 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextGNN: Beyond Two-Tower Recommendation Systems
Nov 29, 2024



Recommendation systems predominantly utilize two-tower architectures, which evaluate user-item rankings through the inner product of their respective embeddings. However, one key limitation of two-tower models is that they learn a pair-agnostic representation of users and items. In contrast, pair-wise representations either scale poorly due to their quadratic complexity or are too restrictive on the candidate pairs to rank. To address these issues, we introduce Context-based Graph Neural Networks (ContextGNNs), a novel deep learning architecture for link prediction in recommendation systems. The method employs a pair-wise representation technique for familiar items situated within a user's local subgraph, while leveraging two-tower representations to facilitate the recommendation of exploratory items. A final network then predicts how to fuse both pair-wise and two-tower recommendations into a single ranking of items. We demonstrate that ContextGNN is able to adapt to different data characteristics and outperforms existing methods, both traditional and GNN-based, on a diverse set of practical recommendation tasks, improving performance by 20% on average.
RelBench: A Benchmark for Deep Learning on Relational Databases
Jul 29, 2024



We present RelBench, a public benchmark for solving predictive tasks over relational databases with graph neural networks. RelBench provides databases and tasks spanning diverse domains and scales, and is intended to be a foundational infrastructure for future research. We use RelBench to conduct the first comprehensive study of Relational Deep Learning (RDL) (Fey et al., 2024), which combines graph neural network predictive models with (deep) tabular models that extract initial entity-level representations from raw tables. End-to-end learned RDL models fully exploit the predictive signal encoded in primary-foreign key links, marking a significant shift away from the dominant paradigm of manual feature engineering combined with tabular models. To thoroughly evaluate RDL against this prior gold-standard, we conduct an in-depth user study where an experienced data scientist manually engineers features for each task. In this study, RDL learns better models whilst reducing human work needed by more than an order of magnitude. This demonstrates the power of deep learning for solving predictive tasks over relational databases, opening up many new research opportunities enabled by RelBench.
From Similarity to Superiority: Channel Clustering for Time Series Forecasting
Mar 31, 2024



Time series forecasting has attracted significant attention in recent decades. Previous studies have demonstrated that the Channel-Independent (CI) strategy improves forecasting performance by treating different channels individually, while it leads to poor generalization on unseen instances and ignores potentially necessary interactions between channels. Conversely, the Channel-Dependent (CD) strategy mixes all channels with even irrelevant and indiscriminate information, which, however, results in oversmoothing issues and limits forecasting accuracy. There is a lack of channel strategy that effectively balances individual channel treatment for improved forecasting performance without overlooking essential interactions between channels. Motivated by our observation of a correlation between the time series model's performance boost against channel mixing and the intrinsic similarity on a pair of channels, we developed a novel and adaptable Channel Clustering Module (CCM). CCM dynamically groups channels characterized by intrinsic similarities and leverages cluster identity instead of channel identity, combining the best of CD and CI worlds. Extensive experiments on real-world datasets demonstrate that CCM can (1) boost the performance of CI and CD models by an average margin of 2.4% and 7.2% on long-term and short-term forecasting, respectively; (2) enable zero-shot forecasting with mainstream time series forecasting models; (3) uncover intrinsic time series patterns among channels and improve interpretability of complex time series models.
PyTorch Frame: A Modular Framework for Multi-Modal Tabular Learning
Mar 31, 2024



We present PyTorch Frame, a PyTorch-based framework for deep learning over multi-modal tabular data. PyTorch Frame makes tabular deep learning easy by providing a PyTorch-based data structure to handle complex tabular data, introducing a model abstraction to enable modular implementation of tabular models, and allowing external foundation models to be incorporated to handle complex columns (e.g., LLMs for text columns). We demonstrate the usefulness of PyTorch Frame by implementing diverse tabular models in a modular way, successfully applying these models to complex multi-modal tabular data, and integrating our framework with PyTorch Geometric, a PyTorch library for Graph Neural Networks (GNNs), to perform end-to-end learning over relational databases.
Relational Deep Learning: Graph Representation Learning on Relational Databases
Dec 07, 2023



Much of the world's most valued data is stored in relational databases and data warehouses, where the data is organized into many tables connected by primary-foreign key relations. However, building machine learning models using this data is both challenging and time consuming. The core problem is that no machine learning method is capable of learning on multiple tables interconnected by primary-foreign key relations. Current methods can only learn from a single table, so the data must first be manually joined and aggregated into a single training table, the process known as feature engineering. Feature engineering is slow, error prone and leads to suboptimal models. Here we introduce an end-to-end deep representation learning approach to directly learn on data laid out across multiple tables. We name our approach Relational Deep Learning (RDL). The core idea is to view relational databases as a temporal, heterogeneous graph, with a node for each row in each table, and edges specified by primary-foreign key links. Message Passing Graph Neural Networks can then automatically learn across the graph to extract representations that leverage all input data, without any manual feature engineering. Relational Deep Learning leads to more accurate models that can be built much faster. To facilitate research in this area, we develop RelBench, a set of benchmark datasets and an implementation of Relational Deep Learning. The data covers a wide spectrum, from discussions on Stack Exchange to book reviews on the Amazon Product Catalog. Overall, we define a new research area that generalizes graph machine learning and broadens its applicability to a wide set of AI use cases.
Temporal Graph Benchmark for Machine Learning on Temporal Graphs
Jul 03, 2023



We present the Temporal Graph Benchmark (TGB), a collection of challenging and diverse benchmark datasets for realistic, reproducible, and robust evaluation of machine learning models on temporal graphs. TGB datasets are of large scale, spanning years in duration, incorporate both node and edge-level prediction tasks and cover a diverse set of domains including social, trade, transaction, and transportation networks. For both tasks, we design evaluation protocols based on realistic use-cases. We extensively benchmark each dataset and find that the performance of common models can vary drastically across datasets. In addition, on dynamic node property prediction tasks, we show that simple methods often achieve superior performance compared to existing temporal graph models. We believe that these findings open up opportunities for future research on temporal graphs. Finally, TGB provides an automated machine learning pipeline for reproducible and accessible temporal graph research, including data loading, experiment setup and performance evaluation. TGB will be maintained and updated on a regular basis and welcomes community feedback. TGB datasets, data loaders, example codes, evaluation setup, and leaderboards are publicly available at https://tgb.complexdatalab.com/ .
GraphCast: Learning skillful medium-range global weather forecasting
Dec 24, 2022



We introduce a machine-learning (ML)-based weather simulator--called "GraphCast"--which outperforms the most accurate deterministic operational medium-range weather forecasting system in the world, as well as all previous ML baselines. GraphCast is an autoregressive model, based on graph neural networks and a novel high-resolution multi-scale mesh representation, which we trained on historical weather data from the European Centre for Medium-Range Weather Forecasts (ECMWF)'s ERA5 reanalysis archive. It can make 10-day forecasts, at 6-hour time intervals, of five surface variables and six atmospheric variables, each at 37 vertical pressure levels, on a 0.25-degree latitude-longitude grid, which corresponds to roughly 25 x 25 kilometer resolution at the equator. Our results show GraphCast is more accurate than ECMWF's deterministic operational forecasting system, HRES, on 90.0% of the 2760 variable and lead time combinations we evaluated. GraphCast also outperforms the most accurate previous ML-based weather forecasting model on 99.2% of the 252 targets it reported. GraphCast can generate a 10-day forecast (35 gigabytes of data) in under 60 seconds on Cloud TPU v4 hardware. Unlike traditional forecasting methods, ML-based forecasting scales well with data: by training on bigger, higher quality, and more recent data, the skill of the forecasts can improve. Together these results represent a key step forward in complementing and improving weather modeling with ML, open new opportunities for fast, accurate forecasting, and help realize the promise of ML-based simulation in the physical sciences.
TuneUp: A Training Strategy for Improving Generalization of Graph Neural Networks
Oct 26, 2022



Despite many advances in Graph Neural Networks (GNNs), their training strategies simply focus on minimizing a loss over nodes in a graph. However, such simplistic training strategies may be sub-optimal as they neglect that certain nodes are much harder to make accurate predictions on than others. Here we present TuneUp, a curriculum learning strategy for better training GNNs. Crucially, TuneUp trains a GNN in two stages. The first stage aims to produce a strong base GNN. Such base GNNs tend to perform well on head nodes (nodes with large degrees) but less so on tail nodes (nodes with small degrees). So, the second stage of TuneUp specifically focuses on improving prediction on tail nodes. Concretely, TuneUp synthesizes many additional supervised tail node data by dropping edges from head nodes and reusing the supervision on the original head nodes. TuneUp then minimizes the loss over the synthetic tail nodes to finetune the base GNN. TuneUp is a general training strategy that can be used with any GNN architecture and any loss, making TuneUp applicable to a wide range of prediction tasks. Extensive evaluation of TuneUp on two GNN architectures, three types of prediction tasks, and both inductive and transductive settings shows that TuneUp significantly improves the performance of the base GNN on tail nodes, while often even improving the performance on head nodes, which together leads up to 58.5% relative improvement in GNN predictive performance. Moreover, TuneUp significantly outperforms its variants without the two-stage curriculum learning, existing graph data augmentation techniques, as well as other specialized methods for tail nodes.
Learning Backward Compatible Embeddings
Jun 07, 2022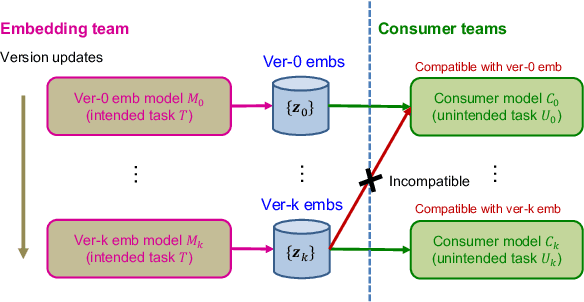
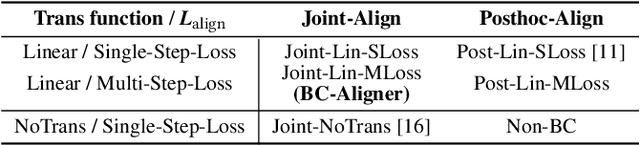
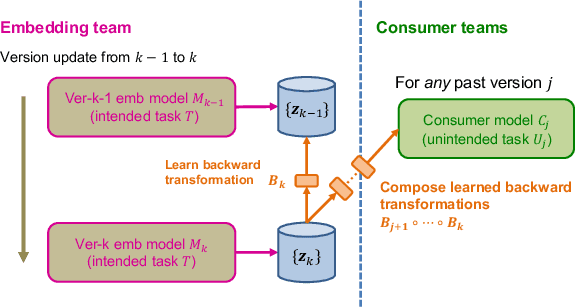

Embeddings, low-dimensional vector representation of objects, are fundamental in building modern machine learning systems. In industrial settings, there is usually an embedding team that trains an embedding model to solve intended tasks (e.g., product recommendation). The produced embeddings are then widely consumed by consumer teams to solve their unintended tasks (e.g., fraud detection). However, as the embedding model gets updated and retrained to improve performance on the intended task, the newly-generated embeddings are no longer compatible with the existing consumer models. This means that historical versions of the embeddings can never be retired or all consumer teams have to retrain their models to make them compatible with the latest version of the embeddings, both of which are extremely costly in practice. Here we study the problem of embedding version updates and their backward compatibility. We formalize the problem where the goal is for the embedding team to keep updating the embedding version, while the consumer teams do not have to retrain their models. We develop a solution based on learning backward compatible embeddings, which allows the embedding model version to be updated frequently, while also allowing the latest version of the embedding to be quickly transformed into any backward compatible historical version of it, so that consumer teams do not have to retrain their models. Under our framework, we explore six methods and systematically evaluate them on a real-world recommender system application. We show that the best method, which we call BC-Aligner, maintains backward compatibility with existing unintended tasks even after multiple model version updates. Simultaneously, BC-Aligner achieves the intended task performance similar to the embedding model that is solely optimized for the intended task.
Extending the WILDS Benchmark for Unsupervised Adaptation
Dec 09, 2021

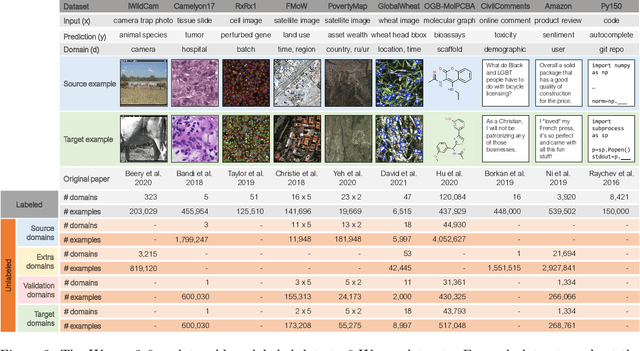
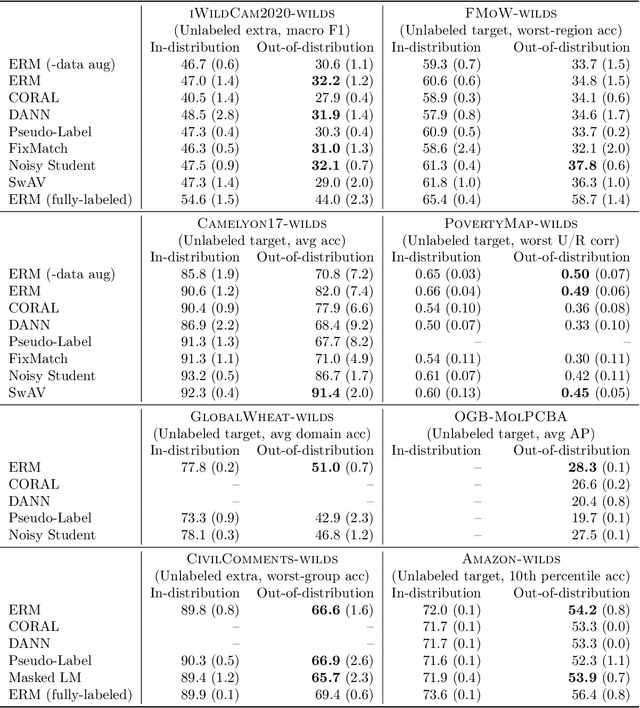
Machine learning systems deployed in the wild are often trained on a source distribution but deployed on a different target distribution. Unlabeled data can be a powerful point of leverage for mitigating these distribution shifts, as it is frequently much more available than labeled data. However, existing distribution shift benchmarks for unlabeled data do not reflect the breadth of scenarios that arise in real-world applications. In this work, we present the WILDS 2.0 update, which extends 8 of the 10 datasets in the WILDS benchmark of distribution shifts to include curated unlabeled data that would be realistically obtainable in deployment. To maintain consistency, the labeled training, validation, and test sets, as well as the evaluation metrics, are exactly the same as in the original WILDS benchmark. These datasets span a wide range of applications (from histology to wildlife conservation), tasks (classification, regression, and detection), and modalities (photos, satellite images, microscope slides, text, molecular graphs). We systematically benchmark state-of-the-art methods that leverage unlabeled data, including domain-invariant, self-training, and self-supervised methods, and show that their success on WILDS 2.0 is limited. To facilitate method development and evaluation, we provide an open-source package that automates data loading and contains all of the model architectures and methods used in this paper. Code and leaderboards are available at https://wilds.stanford.edu.