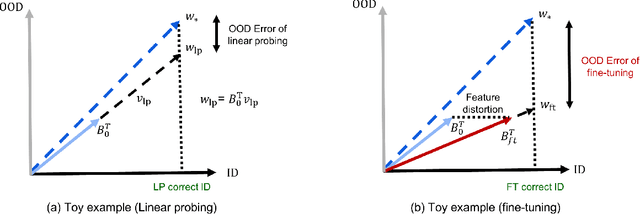
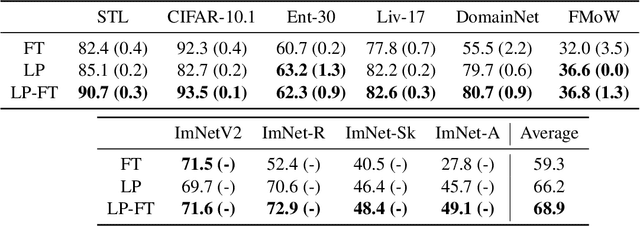
When transferring a pretrained model to a downstream task, two popular methods are full fine-tuning (updating all the model parameters) and linear probing (updating only the last linear layer -- the "head"). It is well known that fine-tuning leads to better accuracy in-distribution (ID). However, in this paper, we find that fine-tuning can achieve worse accuracy than linear probing out-of-distribution (OOD) when the pretrained features are good and the distribution shift is large. On 10 distribution shift datasets (Breeds-Living17, Breeds-Entity30, DomainNet, CIFAR $\to$ STL, CIFAR10.1, FMoW, ImageNetV2, ImageNet-R, ImageNet-A, ImageNet-Sketch), fine-tuning obtains on average 2% higher accuracy ID but 7% lower accuracy OOD than linear probing. We show theoretically that this tradeoff between ID and OOD accuracy arises even in a simple setting: fine-tuning overparameterized two-layer linear networks. We prove that the OOD error of fine-tuning is high when we initialize with a fixed or random head -- this is because while fine-tuning learns the head, the lower layers of the neural network change simultaneously and distort the pretrained features. Our analysis suggests that the easy two-step strategy of linear probing then full fine-tuning (LP-FT), sometimes used as a fine-tuning heuristic, combines the benefits of both fine-tuning and linear probing. Empirically, LP-FT outperforms both fine-tuning and linear probing on the above datasets (1% better ID, 10% better OOD than full fine-tuning).
Extending the WILDS Benchmark for Unsupervised Adaptation
Dec 09, 2021

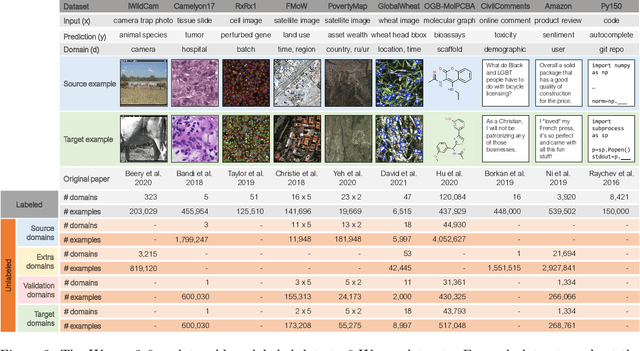
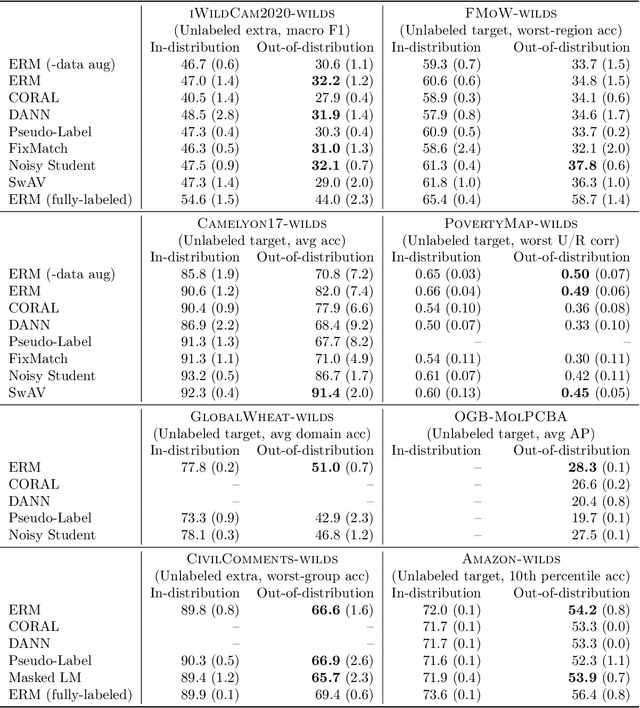
Machine learning systems deployed in the wild are often trained on a source distribution but deployed on a different target distribution. Unlabeled data can be a powerful point of leverage for mitigating these distribution shifts, as it is frequently much more available than labeled data. However, existing distribution shift benchmarks for unlabeled data do not reflect the breadth of scenarios that arise in real-world applications. In this work, we present the WILDS 2.0 update, which extends 8 of the 10 datasets in the WILDS benchmark of distribution shifts to include curated unlabeled data that would be realistically obtainable in deployment. To maintain consistency, the labeled training, validation, and test sets, as well as the evaluation metrics, are exactly the same as in the original WILDS benchmark. These datasets span a wide range of applications (from histology to wildlife conservation), tasks (classification, regression, and detection), and modalities (photos, satellite images, microscope slides, text, molecular graphs). We systematically benchmark state-of-the-art methods that leverage unlabeled data, including domain-invariant, self-training, and self-supervised methods, and show that their success on WILDS 2.0 is limited. To facilitate method development and evaluation, we provide an open-source package that automates data loading and contains all of the model architectures and methods used in this paper. Code and leaderboards are available at https://wilds.stanford.edu.